---恢复内容开始---
算法步骤:
1.计算用户相似度
2.对于特定用户,选出k个最相似的用户,将这些用户评价过的前k好的物品推荐给该用户
用户相似度 度量:
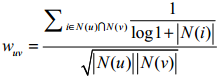
其中|N(u)|表示用户u评价过的物品的数量,|N(i)|为物品i的流行度,即物品i被多少用户评价过
这里物品流行度越高,它在相似度的度量上作用越小(两人都买了《新华字典》,并不是因为喜好)
实现:
1.先获取每个物品 对应的 对其进行评价的用户的列表 iu
如:商品A --- [用户2,用户3,用户4]
商品B --- [用户1,用户5,用户2]
def item_user(self,data): iu = dict() groups = data.groupby([1]) for item,group in groups: iu[item]=set(group.ix[:,0]) return iu
2.获取每个用户 对应的 评价过的物品的列表 ui
如:用户2 --- [商品A,商品B]
def user_item(self,data): ui = dict() groups = data.groupby([0]) for item,group in groups: ui[item]=set(group.ix[:,1]) return ui
3.遍历列表iu上的每一个商品,计算相似度
比如对商品A,则用户2和用户3之间,相似度加 1/log(1+3)/sqrt(2*1)
--3是商品A的流行度(3个用户评价过它),2*1表示用户2评价过的商品数乘以用户3评价过的商品数
def similarityMatrix(self): matrix=dict() N = dict() for item,users in self.iu.items(): add = 1.0/(1+math.log(len(users))) for v in users: if v not in N: N[v] = 1 else: N[v] += 1 for u in users: if v==u: continue if v not in matrix: matrix[v] = dict(); if u not in matrix[v]: matrix[v][u] = 0; matrix[v][u]+=add; for v in matrix.keys(): for u in matrix[v].keys(): matrix[v][u] /= math.sqrt(N[u]*N[v]) matrix[v] = sorted(matrix[v].items(),lambda x,y:cmp(x[1],y[1]),reverse=True); return matrix
4.推荐
def getRecommend(self,user): userItem=self.ui[user] simiusers=self.simiMatrix[user] rank = dict() for i in range(len(simiusers)): if i>=self.k: break for item in self.ui[simiusers[i][0]]: if item in userItem: continue if item not in rank: rank[item]=0 rank[item]+=simiusers[i][1]*1 rank = sorted(rank.items(),lambda x,y:cmp(x[1],y[1]),reverse=True)[0:self.k]; return [ele[0] for ele in rank]
---恢复内容结束---