在项目中,写的sql主要以查询为主,但是数据量一大,就会突出sql性能优化的重要性。其实在数据量2000W以内,可以考虑索引,但超过2000W了,就要考虑分库分表这些了。本文主要记录在实际项目中,一个需要查询很慢的sql的优化过程,如果有更好的方案,请在下面留言交流。
很多文章都有关于sql优化的方法,这里就不一一陈述了。如果有需要可以查看博客:https://blog.csdn.net/linhaiyun_ytdx/article/details/79101122
SELECT T.YHBH, (SELECT NAME FROM DIM_REGION WHERE CODE = SUBSTR(T.GDDWBM, 0, 4)) GDDWMC, (SELECT NAME FROM DIM_REGION WHERE CODE = T.GDDWBM) FJMC, T.DFNY, T.YHMC, T.YDDZ, (SELECT NAME FROM DIM_ELECTRICITY_TYPE WHERE CODE = T.YHLBDM) YDLBMC FROM (SELECT DISTINCT T.YHBH, DECODE(T.GDDWBM, NULL, '0000', DECODE(T.GDDWBM, '09', '0000', T.GDDWBM)) AS GDDWBM, T.BBNY AS DFNY, T.YHLBDM AS YHLBDM, T.YHMC, T2.YDDZ FROM V_TEMP_TABLE_JHCBHSTJ_HISTORY T, TMP_KH_YDKH T2 WHERE T.YHBH = T2.YHBH(+) AND NOT EXISTS (SELECT 1 FROM DJHJSL_LSB_FZ_HISTORY B WHERE B.BBNY = T.BBNY AND B.YHBH = T.YHBH AND B.GDDWBM = T.GDDWBM AND B.YHLBDM = T.YHLBDM AND B.ZDCBZHS <> '0') ) T WHERE SUBSTR(T.GDDWBM, 0, 4) = '0946' AND T.DFNY = '201911'
这个是我的sql脚本。其实这个脚本一点都不复杂。其中V_TEMP_TABLE_JHCBHSTJ_HISTORY,DJHJSL_LSB_FZ_HISTORY每个月增加330万,目前有1960多万, TMP_KH_YDKH表有330多万。DIM_REGION 和DIM_ELECTRICITY_TYPE 是两个数据字典项表。
在没有索引的情况下,这个脚本执行需要30s,看到执行过程,现在都是全表扫描的。接下来开始优化。
1.修改脚本的查询,将外层的查询条件放到里面,减少数据量。
SELECT T.YHBH, (SELECT NAME FROM DIM_REGION WHERE CODE = SUBSTR(T.GDDWBM, 0, 4)) GDDWMC, (SELECT NAME FROM DIM_REGION WHERE CODE = T.GDDWBM) FJMC, T.DFNY, T.YHMC, T.YDDZ, (SELECT NAME FROM DIM_ELECTRICITY_TYPE WHERE CODE = T.YHLBDM) YDLBMC FROM (SELECT DISTINCT