题目描述
某收费有线电视网计划转播一场重要的足球比赛。他们的转播网和用户终端构成一棵树状结构,这棵树的根结点位于足球比赛的现场,树叶为各个用户终端,其他中转站为该树的内部节点。
从转播站到转播站以及从转播站到所有用户终端的信号传输费用都是已知的,一场转播的总费用等于传输信号的费用总和。
现在每个用户都准备了一笔费用想观看这场精彩的足球比赛,有线电视网有权决定给哪些用户提供信号而不给哪些用户提供信号。
写一个程序找出一个方案使得有线电视网在不亏本的情况下使观看转播的用户尽可能多。
输入输出格式
输入格式:
输入文件的第一行包含两个用空格隔开的整数N和M,其中2≤N≤3000,1≤M≤N-1,N为整个有线电视网的结点总数,M为用户终端的数量。
第一个转播站即树的根结点编号为1,其他的转播站编号为2到N-M,用户终端编号为N-M+1到N。
接下来的N-M行每行表示—个转播站的数据,第i+1行表示第i个转播站的数据,其格式如下:
K A1 C1 A2 C2 … Ak Ck
K表示该转播站下接K个结点(转播站或用户),每个结点对应一对整数A与C,A表示结点编号,C表示从当前转播站传输信号到结点A的费用。最后一行依次表示所有用户为观看比赛而准备支付的钱数。
输出格式:
输出文件仅一行,包含一个整数,表示上述问题所要求的最大用户数。
输入输出样例
5 3 2 2 2 5 3 2 3 2 4 3 3 4 2
2
样例解释
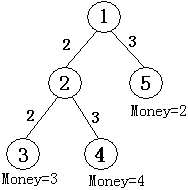
如图所示,共有五个结点。结点①为根结点,即现场直播站,②为一个中转站,③④⑤为用户端,共M个,编号从N-M+1到N,他们为观看比赛分别准备的钱数为3、4、2,从结点①可以传送信号到结点②,费用为2,也可以传送信号到结点⑤,费用为3(第二行数据所示),从结点②可以传输信号到结点③,费用为2。也可传输信号到结点④,费用为3(第三行数据所示),如果要让所有用户(③④⑤)都能看上比赛,则信号传输的总费用为:
2+3+2+3=10,大于用户愿意支付的总费用3+4+2=9,有线电视网就亏本了,而只让③④两个用户看比赛就不亏本了。
解析
树形dp:
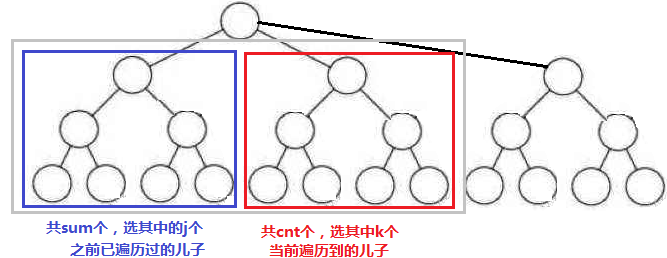
dp[u][j]:代表以u为根,选其子树j个用户的最大收益
这里需要记录遍历过的总用户数sum,和当前儿子子树的总用户数cnt
所以dp[u][j]应该是用u所有儿子v选择各自子树产生j个用户来更新
#include<bits/stdc++.h>
using namespace std;
#define maxn 3010
typedef long long ll;
#define inf 0x3fffffff
#define ri register int
#define getchar() (Ss==Tt&&(Tt=(Ss=BB)+fread(BB,1,1<<15,stdin),Ss==Tt)?EOF:*Ss++)
char BB[1 << 18], *Ss = BB, *Tt = BB;
inline int read()
{
int x=0;
int ch=getchar(),f=1;
while (!isdigit(ch)&&(ch!='-')&&(ch!=EOF)) ch=getchar();
if (ch=='-')
{
f=-1;
ch=getchar();
}
while (isdigit(ch))
{
x=(x<<1)+(x<<3)+ch-'0';
ch=getchar();
}
return x*f;
}
int n,m;
int tot=0;
int dp[maxn][maxn];
int val[maxn];
int head[maxn];
int t[maxn];
struct e
{
int to,w,next;
} e[maxn];
void init(int u,int v,int w)
{
tot++;
e[tot].to=v;
e[tot].w=w;
e[tot].next=head[u];
head[u]=tot;
}
int dfs(int u)
{
if(u>n-m)
{
dp[u][1]=val[u];
return 1;
}
int sum=0;
for(int p=head[u]; p; p=e[p].next)
{
int v=e[p].to;
int cnt=dfs(v);
for(int i=0; i<=sum; i++)t[i]=dp[u][i];//这里需要保留原先的结果,防止被下面更新
for(int j=0; j<=sum; j++)
for(int k=0; k<=cnt; k++)
dp[u][j+k]=max(dp[u][j+k],t[j]+dp[v][k]-e[p].w);
sum+=cnt;
}
return sum;
}
int main()
{
freopen("test.txt","r",stdin);
n=read(),m=read();
memset(dp,~0x3f,sizeof(dp));
for(int u=1; u<=n-m; u++)
{
int size=read();
for(int j=1; j<=size; j++)
{
int v=read(),w=read();
init(u,v,w);
}
}
for(int i=n-m+1; i<=n; i++)
val[i]=read();
for(int i=1; i<=n; i++)
dp[i][0]=0;
dfs(1);
for(int i=m; i>=1; i--)
if(dp[1][i]>=0)
{
cout<<i;
break;
}
return 0;
}