CNN图像分类 入门
本次入门学习的项目是CNN图像分类的花卉识别
通过使用五种各五百张不同种类的花卉图片进行模型训练
训练结果如下:
预测成功率大概在64%左右(与训练集过少还是有一些关系的)

预测结果如下:

代码部分
训练代码解释部分:
- 模型导入:
# -*- coding:uft-8
import glob
import os
import cv2
import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
#模型导入模块
from keras.models import load_model
# 数据集的地址 改为你自己的
path = './flower_photos/'
# 缩放图片大小为100*100
w = 100
h = 100
# c = 3
- 定义图片读取函数
# 定义函数read_img,用于读取图像数据,并且对图像进行resize格式统一处理
def read_img(path):
# 创建层级列表cate,用于对数据存放目录下面的数据文件夹进行遍历,os.path.isdir用于判断文件是否是目录,然后对是目录文件的文件进行遍历
cate=[path+x for x in os.listdir(path) if os.path.isdir(path+x)]
# 创建保存图像的空列表
imgs=[]
# 创建用于保存图像标签的空列表
labels=[]
# enumerate函数用于将一个可遍历的数据对象组合为一个索引序列,同时列出数据和下标,一般用在for循环当中
# enumerate(cate) -> (0, './flower_photos/daisy') 索引+路径
for idx,folder in enumerate(cate):
# 利用glob.glob函数搜索每个层级文件下面符合特定格式“/*.jpg”进行遍历 匹配
for im in glob.glob(folder+'/*.jpg'):
#opencv读取图片,仅仅是读一下
# 利用imread函数读取每一张被遍历的图像
img=cv2.imread(im)
# 利用resize函数对每张img图像进行大小缩放,统一处理为大小为w*h(即100*100)的图像
img=cv2.resize(img,(w,h))
# 将每张经过处理的图像数据保存在之前创建的imgs空列表当中,最终所有的图片都塞到了imgs列表中
imgs.append(img)
# 将每张经过处理的图像的标签数据保存在之前创建的labels列表当中 ---这里的标签仅仅是index 0123标号
labels.append(idx)
# 利用np.asarray函数对生成的imgs和labels列表数据进行转化,之后转化成数组数据(imgs转成浮点数型,labels转成整数型)
return np.asarray(imgs,np.float32),np.asarray(labels,np.int32)
- data、label数据填充
# 将read_img函数处理之后的数据定义为样本数据data和标签数据label
data,label=read_img(path)
# 查看样本数据的大小
print("shape of data:",data.shape)
# 查看标签数据的大小
print("shape of label:",label.shape)
# 查看标签数组的内容,发现数组仅仅是01234的那种标签 用于区别图片属于哪个文件夹
print(label)
- 数据集切分、对数据进行标准化处理
# 保证生成的随机数具有可预测性,即相同的种子(seed值)所产生的随机数是相同的,这里是数是可以随便取的
seed = 785
#生成随机种子
np.random.seed(seed)
#切分数据集
#train_test_split函数按照用户指定的比例,随机将样本集合划分为训练集和测试集,并返回划分好的训练集和测试集数据
#data 待划分的样本特征集合--数组型的,这就解释了为啥上面要通np.asarry进行处理
#label 待划分的样本标签
#test_size 若在0-1之间,为测试集样本数目与原始样本数目之比;若为整数,则是测试集样本的数目 说白了就是拿出多少的测试集去让机器自己训练自己
#x_train 划分出的训练集数据 x_val 划分出的测试集数据 一般为x_test
#y_train 划分出的训练集标签 y_val 划分出的测试集标签
x_train, x_val, y_train, y_val = train_test_split(data, label, test_size=0.20, random_state=seed)
# 对数据作 标准化处理
# 由于图像的RGB色彩是最大不过(255,255,255)所以得除255 归一到[0,1]之间,由于之间转换成浮点数了,所以有小数出现 ---归一化
x_train = x_train / 255
x_val = x_val / 255
#print("hello",x_train)
- 创建图像标签列表
#创建图像标签列表
flower_dict = {0:'daisy',1:'dandelion',2:'rose',3:'sunflowers',4:'tulips'}
- 模型制作(灵魂部分)
#https://www.cnblogs.com/wj-1314/p/9579490.html 参考博客
#Sequential是Keras中的序贯模型
#序贯模型是函数式模型的简略版,为最简单的线性、从头到尾的结构顺序,不分叉,是多个网络层的线性堆叠
#Keras实现了很多层,包括core核心层,Convolution卷积层、Pooling池化层等非常丰富有趣的网络结构