T.YHBH, DECODE(T.GDDWBM, NULL, '0000', DECODE(T.GDDWBM, '09', '0000', T.GDDWBM)) AS GDDWBM, T.BBNY AS DFNY, T.YHLBDM AS YHLBDM, T.YHMC, T2.YDDZ FROM V_TEMP_TABLE_JHCBHSTJ_HISTORY T, TMP_KH_YDKH T2 WHERE T.YHBH = T2.YHBH(+) AND NOT EXISTS (SELECT 1 FROM DJHJSL_LSB_FZ_HISTORY B WHERE B.BBNY = T.BBNY AND B.YHBH = T.YHBH AND B.GDDWBM = T.GDDWBM AND B.YHLBDM = T.YHLBDM AND B.ZDCBZHS <> '0') AND SUBSTR(T.GDDWBM, 0, 4) = '0946' AND T.BBNY = '201911' ) T
2.对三个表都建上索引
对V_TEMP_TABLE_JHCBHSTJ_HISTORY根据DFNY,SUBSTR(T.GDDWBM, 0, 4)建上联合索引。
CREATE INDEX IDX_TMP_JHCBHSTJ_HISTORY_UNION ON V_TEMP_TABLE_JHCBHSTJ_HISTORY(BBNY,SUBSTR(GDDWBM, 0, 4));
对TMP_KH_YDKH表,使用了关联,所以需要对yhbh建个索引
create index IDX_YHBH_KH on TMP_KH_YDKH (YHBH);
对于DJHJSL_LSB_FZ_HISTORY表,在not EXISTS里面,会全表扫描这个表,现在对他建立联合索引试试。
CREATE INDEX IDX_DJHJSL_FZ_HISTORY_UNION ON V_TEMP_TABLE_JHCBHSTJ_HISTORY(BBNY,YHBH,GDDWBM,YHLBDM);

查看oracle的执行计划,建立联合索引,并没有让这个表走索引,还是在全表扫描的,但是查询已经提升到9s了。
接下来对分别对这四个字段建立索引:
create index IDX_DJHJSL_FZ_HISTORY_BBNY on DJHJSL_LSB_FZ_HISTORY (BBNY); create index IDX_DJHJSL_FZ_HISTORY_YHBH on DJHJSL_LSB_FZ_HISTORY (YHBH); create index IDX_DJHJSL_FZ_HISTORY_GDDWBM on DJHJSL_LSB_FZ_HISTORY (GDDWBM); create index IDX_DJHJSL_FZ_HISTORY_YHLBDM on DJHJSL_LSB_FZ_HISTORY (YHLBDM);
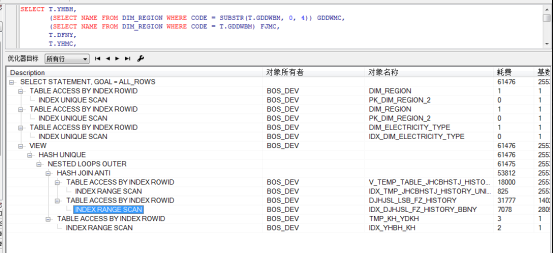
从执行计划来看,oracle只走了IDX_DJHJSL_FZ_HISTORY_BBNY这个索引,现在最快已经到1.95s了。
虽然现在已经满足了查询3s内的要求,但是考虑到以后,每个月的数据增长,数据量有5000万,一亿这样的大数据量的时候还是会很慢。
其实我在正式环境测试的时候,NOT EXISTS 里面的这个表,建立单个索引是没有用的,建立联合索引才会使这个表走索引,可能是因为电脑的cpu不同等因素影响的。
