一、Mahout系统

Apache Mahout 官网地址
http://mahout.apache.org/
Apache Mahout(TM)是一个分布式线性代数框架,具有数学表达力的Scala DSL,旨在让数学家,统计学家和数据科学家快速实现自己的算法。建议使用Apache Spark开箱即用的分布式后端,也可以将其扩展到其他分布式后端。
- 数学表达式Scala DSL
- 支持多个分布式后端(包括Apache Spark)
- 用于CPU / GPU / CUDA加速的模块化本机求解器
Apache Mahout 官网地址
http://mahout.apache.org/
Mahout是Hadoop大数据平台上的开源机器学习软件包。Mahout提供了在大规模集群上对大数据进行深度分析的能力。主流的数据挖掘和机器学习算法不断在Mahout平台上实现,包括聚类、分类、协同过滤(Collaborative Filtering,用于推荐)以及频繁集挖掘等众多的算法。
早期版本的Mahout使用MapReduce计算模型实现机器学习和数据挖掘算法。由于MapReduce计算模型固有的局限性(在Stage之间和Job之间,中间结果经过磁盘进行传递),这些算法的执行效率不高。2014年Mahout社区决定把Mahout代码迁移到其他更高性能的大数据平台上运行,包括Spark和H2O。Mahout不再接受使用MapReduce编程模型实现的代码,原先已经用MapReduce模型实现的代码仍然保留,并且由Mahout社区提供维护和支持。
迁移到Spark平台的原因是Spark提供了更加灵活的编程模型和更加高性能的执行引擎。针对Spark平台开发的机器学习算法,可以充分利用Spark的内存数据处理能力,提高机器学习算法的执行效率。Mahout经过改写以后,成为一个更加通用的软件包,并不依赖于Spark,也可以运行在其他底层大数据处理系统上,比如H2O。H2O是由初创公司Oxdata开发的内存数据处理引擎,用于从HDFS上加载数据集,执行各种机器学习和统计分析算法。Mahout和Spark平台上的MLlib都是机器学习软件包,某种程度上提供了重复的功能,但是有选择对用户来讲终究是一件好事。
二、Spark MLlib系统

MLlib | Apache Spark
http://spark.apache.org/mllib/
使用方便
可在Java,Scala,Python和R中使用。
MLlib适用于Spark的API,并且可以与 Python(自Spark 0.9起)和R库(自Spark 1.5起)中的NumPy互操作。您可以使用任何Hadoop数据源(例如HDFS,HBase或本地文件),从而轻松插入Hadoop工作流。

性能
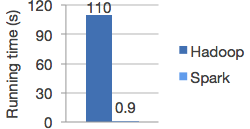
高质量算法,比MapReduce快100倍。
Spark擅长于迭代计算,从而使MLlib快速运行。同时,我们关心算法性能:MLlib包含利用迭代的高质量算法,并且比有时在MapReduce上使用的单遍逼近可以产生更好的结果。
无处不在
Spark可针对各种数据源在Hadoop,Apache Mesos,Kubernetes上独立运行或在云中运行。
您可以在EC2,Hadoop YARN,Mesos或Kubernetes上使用其独立集群模式运行Spark 。访问HDFS, Apache Cassandra, Apache HBase, Apache Hive以及数百种其他数据源中的数据。
三、Weka系统

Weka 3-使用Java中的开源机器学习软件进行数据挖掘
https://www.cs.waikato.ac.nz/ml/weka/
Weka的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),是一款免费的,非商业化(与之对应的是SPSS公司商业数据挖掘产品--Clementine )的,基于JAVA环境下开源的机器学习(machine learning)以及数据挖掘(data mining)软件。它被广泛用于教学,研究和工业应用,包含用于标准机器学习任务的大量内置工具,并且可以透明地访问scikit-learn,R和Deeplearning4j等知名工具箱。它和它的源代码可在其官方网站下载。有趣的是,该软件的缩写WEKA也是新西兰独有的一种鸟名(新西兰秧鸡),而Weka的主要开发者同时恰好来自新西兰的怀卡托大学(The University of Waikato)。
WEKA互操作性
WEKA可以与最流行的数据科学工具集成。

R
通过使用R的RWeka软件包,可以在R中使用,构建和评估Weka模型;相反,可以使用Weka的RPlugin软件包从Weka调用R算法和可视化工具。

Python
可以使用Python Weka Wrapper从Python访问Weka的功能。相反,可以从Weka使用scikit-learn之类的Python工具包。

Saprk
为了在真正的大型数据集上运行基于Weka的算法,可以使用分布式的Weka for Spark软件包。例如,它可以训练Spark中的任何Weka分类器。
四、R系统与语言