#用法:可以将层的列表传递给Sequential的构造函数,来创建一个Sequential模型
#个人预测---所以这个方法可以套用别人的模型进行训练
#创建模型。模型包括3个卷积层和三个RELU激活函数,两个池化层
model = Sequential([
#调用layer.Con2D()创建了一个卷积层。32表示kernel的数量。padding=“same”表示填充输入以使输出具有与原始输入相同的长度,使用RELU函数
#tf.keras.layers.Conv2D()参数解析
#第一个参数 filters 过滤器个数/卷积核个数 与卷积后的输出通道数一样,这里的通道数就是32
#第二个参数 kernel_size卷积核尺寸 一般为3*3或5*5 这里的尺寸是height*width,若长宽一样也可以直接写一个整数3或者5
#卷积后:卷积后的height,width的计算公式如下
#滑动步长为strides,卷积核的尺寸为S,输入的尺寸为P,padding = "valid"
# height =width = (P-S)/strides +1,
# 输入形状为20×20,卷积核为3×3,滑动步长为1,所以输出为(20-3)/1 +1 =18
#第三个参数 滑动步长strides 默认为(1,1) 横向和纵向滑动均为1 可以结合上述式子进行计算输出形状
#第四个参数 默认padding="valid" 边缘不填充 另一个取值为"same"表示边缘用0填充,如果为"same"则输出的形状为height=width=P/strides
#第五个参数 data_format='channels_first'/'channels_last'输入数据的格式 ,设置输入数据中通道数是第一个还是最后一个,默认为最后一个
#第六个参数 activation = "relu" 激活函数 ,相当于经过卷积输出后,再经过一次激活函数,常见的激活函数有relu,softmax,selu等
layers.Conv2D(32, kernel_size=[5, 5], padding="same", activation=tf.nn.relu),
#调用layers.MaxPool2D()创建最大池化层,步长为2,padding=“same”表示填充输入以使输出具有与原始输入相同的长度。
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
#利用dropout随机丢弃25%的神经元,防止过拟合,默认为0.5
layers.Dropout(0.35),
#继续添加两个卷积层和一个最大池化层 卷积核数64 尺寸为3*3
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
#最大池化层
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
#利用dropout随机丢弃神经元
layers.Dropout(0.35),
# 继续添加两个卷积层和一个最大池化层
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
#利用dropout随机丢弃25%的神经元
layers.Dropout(0.35),
#Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡
layers.Flatten(),
#调用layers.Dense()创建全连接层
#输出节点数为512 256 激活函数为relu 常用的激活函数罢了,ReLU处理了它的sigmoid、tanh中常见的梯度消失问题
layers.Dense(512, activation=tf.nn.relu),
layers.Dense(256, activation=tf.nn.relu),
#添加全连接层,最后输出每个分类(5)的数值
#softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,由于只有五个类,所以输出结点为5
#我估计这里的输出节点数(维数)和激活函数是有关系的
layers.Dense(5, activation='softmax')
])
#使用Adam优化器,优化模型参数。lr(learning rate, 学习率) 老师给的参考=0.00001
#https://keras.io/zh/optimizers/ 优化器参考
opt = optimizers.Adam(learning_rate=0.001)
#编译模型以供训练。metrics=['accuracy']即评估模型在训练和测试时的性能的指标。
#optimizer 优化器
#loss 损失函数 模型试图最小化的目标函数 损失函数可以根据最后添加全连接层的激活函数进行修改
#metrics 评估标准 默认为metrics = ['accuracy']
model.compile(optimizer=opt,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
- 模型训练
#fix 函数 https://keras.io/zh/models/sequential/
#训练模型,决定训练集和验证集,batch size:进行梯度下降时每个batch包含的样本数(以多少个样本为一个batch进行一个迭代)。
#verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
#validation_data=(x_val, y_val) 用来评估损失,以及在每轮结束时的任何模型度量指标