上面的优化方法当然不能满足项目的需求,接下来结合业务进行优化。作为一个监控系统,数据是T+1的,不需要追求实时性,这些数据,都是使用etl抽取工具每天定时抽取的。而且每个月300万数据,用户只关注的只有几千条。所以结合业务,我们在使用etl抽取完数据后,将用户关注的数据插入到另一张表中,这样,每个月只有几千条数据,这样的话,一年也才几万条数据,对oracle来说决定是零压力的。
-----------------------------------------------------我是分界线---------------------------------------------------------
2020年5月1日更新:前一天我有点空闲时间,想起来对这个sql再做一次优化(经过几个月的增长,已经有了4000万的数据,就算上面的那个脚本查询还有有点慢),因为我们的表数据是按月插入的,客户查询也是按月查询的,所以我就对 V_TEMP_TABLE_JHCBHSTJ_HISTORY,DJHJSL_LSB_FZ_HISTORY 这两个月进行了按月分区(列表分区)。
下面是执行脚本(我这里没有建默认分区,在项目中一定要建立默认分区):
-- Create table 分母 create TABLE JHCBHSTJ_HISTORY1 ( BBNY VARCHAR2(6), BBNYR VARCHAR2(8), GDDWBM VARCHAR2(20), YHLBDM VARCHAR2(20), DYLBBM VARCHAR2(20), YHBH VARCHAR2(50), YHMC VARCHAR2(200), DYJHCBKHS NUMBER(10) ) partition by LIST(BBNY) ( partition P_JHCBHSTJ_HISTORY_201905 values ('201905'), partition P_JHCBHSTJ_HISTORY_201906 values ('201906'), partition P_JHCBHSTJ_HISTORY_201907 values ('201907'), partition P_JHCBHSTJ_HISTORY_201908 values ('201908'), partition P_JHCBHSTJ_HISTORY_201909 values ('201909'), partition P_JHCBHSTJ_HISTORY_201910 values ('201910'), partition P_JHCBHSTJ_HISTORY_201911 values ('201911'), partition P_JHCBHSTJ_HISTORY_201912 values ('201912'), partition P_JHCBHSTJ_HISTORY_202001 values ('202001'), partition P_JHCBHSTJ_HISTORY_202002 values ('202002'), partition P_JHCBHSTJ_HISTORY_202003 values ('202003'), partition P_JHCBHSTJ_HISTORY_202004 values ('202004'), partition P_JHCBHSTJ_HISTORY_202005 