使用框架简单快速开发特定的系统。
pip freeze > requirements.txt
pip install -r requirements.txt一 MVC和MTV模式
二 简介
Django时有Python开发的一个免费的开源网站框架,可以用于快速搭建高性能、优雅的网站。
Django框架的特点:
- 强大的数据库功能
- 自带强大的后台功能
- 通过正则匹配随意定义的网址
- 强大易扩展的模板系统
- 缓存系统
- 国际化
三 Django安装方式
1.利用pip安装Django。
oliver@oliver-G460:~$ sudo pip3 install Django
2.利用源码包安装Django。
oliver@oliver-G460:~$ tar -zxvf django-1.10.xx.tar.gz
解压后进入目录,执行:
python3 setup.py install
3.利用Linux自带源安装Django。
sudo apt-get install python3-django
检查Django是否安装成功:
oliver@oliver-G460:~$ python3 Python 3.5.2 (default, Sep 10 2016, 08:21:44) [GCC 5.4.0 20160609] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import django >>> django.VERSION (1, 10, 2, 'final', 0)
如果希望安装不同版本的Django环境,则需要通过virtualenv来管理多个开发环境。
四 Django项目创建
方式一:用命令创建项目和app
1. 创建一个新的Django项目
![]()
2. 创建app
python3 manage.py startapp app-name 或 django-admin.py startapp app-name
需要注意的是,通过命令行创建的项目,在settings.py中,如app名称和模板路径及templates目录等信息要自己添加。
方式二:用Pycharm创建
在File→New Project中选择Django,输入项目名称mysite和应用名称myApp,完成创建。
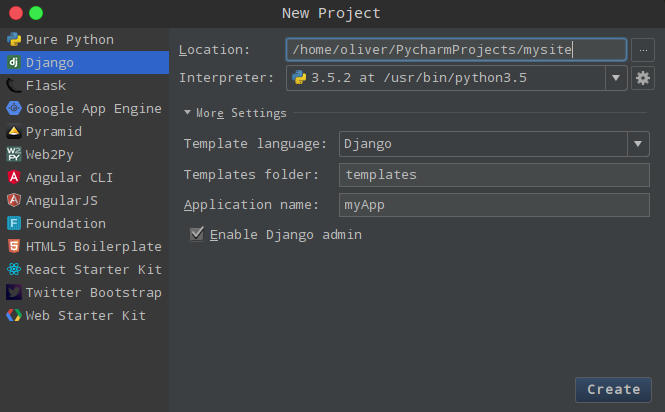
创建完成后, 用Pycharm打开项目,查看项目和app目录文件
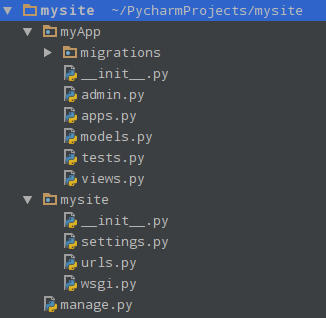
- manage.py:用于管理Django站点。
- settings.py:项目所有的配置信息,包含项目默认设置,数据库信息,调试标识以及其它工作变量等。
- urls.py:负责把URL映射到视图函数,即路由系统。
- wsgi.py:内置runserver命令的WSGI应用配置。
五 Django urls(路由系统)
即urls.py文件。其本质是建立url与其所调用的视图函数的映射关系,以此来规定访问什么网址去对应什么内容,执行哪个视图函数。
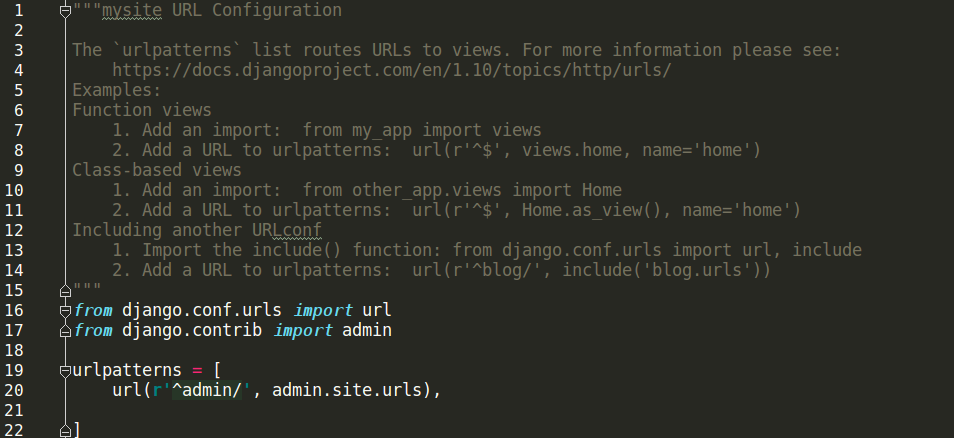
urlpatterns = [
url(正则表达式,views视图函数,[参数],[别名]),
]
说明(括号中四部分的意义):
- 正则表达式字符串来匹配浏览器发送到服务端的URL网址
- 可调用的视图函数对象。先引入(import)再使用
- 要传给视图函数的默认参数(字典形式)
- name,即别名。HTML中form表单参数action属性值使用此别名后,即便url发生变化,也无需在HTML中批量进行修改。
1 URL配置举例:


from django.conf.urls import url from django.contrib import admin from app01 import views urlpatterns = [ url(r'^articles/2003/$', views.special_case_2003), #url(r'^articles/[0-9]{4}/$', views.year_archive), url(r'^articles/([0-9]{4})/$', views.year_archive), #no_named group url(r'^articles/([0-9]{4})/([0-9]{2})/$', views.month_archive), url(r'^articles/([0-9]{4})/([0-9]{2})/([0-9]+)/$', views.article_detail), ]
用()括起来表示保存为一个子组,每个子组作为一个参数(无名参数),被views.py中的对应函数接收。参数个数与视图函数中的形参个数要保持一致。
(注意:当匹配到第一个url后立即返回,不再向下查找匹配。)
2 带命名的组Named group(?P<>)用法