model.fit(x_train, y_train, epochs=40, validation_data=(x_val, y_val),batch_size=200, verbose=2)
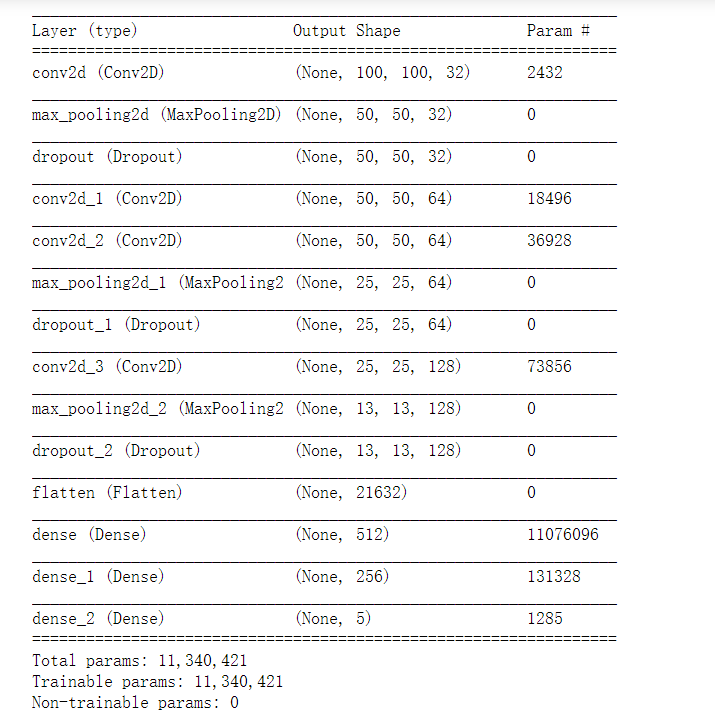
#输出模型的结构和参数量
model.summary()
-
输出日志
-
模型保存/载入函数(当你的模型训练完的时候,可以保存起来,到时候可以直接载入直接使用,省的每次都需要重新训练一遍)
#保存模型
model.save('./Model/flower_fin.h5')
#载入模型
model = load_model("./Model/flower_fin.h5")
预测代码解释部分:
- 读取图像
# 测试图像的地址 (改为自己的)
path_test = './TestImages/'
#
# 利用glob.glob函数搜索每个层级文件下面符合特定格式“/*.jpg”进行遍历
# glob.glob函数并不是按顺序从1-n来扫描的,是一种乱序扫描,第一个扫到1.jpg,第二个就扫到了10.jpg,并不像常人想的那种从1-2-3顺序扫描,
# 因此下面顺序输出的时候会出现图片和预测结果对不上的问题
# 创建保存图像的空列表
print(glob.glob(path_test+'/*.jpg'))
correction = glob.glob(path_test+'/*.jpg')
print(correction[0])
imgs=[]
for im in glob.glob(path_test+'/*.jpg'): # 利用glob.glob函数搜索每个层级文件下面符合特定格式“/*.jpg”进行遍历
img=cv2.imread(im)
img=cv2.resize(img,(w,h))
imgs.append(img) # 将每张经过处理的图像数据保存在之前创建的imgs空列表当中
imgs = np.asarray(imgs,np.float32) # 列表转换为数组 和上面的一样
print("shape of data:",imgs.shape)
- 导入模型,进行预测
#将图像导入模型进行预测 导入测试集图像
prediction = model.predict_classes(imgs)
# prediction = np.argmax(model.predict(imgs), axis=-1)
#绘制预测图像
print(prediction)
print(np.size(prediction))
for i in range(np.size(prediction)):
#打印每张图像的预测结果
print("第",i+1,"朵花预测:"+flower_dict[prediction[i]]) #预测返回的01234的标签,通过列表将他变成花名
# img = plt.imread(path_test+"test"+str(i+1)+".jpg") #读取正确图像
#由于glob函数读图是乱序读的,所以得修正一下
img = plt.imread(correction[i])
plt.imshow(img)
plt.show() #绘制
个人总结
1.通过loss、accuracy、val_loss、val_accruacy分析来优化--入门版
- loss:训练集损失值
- accuracy:训练集准确率
- val_loss:测试集损失值
- val_accruacy:测试集准确率
分析准则:
train loss 不断下降,test loss不断下降,说明网络仍在学习;(最好的)
train loss 不断下降,test loss趋于不变,说明网络过拟合;(max pool或者正则化)
train loss 趋于不变,test loss不断下降,说明数据集100%有问题;(检查dataset)
train loss 趋于不变,test loss趋于不变,说明学习遇到瓶颈,需要减小学习率或批量数目;(减少学习率)
train loss 不断上升,test loss不断上升,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题。(最不好的情况)
参考博客 https://www.cnblogs.com/Timeouting-Study/p/12591448.html
2.提高图像分类准确率----进阶版
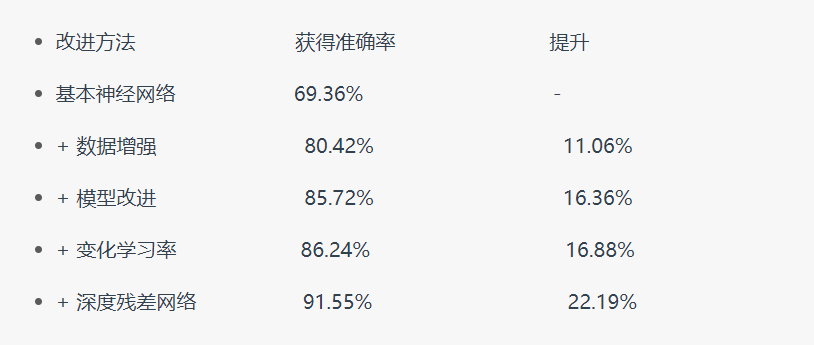
由于原博客的作者已经写的很清楚了,这里就只贴出链接以供学习参考
(PS:我个人觉得,还是通过增大数据集来训练的方法对新手还是友好一些,例如这个花卉识别由于图片每类就五六百张图片,导致准确率不大高。但是我去用类似的模型拿各有上万张图片的猫狗图片的时候,准确率能够达到百分之八十多,所以通过增大数据集还是一个可以用的方法)
参考博客 https://blog.csdn.net/weixin_38208741/article/details/79285632
3.个人认为较好的一些CNN概念介绍博客
4.TensoFlow-gpu版本安装(个人留坑)
在训练猫狗识别的时候,发现模型在迭代一次的时候就需要三分钟,如果迭代次数过多的话,就会需要很长时间,如果以后需要尝试其他项目的时候,可能会有一些不方便,决定在有时间了装上GPU版本的TensoFlow。
安装参考博客:https://blog.csdn.net/qq_43529415/article/details/100847887
CNN猫狗识别参考:https://blog.csdn.net/Einstellung/article/details/82773170
花卉识别项目:https://github.com/1103270775/Machine-learning_project