values ('202005'), partition P_JHCBHSTJ_HISTORY_202006 values ('202006'), partition P_JHCBHSTJ_HISTORY_202007 values ('202007'), partition P_JHCBHSTJ_HISTORY_202008 values ('202008'), partition P_JHCBHSTJ_HISTORY_202009 values ('202009'), partition P_JHCBHSTJ_HISTORY_202010 values ('202010'), partition P_JHCBHSTJ_HISTORY_202011 values ('202011'), partition P_JHCBHSTJ_HISTORY_202012 values ('202012'), partition P_JHCBHSTJ_HISTORY_202101 values ('202101'), partition P_JHCBHSTJ_HISTORY_202102 values ('202102'), partition P_JHCBHSTJ_HISTORY_202103 values ('202103'), partition P_JHCBHSTJ_HISTORY_202104 values ('202104'), partition P_JHCBHSTJ_HISTORY_202105 values ('202105'), partition P_JHCBHSTJ_HISTORY_202106 values ('202106'), partition P_JHCBHSTJ_HISTORY_202107 values ('202107'), partition P_JHCBHSTJ_HISTORY_202108 values ('202108'), partition P_JHCBHSTJ_HISTORY_202109 values ('202109'), partition P_JHCBHSTJ_HISTORY_202110 values ('202110'), partition P_JHCBHSTJ_HISTORY_202111 values ('202111'), partition P_JHCBHSTJ_HISTORY_202112 values ('202112') );; ALTER SESSION ENABLE PARALLEL DML; --插入数据 (采用并发,依据服务器性能和核数而定) INSERT /*+PARALLEL(JHCBHSTJ_HISTORY1,30)*/ INTO JHCBHSTJ_HISTORY1 SELECT /*+PARALLEL(V_TEMP_TABLE_JHCBHSTJ_HISTORY,30)*/ * FROM V_TEMP_TABLE_JHCBHSTJ_HISTORY; COMMIT; --替换之前的表 RENAME V_TEMP_TABLE_JHCBHSTJ_HISTORY TO JHCBHSTJ_HISTORY_BAK; RENAME JHCBHSTJ_HISTORY1 TO V_TEMP_TABLE_JHCBHSTJ_HISTORY;