?P<group_name> 表示带命名的参数,例如:将year='2016'作为一个整体传个视图函数。此处的组名称必须与视图函数中的形参名称一致。由于有参数名称与之对应,所以视图函数有多个形参时,不需要考虑参数的先后顺序。
from django.conf.urls import url from . import views urlpatterns = [ url(r'^articles/2003/$', views.special_case_2003), url(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive), # year=2016 url(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$', views.month_archive), url(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/(?P<day>[0-9]{2})/$', views.article_detail), ]
3 默认参数(可选)
如下所示,如果请求地址为/blog/2016,表示将year='2016',foo='bar'传给视图函数,视图函数中必须有相同名称的形参来接收值。
from django.conf.urls import url from . import views urlpatterns = [ url(r'^blog/(?P<year>[0-9]{4})/$', views.year_archive, {'foo': 'bar'}), ]
4 name别名(可选)
固定用法:
url(r'^/index/',views.index,name='bieming')
如果url中的路径修改为/index2/,对应的模板,甚至还视图中的跳转,以及 models.py 中也可能有获取网址的地方。每个地方都要改,修改的代价很大,一不小心,有的地方没改过来,那个就不能用了。
因此,在需要跳转或获取网址的地方,使用别名设置的名称,以后便可以随意修改url了。
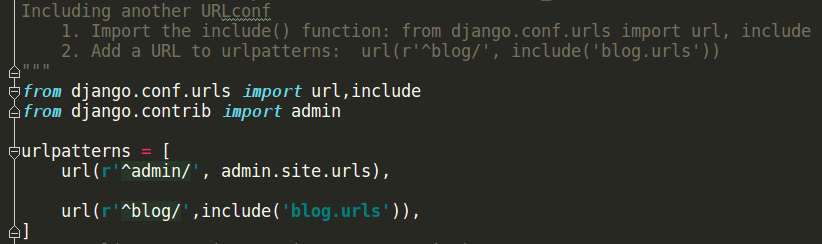
urlpatterns = [ url(r'^index',views.index,name='bieming'), url(r'^admin/', admin.site.urls), # url(r'^articles/2003/$', views.special_case_2003), url(r'^articles/([0-9]{4})/$', views.year_archive), # url(r'^articles/([0-9]{4})/([0-9]{2})/$', views.month_archive), # url(r'^articles/([0-9]{4})/([0-9]{2})/([0-9]+)/$', views.article_detail), ] ################### def index(req): if req.method=='POST': username=req.POST.get('username') password=req.POST.get('password') if username=='alex' and password=='123': return HttpResponse("登陆成功") return render(req,'index.html') ##################### <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> {# <form action="/index/" method="post">#} <form action="{% url 'bieming' %}" method="post"> 用户名:<input type="text" name="username"> 密码:<input type="password" name="password"> <input type="submit" value="submit"> </form> </body> </html> #######################
5 URLconf
一个网站包含成千上万个URL,如果所有的URL映射都放在一个文件下,很可能会出错,也不便与维护。
因此,我们在每个app应用下分别创建一个urls目录,将不同的请求分发给不同app下的urls去匹配,如:对于/blog/index/请求直接交给‘blog.urls’去处理,清晰明确,更方便管理。
六 Django views(视图函数)
http请求中产生的两大核心对象:
http请求:HttpRequest对象
http响应:HttpResponse对象
所在位置:django.http
request就是指HttpRequest。
