Zookeeper是一个分布式应用程序协调服务,功能包含:配置管理、统一命名、共享锁、集群管理、队列管理等,适合使用在读多于写的操作。
为什么要使用Zookeeper 达到工业级产品标准、开放源代码、免费、得到了广泛使用,诸如Hadoop、HBase、Storm以及Solr。
1. 配置管理
配置的管理在分布式应用环境中很常见,例如同一个应用系统需要多台 PC Server 运行,但是它们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,那么就必须同时修改每台运行这个应用系统的 PC Server,这样非常麻烦而且容易出错。
像这样的配置信息完全可以交给 Zookeeper 来管理,将配置信息保存在 Zookeeper 的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中。

2.统一命名
分布式应用中,通常需要有一套完整的命名规则,既能够产生唯一的名称又便于人识别和记住,通常情况下用树形的名称结构是一个理想的选择,树形的名称结构是一个有层次的目录结构,既对人友好又不会重复。说到这里你可能想到了 JNDI,没错 Zookeeper 的 Name Service 与 JNDI 能够完成的功能是差不多的,它们都是将有层次的目录结构关联到一定资源上,但是 Zookeeper 的 Name Service 更加是广泛意义上的关联,也许你并不需要将名称关联到特定资源上,你可能只需要一个不会重复名称,就像数据库中产生一个唯一的数字主键一样。
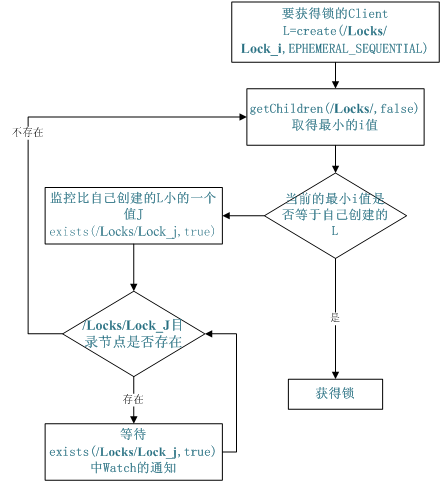
3.共享锁
不同的系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,往往需要互斥来防止彼此干扰来保证一致性,在这种情况下,便需要使用到分布式锁。共享锁在同一个进程中很容易实现,但是在跨进程或者在不同 Server 之间就不好实现了。Zookeeper 却很容易实现这个功能,实现方式也是需要获得锁的 Server 创建一个 EPHEMERAL_SEQUENTIAL 目录节点,然后调用 getChildren方法获取当前的目录节点列表中最小的目录节点是不是就是自己创建的目录节点,如果正是自己创建的,那么它就获得了这个锁,如果不是那么它就调用 exists(String path, boolean watch) 方法并监控 Zookeeper 上目录节点列表的变化,一直到自己创建的节点是列表中最小编号的目录节点,从而获得锁,释放锁很简单,只要删除前面它自己所创建的目录节点就行了。
4.集群管理
在分布式的集群中,经常会由于各种原因,比如硬件故障,软件故障,网络问题,有些节点会进进出出。有新的节点加入进来,也有老的节点退出集群。这个时候,集群中有些机器需要感知到这种变化,然后根据这种变化做出对应的决策。Zookeeper 能够很容易的实现集群管理的功能,如有多台 Server 组成一个服务集群,那么必须要一个“总管”知道当前集群中每台机器的服务状态,一旦有机器不能提供服务,集群中其它集群必须知道,从而做出调整重新分配服务策略。同样当增加集群的服务能力时,就会增加一台或多台 Server,同样也必须让“总管”知道。
Zookeeper 不仅能够帮你维护当前的集群中机器的服务状态,而且能够帮你选出一个“总管”,让这个总管来管理集群,这就是 Zookeeper 的另一个功能 Leader Election。
它们的实现方式都是在 Zookeeper 上创建一个 EPHEMERAL 类型的目录节点,然后每个 Server 在它们创建目录节点的父目录节点上调用 getClildren方法并设置 watch 为 true,由于是 EPHEMERAL 目录节点,当创建它的 Server 死去,这个目录节点也随之被删除,所以 Children 将会变化,这时 getClildren上的 Watch 将会被调用,所以其它 Server 就知道已经有某台 Server 死去了。新增 Server 也是同样的原理。
Zookeeper 如何实现 Leader Election,也就是选出一个 Master Server。和前面的一样每台 Server 创建一个 EPHEMERAL 目录节点,不同的是它还是一个 SEQUENTIAL 目录节点,所以它是个 EPHEMERAL_SEQUENTIAL 目录节点。之所以它是 EPHEMERAL_SEQUENTIAL 目录节点,是因为我们可以给每台 Server 编号,我们可以选择当前是最小编号的 Server 为 Master,假如这个最小编号的 Server 死去,由于是 EPHEMERAL 节点,死去的 Server 对应的节点也被删除,所以当前的节点列表中又出现一个最小编号的节点,我们就选择这个节点为当前 Master。这样就实现了动态选择 Master,避免了传统意义上单 Master 容易出现单点故障的问题。

