什么是多表关联查询?
根据多表连接查询返回的结果,分为三类
内连接(inner join)
外连接(outer join)
交叉连接( cross join)
交叉链接
交叉连接的关键字:CROSS JOIN
交叉连接的表现:行数相乘、列数相加
交叉连接(笛卡尔积)返回被连接的两个表所有数据行的笛卡尔积,
返回结果集合中的数据行数等于第一个表中符合查询条件的数据行数乘以第二个表中符合查询条件的数据行数。
交叉连接(笛卡尔积)语法:
SELECT * FROM table1 CROSS JOIN table2;SELECT * FROM table1 JOIN table2;SELECT * FROM table1 , table2;
隐式交叉连接
SELECT * FROM A, B
显式交叉连接
SELECT * FROM A CROSS JOIN B
例如数据库中两张表,Teacher表和 Course表,如下图所示:
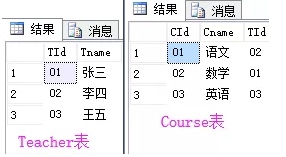
SQL 交叉连接语句(纯粹连接查询):
SELECT * FROM Teacher , Course;
输出结果:
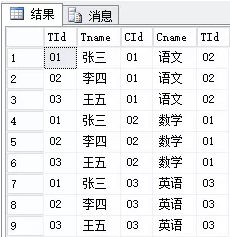
由于交叉连接(笛卡尔积)返回的结果为被连接的两个数据表的乘积,
当数据表量太多的时候,查询会非常慢,一般使用LEFT JOIN或者RIGHT JOIN。
内连接
内连接的关键字:INNER JOIN
内连接也叫连接,是最早的一种连接。还可以被称为普通连接或者自然连接,内连接是从结果表中删除与其他被连接表中没有匹配行的所有行,所以内连接可能会丢失信息。
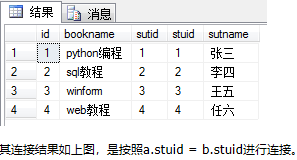
数据库数据:


book表 stu表
隐式内连接
SELECT * FROM A,B WHERE A.id = B.id
显式内连接
SELECT * FROM A INNER JOIN B ON A.id = B.id
内连接用法:
select * from book as a,stu as b where a.sutid = b.stuid
select * from book as a inner join stu as b on a.sutid = b.stuid
外连接
左联接:是以左表为基准,将a.stuid = b.stuid的数据进行连接,然后将左表没有的对应项显示,右表的列为NULL
select * from book as a left join stu as b on a.sutid = b.stuid

右连接:是以右表为基准,将a.stuid = b.stuid的数据进行连接,然以将右表没有的对应项显示,左表的列为NULL
select * from book as a right join stu as b on a.sutid = b.stuid