1 HttpRequest对象的属性和方法
| 属性 | 描述 |
|---|---|
| path | 请求页面的全路径,不包括域名—例如, "/music/bands/the_beatles/"。 |
| method | 请求中使用的HTTP方法的字符串表示。全大写表示。 |
| GET | 包含所有HTTP GET参数的类字典对象 |
| POST | 包含所有HTTP POST参数的类字典对象 |
| REQUEST | 为了方便,该属性是POST和GET属性的集合体,但是有特殊性,先查找POST属性,然后再查找GET属性 |
| COOKIES | 包含所有cookies的标准Python字典对象。Keys和values都是字符串。 |
| FILES | 包含所有上传文件的类字典对象。FILES中的每个Key都是<input type="file" name="" />标签中name属性的值. FILES中的每个value 同时也是一个标准Python字典对象,包含下面三个Keys:(Filename: 上传文件名,用Python字符串表示;content-type: 上传文件的Content type;content: 上传文件的原始内容)注意:只有在请求方法是POST,并且请求页面中<form>有enctype="multipart/form-data"属性时FILES才拥有数据。否则,FILES 是一个空字典。 |
| META | 包含所有可用HTTP头部信息的字典,例如:(CONTENT_LENGTH,CONTENT_TYPE,QUERY_STRING: 未解析的原始查询字符,串,REMOTE_ADDR: 客户端IP地址REMOTE_HOST: 客户端主机名,SERVER_NAME: 服务器主机名,SERVER_PORT: 服务器端口);META 中这些头加上前缀HTTP_最为Key, 例如:(HTTP_ACCEPT_ENCODING,HTTP_ACCEPT_LANGUAGE,HTTP_HOST: 客户发送的HTTP主机头信息,HTTP_REFERER: referring页,HTTP_USER_AGENT: 客户端的user-agent字符串,HTTP_X_BENDER: X-Bender头信息) |
| user | 是一个django.contrib.auth.models.User 对象,代表当前登录的用户。如果访问用户当前没有登录,user将被初始化为django.contrib.auth.models.AnonymousUser的实例。见例子1 |
| session | 唯一可读写的属性,代表当前会话的字典对象。只有激活Django中的session支持时该属性才可用。 |
| raw_post_data | 原始HTTP POST数据,未解析过。 高级处理时会有用处。 |
| method | 描述 |
|---|---|
| __getitem__(key) | 返回GET/POST的键值,先取POST,后取GET。如果键不存在抛出 KeyError。这是我们可以使用字典语法访问HttpRequest对象。例如:request["foo"]等同于先request.POST["foo"] 然后 request.GET["foo"]的操作。 |
| has_key() | 检查request.GET or request.POST中是否包含参数指定的Key。 |
| get_full_path() | 返回包含查询字符串的请求路径。例如, "/music/bands/the_beatles/?print=true" |
| is_secure() | 如果请求是安全的,返回True,就是说,发出的是HTTPS请求。 |
get_full_path(), 比如:http://127.0.0.1:8000/index33/?name=123 ,req.get_full_path()得到的结果就是/index33/?name=123
req.path得到的结果是:/index33
2 HttpResponse对象的属性和方法
对于HttpRequest对象来说,是由django自动创建的,但是,HttpResponse对象就必须我们自己创建。每个view请求处理方法必须返回一个HttpResponse对象。
HttpResponse类在django.http.HttpResponse
在HttpResponse对象上扩展的常用方法:
页面渲染: render()(推荐) 或 render_to_response(), 页面跳转: redirect("路径") locals(): 可以直接将函数中所有的变量传给模板
七 Django templates(模板)
模板由HTML+逻辑控制代码组成。
1 变量
使用双大括号来引用变量
语法格式: {{var_name}}
2 Template和Context对象
渲染操作流程:
一旦创建Template对象之后,可以用context传递数据给它,它是一系列变量和它们值的集合,模板使用它来赋值模板变量标签和执行块标签