-- Create table 分子 create table DJHJSL_LSB_FZ_HISTORY_1 ( BBNY VARCHAR2(6), BBNYR VARCHAR2(8), GDDWBM VARCHAR2(20), YHLBDM VARCHAR2(20), DYLBBM VARCHAR2(20), YHBH VARCHAR2(50), YHMC VARCHAR2(200), ZDCBZHS NUMBER(10) ) partition by LIST(BBNY) ( partition P_DJHJSL_LSB_FZ_HISTORY_201905 values ('201905'), partition P_DJHJSL_LSB_FZ_HISTORY_201906 values ('201906'), partition P_DJHJSL_LSB_FZ_HISTORY_201907 values ('201907'), partition P_DJHJSL_LSB_FZ_HISTORY_201908 values ('201908'), partition P_DJHJSL_LSB_FZ_HISTORY_201909 values ('201909'), partition P_DJHJSL_LSB_FZ_HISTORY_201910 values ('201910'), partition P_DJHJSL_LSB_FZ_HISTORY_201911 values ('201911'), partition P_DJHJSL_LSB_FZ_HISTORY_201912 values ('201912'), partition P_DJHJSL_LSB_FZ_HISTORY_202001 values ('202001'), partition P_DJHJSL_LSB_FZ_HISTORY_202002 values ('202002'), partition P_DJHJSL_LSB_FZ_HISTORY_202003 values ('202003'), partition P_DJHJSL_LSB_FZ_HISTORY_202004 values ('202004'), partition P_DJHJSL_LSB_FZ_HISTORY_202005 values ('202005'), partition P_DJHJSL_LSB_FZ_HISTORY_202006 values ('202006'), partition P_DJHJSL_LSB_FZ_HISTORY_202007 values ('202007'), partition P_DJHJSL_LSB_FZ_HISTORY_202008 values ('202008'), partition P_DJHJSL_LSB_FZ_HISTORY_202009 values ('202009'), partition P_DJHJSL_LSB_FZ_HISTORY_202010 values ('202010'), partition P_DJHJSL_LSB_FZ_HISTORY_202011 values ('202011'), partition P_DJHJSL_LSB_FZ_HISTORY_202012 values ('202012'), partition P_DJHJSL_LSB_FZ_HISTORY_202101 values ('202101'), partition