外连接总结:
通过业务需求,分析主从表
如果使用LEFT JOIN,则主表在它左边
如果使用RIGHT JOIN,则主表在它右边
查询结果以主表为主,从表记录匹配不到,则补null
分页查询
MySQL的分页关键字是:LIMIT
LIMIT关键字不是SQL92标准提出的关键字,它是MySQL独有的语法。
通过Limit关键字,MySQL实现了物理分页。
分页分为逻辑分页和物理分页
逻辑分页:将数据库中的数据查询到内存之后再进行分页。
物理分页:通过LIMIT关键字,直接在数据库中进行分页,最终返回的数据,只是分页后的数据。
基本格式:
SELECT * FROM articles WHERE ORDER BY id LIMIT 50, 10 ;
子查询:
子查询是一个嵌套在SELECT、INSERT、UPDATE或DELETE语句,或者其他子查询中的查询,任何允许使用表达式的地方都可以使用子查询。并且提供了使用单个查询访问多个表中数据的方法。(不建议使用因为性能不太好)
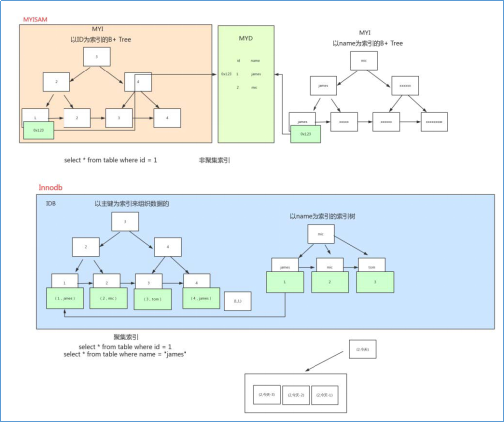
MySQL架构
逻辑架构图
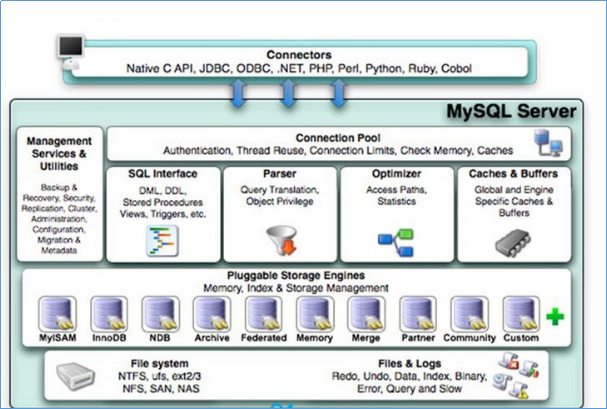
MySQL逻辑结构可以看成是二层架构,第一层我们通常叫做SQL Layer,在MySQL 数据库系统处理底层数据之前的所有工作都是在这一层完成的,包括权限判断,sql解析,执行计划优化,query cache 的处理等等;第二层就是存储引擎层,我们通常叫做StorageEngine Layer,也就是底层数据存取操作实现部分,由多种存储引擎共同组成。
简单逻辑架构图
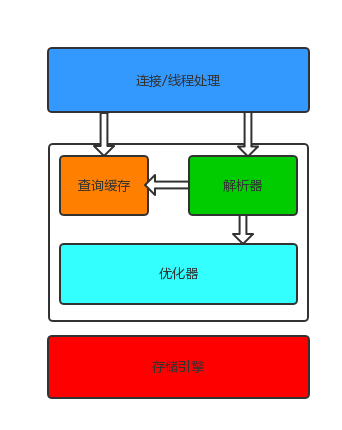
执行流程
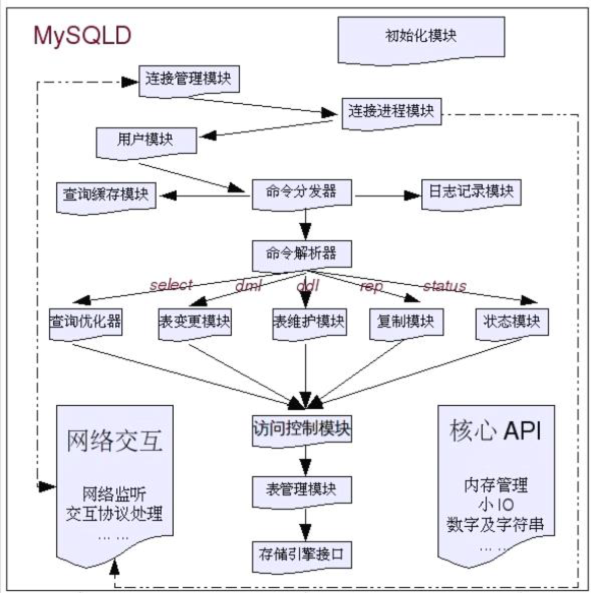
存储引擎介绍:
多存储引擎是mysql有别于其他数据库的一大特性;
存储引擎是针对表的
MySQL 5.5之后,默认的存储引擎由MyISAM变为InnoDB。
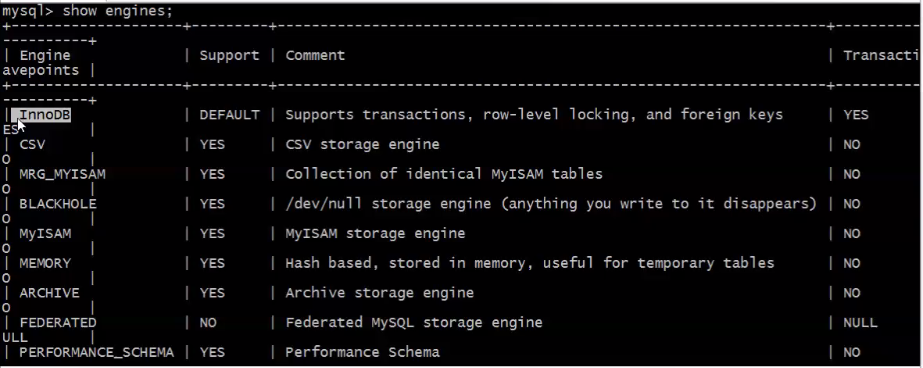
查看存储引擎:show engines;
日志文件:
MySQL通过日志记录了数据库操作信息和错误信息。常用的日志文件包括错误日志、二进制日志、查询日志、慢查询日志和 InnoDB 引擎在线 Redo 日志、中继日志等。
错误日志: 它包含启动和关闭问题以及任意根据错误的细节。此日志通常名为hostname.err.
查询日志:它记录所有MySQL活动,在诊断问题是非常有用。日志文件可能会很快的变得非常大,因此不应该长期使用它。此日志通常名为hostname.log
二进制日志: 它记录更新过数据(或者可能更新过数据)的所有语句。此日志通常名为hostname-bin
缓慢查询日志: 顾名思义,词日志记录执行 缓慢的任何查询。这个日志在确定数据库何处需要优化很有用。此日志通常名为hostname-slow.log
事务日志: 事务日志(InnoDB特有的日志)也叫redo日志。文件名为"ib_logfile0"和“ib_logfile1”,默认存放在表空间所在目录。
还有一个日志文件叫undo 日志,默认存储在ib_data目录下。
中继日志:是在主从复制环境中产生的日志。主要作用是为了从机可以从中继日志中获取到主机同步过来的SQL语句,然后执行到从机中。
索引
索引(Index)是帮助 MySQL 高效获取数据的数据结构
索引分类
唯一索引
索引列的值必须唯一,但允许有空值
随表一起建索引:CREATE TABLE customer (id INT(10) UNSIGNED AUTO_INCREMENT ,customer_no VARCHAR(200),customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name), UNIQUE (customer_no));
建立 唯一索引时必须保证所有的值是唯一的(除了null),若有重复数据,会报错。
单独建唯一索引:CREATE UNIQUE INDEX idx_customer_no ON customer(customer_no);
删除索引:DROP INDEX idx_customer_no on customer ;
复合索引
索引的存储结构