context在django里表现为Context类,在django.template模块中
Context类构造是一个可选参数:一个字典映射变量和它们的值
创建一系列Context对象之后,调用Template对象的render()方法并传递Context对象来填充模板
同一个模板渲染多个context:
1 >>>from django,template import Template,Context 2 >>>t=Template("My name is {{name}},I love{{language}}") 3 >>>c=Context({'name':'BeginMan','language':'Python/Js/C#'}) 4 >>>t.render(c) 5 --------------------------------output---------------------------------------------- 6 My name is BeginMan ,I love Python/Js/C#
推荐写法:
def current_time(req):
now=datetime.datetime.now()
return render(req, 'current_datetime.html', {'current_date':now}) # 字典部分指定就是Context对象,render()方法将Context对象的键值传递给模板,并填充模板。
3 深度变量查找
context不仅能传递简单的参数(字符串),也可以传递列表和字典对象。
1 #最好是用几个例子来说明一下。 2 # 首先,句点可用于访问列表索引,例如: 3 4 >>> from django.template import Template, Context 5 >>> t = Template('Item 2 is {{ items.2 }}.') 6 >>> c = Context({'items': ['apples', 'bananas', 'carrots']}) 7 >>> t.render(c) 8 'Item 2 is carrots.' 9 10 #假设你要向模板传递一个 Python 字典。 要通过字典键访问该字典的值,可使用一个句点: 11 >>> from django.template import Template, Context 12 >>> person = {'name': 'Sally', 'age': '43'} 13 >>> t = Template('{{ person.name }} is {{ person.age }} years old.') 14 >>> c = Context({'person': person}) 15 >>> t.render(c) 16 'Sally is 43 years old.' 17 18 #同样,也可以通过句点来访问对象的属性。 比方说, Python 的 datetime.date 对象有 19 #year 、 month 和 day 几个属性,你同样可以在模板中使用句点来访问这些属性: 20 21 >>> from django.template import Template, Context 22 >>> import datetime 23 >>> d = datetime.date(1993, 5, 2) 24 >>> d.year 25 >>> d.month 26 >>> d.day 27 >>> t = Template('The month is {{ date.month }} and the year is {{ date.year }}.') 28 >>> c = Context({'date': d}) 29 >>> t.render(c) 30 'The month is 5 and the year is 1993.' 31 32 # 这个例子使用了一个自定义的类,演示了通过实例变量加一点(dots)来访问它的属性,这个方法适 33 # 用于任意的对象。 34 >>> from django.template import Template, Context 35 >>> class Person(object): 36 ... def __init__(self, first_name, last_name): 37 ... self.first_name, self.last_name = first_name, last_name 38 >>> t = Template('Hello, {{ person.first_name }} {{ person.last_name }}.') 39 >>> c = Context({'person': Person('John', 'Smith')}) 40 >>> t.render(c) 41 'Hello, John Smith.' 