5.队列管理
Zookeeper 可以处理两种类型的队列:
- 当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,这种是同步队列。
- 队列按照 FIFO 方式进行入队和出队操作,例如实现生产者和消费者模型。
Zookeeper特性
1.最终一致性
2.顺序性
3.高可用
4.原子性
5.实时性
Zookeeper基本架构

角色:
leader:负责进行投票的发起和决议,更新系统状态
follower:用于接收客户端请求并向客户端返回结果,在选举过程中参与投票。
observer:可以接收客户端的连接,将写请求转发给leader节点,但是observer不参加投票,只同步leader的状态。observer目的是扩展系统,提高读取速度。
节点数目:
Zookeeper Server数目一般为奇数,Leader选举算法采用了Paxos协议;Paxos核心思想:当多数(一半以上)Server写成功,则任务数据写成功。
Zookeeper数据模型:
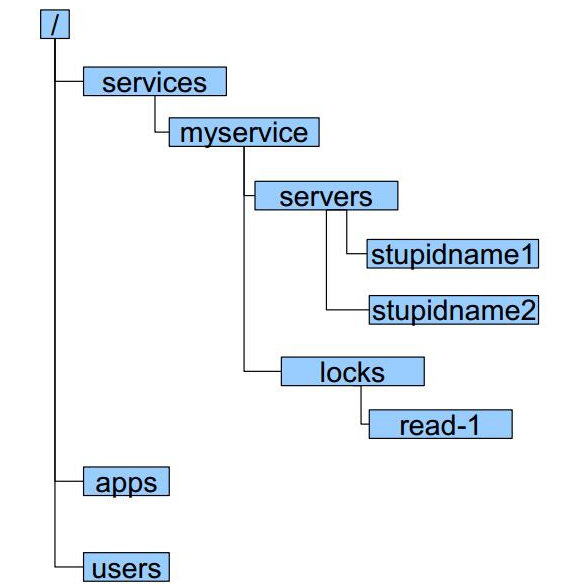
zookeeper采用层次化的目录结构,命名符合常规文件系统规范;每个目录在zookeeper中叫做znode,并且其有一个唯一的路径标识。
znode可以包含数据和子znode(ephemeral类型的节点不能有子znode); znode中的数据可以有多个版本,比如某一个znode下存有多个数据版本,那么查询这个路径下的数据需带上版本; 客户端应用可以在znode上设置监视器(Watcher) znode不支持部分读写,而是一次性完整读写。
znode有两种类型,短暂的(ephemeral)和持久的(persistent); znode的类型在创建时确定并且之后不能再修改; ephemeral znode的客户端会话结束时,zookeeper会将该ephemeral znode删除,ephemeral znode不可以有子节点; persistent znode不依赖于客户端会话,只有当客户端明确要删除该persistent znode时才会被删除。
znode有四种形式的目录节点,PERSISTENT、PERSISTENT_SEQUENTIAL、EPHEMERAL、PHEMERAL_SEQUENTIAL。
Zookeeper的ZAB协议 :
Zookeeper并没有完全采用Paxos算法,而是使用了一种称为Zookeeper Atomic BroadCast(ZAB,Zookeeper原子信息广播协议)作为一致性的核心算法。ZAB协议是为分布式协调服务专门设计的一种支持崩溃恢复的协议。
在Zookeeper中,依赖ZAB协议实现了分布式数据一致性,基于该协议,Zookeeper实现了一种主备模式的系统架构保证集群中各副本之间的数据一致性。
参考文章: http://debugo.com/zookeeper-api/