P_DJHJSL_LSB_FZ_HISTORY_202102 values ('202102'), partition P_DJHJSL_LSB_FZ_HISTORY_202103 values ('202103'), partition P_DJHJSL_LSB_FZ_HISTORY_202104 values ('202104'), partition P_DJHJSL_LSB_FZ_HISTORY_202105 values ('202105'), partition P_DJHJSL_LSB_FZ_HISTORY_202106 values ('202106'), partition P_DJHJSL_LSB_FZ_HISTORY_202107 values ('202107'), partition P_DJHJSL_LSB_FZ_HISTORY_202108 values ('202108'), partition P_DJHJSL_LSB_FZ_HISTORY_202109 values ('202109'), partition P_DJHJSL_LSB_FZ_HISTORY_202110 values ('202110'), partition P_DJHJSL_LSB_FZ_HISTORY_202111 values ('202111'), partition P_DJHJSL_LSB_FZ_HISTORY_202112 values ('202112') );; ALTER SESSION ENABLE PARALLEL DML; --插入数据 (采用并发,依据服务器性能和核数而定) INSERT /*+PARALLEL(DJHJSL_LSB_FZ_HISTORY_1,30)*/ INTO DJHJSL_LSB_FZ_HISTORY_1 SELECT /*+PARALLEL(DJHJSL_LSB_FZ_HISTORY,30)*/ * FROM DJHJSL_LSB_FZ_HISTORY; COMMIT; -- Create/Recreate indexes create index IDX_DJHJSL_FZ_HISTORY_UNION1 on DJHJSL_LSB_FZ_HISTORY_1 (BBNY, YHBH, GDDWBM, YHLBDM); --替换之前的表 RENAME DJHJSL_LSB_FZ_HISTORY TO DJHJSL_LSB_FZ_HISTORY_bak; RENAME DJHJSL_LSB_FZ_HISTORY_1 TO DJHJSL_LSB_FZ_HISTORY;
同时在两个表插入完成之后,对两个表收集了执行信息:
--收集执行信息 EXEC DBMS_STATS.gather_table_stats(user,'V_TEMP_TABLE_JHCBHSTJ_HISTORY',cascade=>true); --收集执行信息 EXEC DBMS_STATS.gather_table_stats(user,'DJHJSL_LSB_FZ_HISTORY',cascade=>true);
这样我在执行查询的时候,下面的图可以看到效果,性能提升还是很大的。
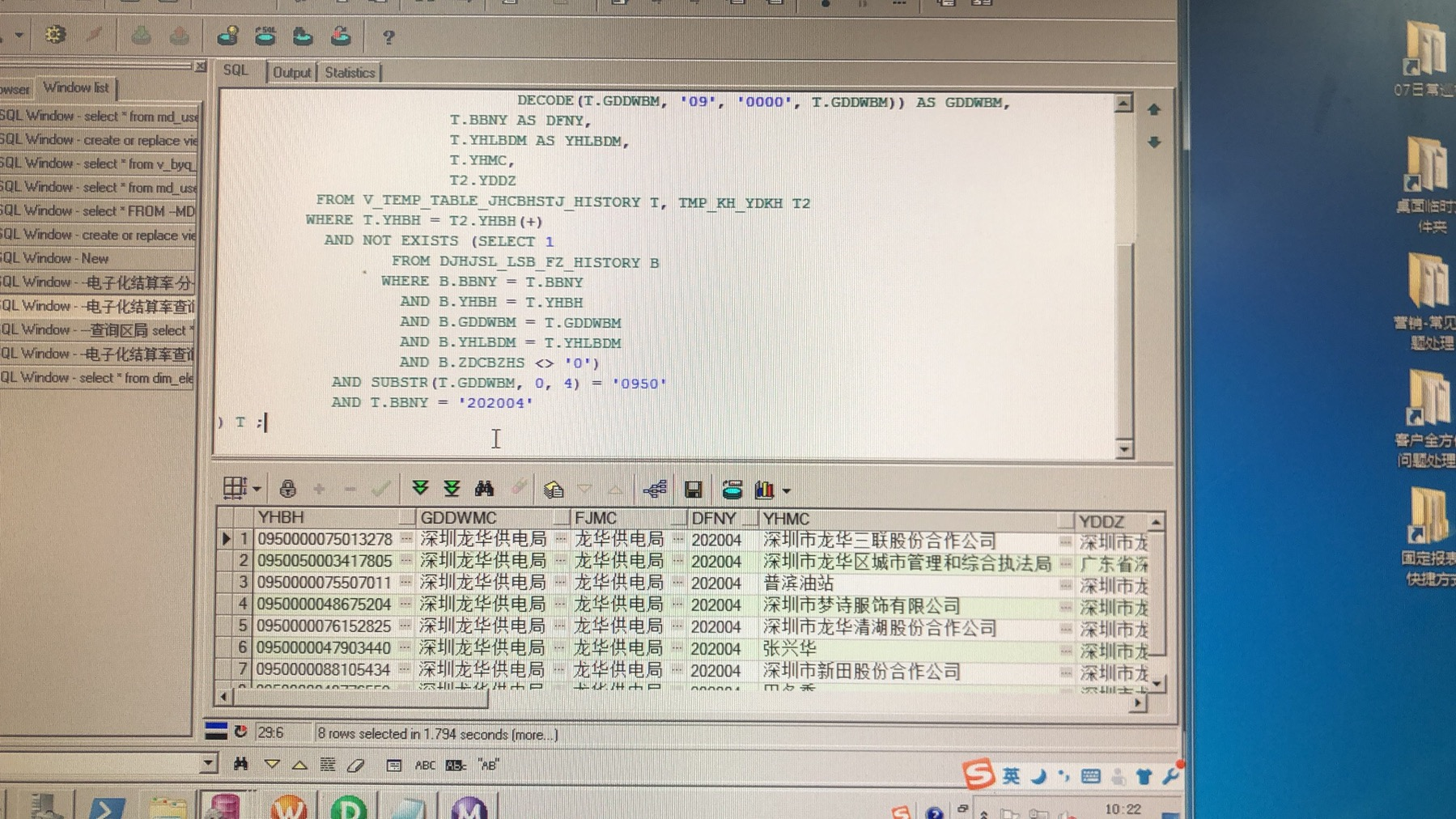
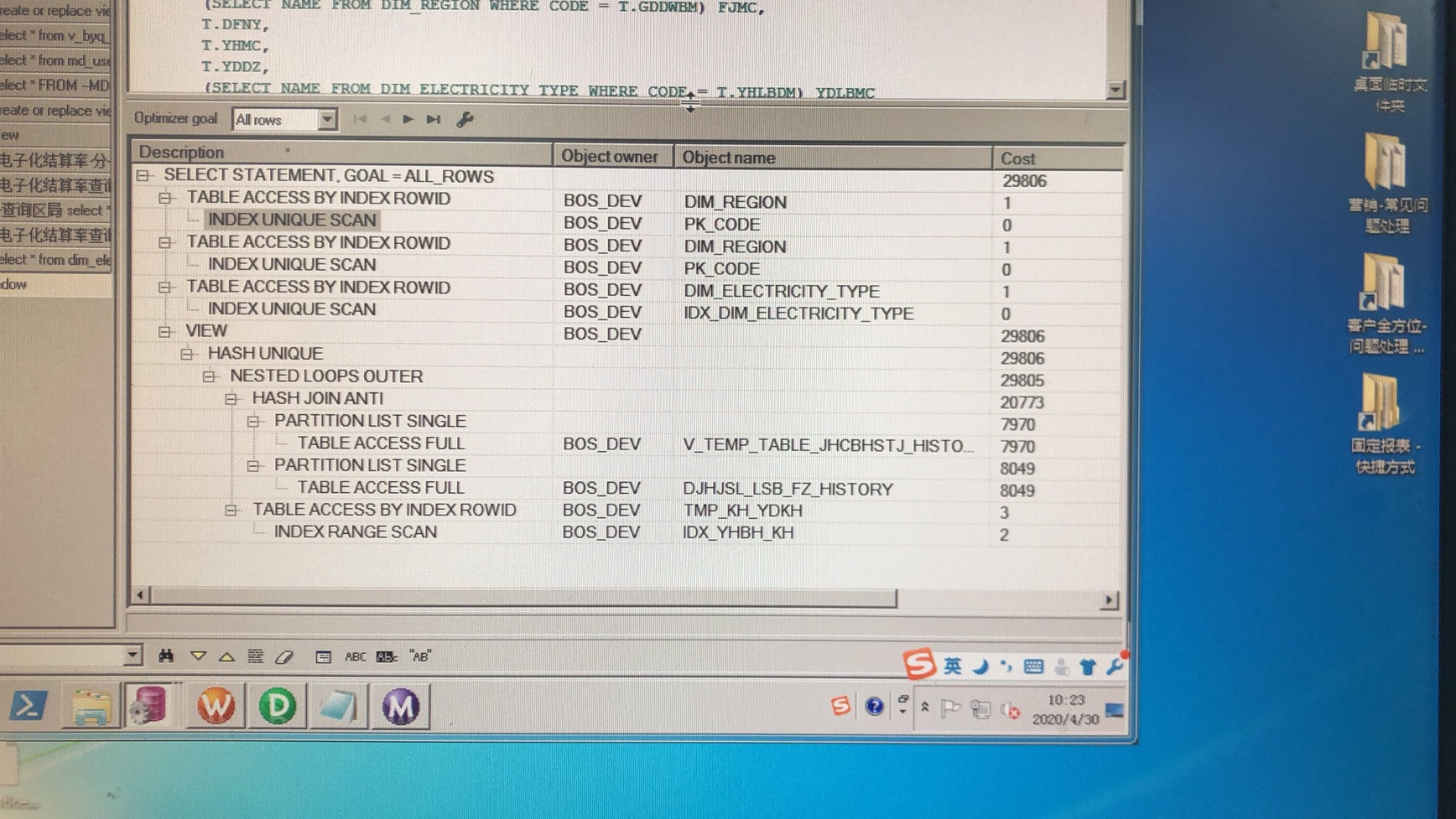
如果大家还有其他的方式优化,请在下方留言交流。