最近做项目的过程中用到了并查集的小知识,惭愧的是,我知道有这个数据结构,但是一时还想不起来她叫什么名字了,后来查找并自己实现了一下,发到这里来,以备后患!
不过,要讲一下并查集是怎么回事的话,需要用到一些图片啊什么,我去网上找了一下,发现Cherish_yimi写的很好,我就直接将它的说明拿过来了,更加详细的可以去看看她的博客,里面有它实现的代码,挺好的!
以下是他解释的部分,我就偷懒了
并查集学习:
l 并查集:(union-find sets)
一种简单的用途广泛的集合. 并查集是若干个不相交集合,能够实现较快的合并和判断元素所在集合的操作,应用很多,如其求无向图的连通分量个数等。最完美的应用当属:实现Kruskar算法求最小生成树。
l 并查集的精髓(即它的三种操作,结合实现代码模板进行理解):
1、Make_Set(x) 把每一个元素初始化为一个集合
初始化后每一个元素的父亲节点是它本身,每一个元素的祖先节点也是它本身(也可以根据情况而变)。
2、Find_Set(x) 查找一个元素所在的集合
查找一个元素所在的集合,其精髓是找到这个元素所在集合的祖先!这个才是并查集判断和合并的最终依据。
判断两个元素是否属于同一集合,只要看他们所在集合的祖先是否相同即可。
合并两个集合,也是使一个集合的祖先成为另一个集合的祖先,具体见示意图
3、Union(x,y) 合并x,y所在的两个集合
合并两个不相交集合操作很简单:
利用Find_Set找到其中两个集合的祖先,将一个集合的祖先指向另一个集合的祖先。如图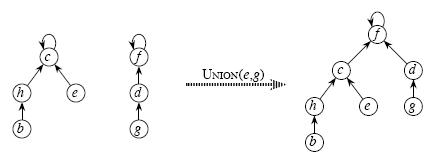
l 并查集的优化
1、Find_Set(x)时 路径压缩
寻找祖先时我们一般采用递归查找,但是当元素很多亦或是整棵树变为一条链时,每次Find_Set(x)都是O(n)的复杂度,有没有办法减小这个复杂度呢?
答案是肯定的,这就是路径压缩,即当我们经过"递推"找到祖先节点后,"回溯"的时候顺便将它的子孙节点都直接指向祖先,这样以后再次Find_Set(x)时复杂度就变成O(1)了,如下图所示;可见,路径压缩方便了以后的查找。
2、Union(x,y)时 按秩合并
即合并的时候将元素少的集合合并到元素多的集合中,这样合并之后树的高度会相对较小。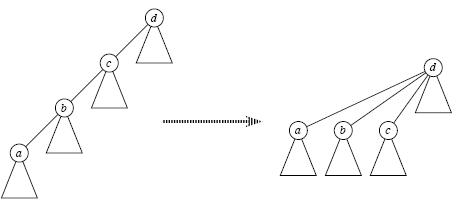
附上我自己实现的代码,代码里面讲得很清楚,所以在这里也不多说了!
 View Code
View Code

using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace Pmars
{
class PmarsTest
{
//union-find sets
public static void TestUFS()
{
///之所以建立这两个数据结构是因为,平常的应用都是字符串的形式的,
///在做算法的时候我们通常用到的都是int[],但是它并不适用于项目中
Dictionary<string, int> dic = new Dictionary<string, int>();
List<UFSNode> list = new List<UFSNode>();
string input = string.Empty;
///while循环不断的输入数据,进行并查运算,当输入为空时,跳出循环
while (!string.IsNullOrEmpty(input = Console.ReadLine()))
{
///用空格来分割字符串
string[] parts = input.Split(' ');
///如果是一个字符串的话,输入的意思就是 如果以前没有输入过这个字符串的话,那么他独自是一个分类
if (parts.Length == 1)
{
///以前没有输入过这个分类,那么将其输入到数组里面
if (!dic.ContainsKey(input))
{
///将input加入到数组里面去
AddOne(input, dic, list);
}
}
else
{
///从1开始,因为一会需要用到parts[0]合并他们
for (int i = 1; i < parts.Length; ++i)
{
///将两个数据加入到数组里面去,并且合并为一个结合
AddTwo(parts[0], parts[i], dic, list);
}
}
///聚合分类,将同一个集合的名字放到一个list里面
Dictionary<int, List<UFSNode>> unionDic = new Dictionary<int, List<UFSNode>>();
list.ForEach(value =>
{
int parentNum = FindParent(value, dic, list);
if (!unionDic.ContainsKey(parentNum))
unionDic.Add(parentNum, new List<UFSNode>());
unionDic[parentNum].Add(value);
});
///将每个集合打印出来,查看聚合情况
foreach (var key in unionDic)
{
Console.WriteLine(key.Key);
foreach (var value in key.Value)
Console.Write(value.name + "\t");
Console.WriteLine();
}
}
}
private static UFSNode AddOne(string input,Dictionary<string,int> dic,List<UFSNode> list)
{
///list.Count 标示input在list中的位置,因为是单线程,所以可以这么做
dic.Add(input, list.Count);
list.Add(new UFSNode
{
name = input,
///在这里做了一个尝试,也记录在这里吧
///在list加入数据的时候使用list.Count会返回加入数据以前的list长度
///parentNum = list.Count
///但是,保险的方式还是用
parentNum = dic[input]
});
return list[dic[input]];
}
///加入两个字符串到数组中,标示他们两个是一个类别的
private static void AddTwo(string part1, string part2, Dictionary<string, int> dic, List<UFSNode> list)
{
UFSNode node1, node2;
if (!dic.ContainsKey(part1))
///如果字典中没有,说明list中也没有,需要加进来
node1 = AddOne(part1, dic, list);
else
///有的话,直接取出来
node1 = list[dic[part1]];
if (!dic.ContainsKey(part2))
///如果字典中没有,说明list中也没有,需要加进来
node2 = AddOne(part2, dic, list);
else
///有的话,直接取出来
node2 = list[dic[part2]];
///找到两个节点的父亲编号
int num1 = FindParent(node1, dic, list);
int num2 = FindParent(node2, dic, list);
///如果他们现在不是一个集合的,那么给他们归并到一个集合中去
if (num1 != num2)
Union(node1, num2, dic, list);
}
private static void Union(UFSNode node, int parentNum, Dictionary<string, int> dic, List<UFSNode> list)
{
//并 函数,将它和它的父亲所有的节点都指向需要合并的父亲节点编号
if (node.parentNum != dic[node.name])
Union(list[node.parentNum], parentNum, dic, list);
node.parentNum = parentNum;
}
private static int FindParent(UFSNode node, Dictionary<string, int> dic, List<UFSNode> list)
{
///查 函数,记得第一次看到这样来写并查集的时候,内心非常的冲动,那个时候还在玩ACM吧,呵呵
if (node.parentNum != dic[node.name])
node.parentNum = FindParent(list[node.parentNum], dic, list);
return node.parentNum;
}
private class UFSNode
{
public string name;
public int parentNum;
}
}
}
记在这里,分享给大家!