R: The R Project for Statistical Computing
https://www.r-project.org/
R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
是统计领域广泛使用的诞生于1980年左右的S语言的一个分支。可以认为R是S语言的一种实现。而S语言是由AT&T贝尔实验室开发的一种用来进行数据探索、统计分析和作图的解释型语言。最初S语言的实现版本主要是S-PLUS。S-PLUS是一个商业软件,它基于S语言,并由MathSoft公司的统计科学部进一步完善。后来新西兰奥克兰大学的Robert Gentleman和Ross Ihaka及其他志愿人员开发了一个R系统。由“R开发核心团队”负责开发。R可以看作贝尔实验室(AT&T BellLaboratories)的RickBecker,JohnChambers和AllanWilks开发的S语言的一种实现。当然,S语言也是S-Plus的基础。所以,两者在程序语法上可以说是几乎一样的,可能只是在函数方面有细微差别,程序十分容易地就能移植到一程序中,而很多一的程序只要稍加修改也能运用于R。
R软件包自2014年以来逐渐成为数据分析者的首选工具。有分析认为,全球有超过百万的分析师(包括最终用户)寻找容易使用的大数据分析工具,R软件包有可能替代商用的SAS及SPSS分析软件,成为人们的最佳选择口
五、深度学习工具TensorFlow,Caffe
5.1.TensorFlow

关于TensorFlow | TensorFlow中文官网
https://tensorflow.google.cn/
TensorFlow 是一个端到端开源机器学习平台。它拥有一个全面而灵活的生态系统,其中包含各种工具、库和社区资源,可助力研究人员推动先进机器学习技术的发展,并使开发者能够轻松地构建和部署由机器学习提供支持的应用。
轻松地构建模型
TensorFlow 提供多个抽象级别,因此您可以根据自己的需求选择合适的级别。您可以使用高阶 Keras API 构建和训练模型,该 API 让您能够轻松地开始使用 TensorFlow 和机器学习。
如果您需要更高的灵活性,则可以借助即刻执行环境进行快速迭代和直观的调试。对于大型机器学习训练任务,您可以使用 Distribution Strategy API 在不同的硬件配置上进行分布式训练,而无需更改模型定义。
随时随地进行可靠的机器学习生产
TensorFlow 始终提供直接的生产途径。不管是在服务器、边缘设备还是网络上,TensorFlow 都可以助您轻松地训练和部署模型,无论您使用何种语言或平台。
如果您需要完整的生产型机器学习流水线,请使用 TensorFlow Extended (TFX)。要在移动设备和边缘设备上进行推断,请使用 TensorFlow Lite。请使用 TensorFlow.js 在 JavaScript 环境中训练和部署模型。
强大的研究实验
构建和训练先进的模型,并且不会降低速度或性能。借助 Keras Functional API 和 Model Subclassing API 等功能,TensorFlow 可以助您灵活地创建复杂拓扑并实现相关控制。为了轻松地设计原型并快速进行调试,请使用即刻执行环境。
TensorFlow 还支持强大的附加库和模型生态系统以供您开展实验,包括 Ragged Tensors、TensorFlow Probability、Tensor2Tensor 和 BERT。
5.2.Caffe

Caffe2 | A New Lightweight, Modular, and Scalable Deep Learning Framework
https://caffe2.ai/
Caffe,全称Convolutional Architecture for Fast Feature Embedding,是一个兼具表达性、速度和思维模块化的深度学习框架。由伯克利人工智能研究小组和伯克利视觉和学习中心开发。虽然其内核是用C++编写的,但Caffe有Python和Matlab 相关接口。Caffe支持多种类型的深度学习架构,面向图像分类和图像分割,还支持CNN、RCNN、LSTM和全连接神经网络设计。Caffe支持基于GPU和CPU的加速计算内核库,如NVIDIA cuDNN和Intel MKL。
特点
- Caffe 完全开源,并且在有多个活跃社区沟通解答问题,同时提供了一个用于训练、测试等完整工具包,可以帮助使用者快速上手。此外 Caffe 还具有以下特点:
- 模块性:Caffe 以模块化原则设计,实现了对新的数据格式,网络层和损失函数轻松扩展。
- 表示和实现分离:Caffe 已经用谷歌的 Protocl Buffer定义模型文件。使用特殊的文本文件 prototxt 表示网络结构,以有向非循环图形式的网络构建。
- Python和MATLAB结合: Caffe 提供了 Python 和 MATLAB 接口,供使用者选择熟悉的语言调用部署算法应用。
- GPU 加速:利用了 MKL、Open BLAS、cu BLAS 等计算库,利用GPU实现计算加速。