42 43 # 点语法也可以用来引用对象的方法。 例如,每个 Python 字符串都有 upper() 和 isdigit() 44 # 方法,你在模板中可以使用同样的句点语法来调用它们: 45 >>> from django.template import Template, Context 46 >>> t = Template('{{ var }} -- {{ var.upper }} -- {{ var.isdigit }}') 47 >>> t.render(Context({'var': 'hello'})) 48 'hello -- HELLO -- False' 49 >>> t.render(Context({'var': '123'})) 50 '123 -- 123 -- True' 51 52 # 注意这里调用方法时并* 没有* 使用圆括号 而且也无法给该方法传递参数;你只能调用不需参数的 53 # 方法。
4 变量过滤器filter
语法格式: {{obj|filter:param}}
1 # 1 add : 给变量加上相应的值 2 # 3 # 2 addslashes : 给变量中的引号前加上斜线 4 # 5 # 3 capfirst : 首字母大写 6 # 7 # 4 cut : 从字符串中移除指定的字符 8 # 9 # 5 date : 格式化日期字符串 10 # 11 # 6 default : 如果值是False,就替换成设置的默认值,否则就是用本来的值 12 # 13 # 7 default_if_none: 如果值是None,就替换成设置的默认值,否则就使用本来的值 14 15 16 #实例: 17 18 #value1="aBcDe" 19 {{ value1|upper }} 20 21 #value2=5 22 {{ value2|add:3 }} 23 24 #value3='he llo wo r ld' 25 {{ value3|cut:' ' }} 26 27 #import datetime 28 #value4=datetime.datetime.now() 29 {{ value4|date:'Y-m-d' }} 30 31 #value5=[] 32 {{ value5|default:'空的' }} 33 34 #value6='<a href="#">跳转</a>' 35 36 {{ value6 }} 37 38 {% autoescape off %} 39 {{ value6 }} 40 {% endautoescape %} 41 42 {{ value6|safe }} 43 44 {{ value6|striptags }} 45 46 #value7='1234' 47 {{ value7|filesizeformat }} 48 {{ value7|first }} 49 {{ value7|length }} 50 {{ value7|slice:":-1" }} 51 52 #value8='http://www.baidu.com/?a=1&b=3' 53 {{ value8|urlencode }} 54 value9='hello I am yuan'
5 常用标签(tag)
语法格式: {% tags %}
(1) {% if %}
(2) {% for %}
(3) {% csrf_token %}
(4) {% url %} :引用路由配置的地址
(5) {% with %} :用简短的变量名代替复杂的变量名
(6) {% verbatim %} :禁止render
(7) {% load %} :加载标签库
6 自定义filter和simple_tag
(1)在app下创建templatetags目录或模块,目录名称必须这样写。
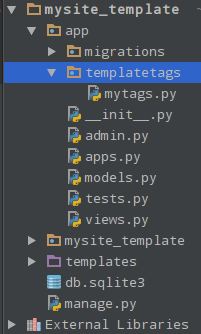
(2)创建.py文件,如my_tags。(其中,register名称不可改变)
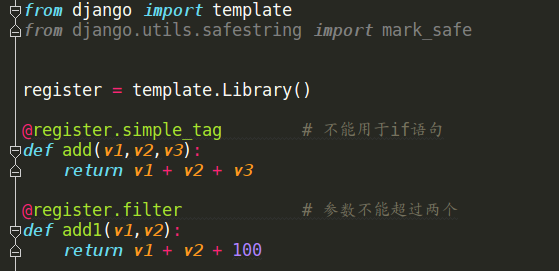
(3)在使用自定义filter和simple_tag的html文件之前,通过 {% load my_tags %}导入前面自己创建的my_tags标签库。(注意:settings中INSTALLED_APPS中必须添加当前的app名称,否则找不到自定义的tags)
(4)调用自定义的filter和simple_tag。
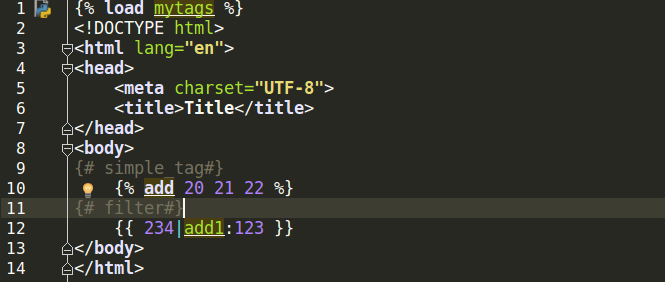
filter可以用在if等语句后,simple_tag不可以:
{% if num|filter_multi:30 > 100 %}
{{ num|filter_multi:30 }}
{% endif %}
7 extend模板继承
将shopping_car.html和ordered.html中大量重复的代码提取出来,写入base.html中,不同的部分分别写在各自模板中,通过extends继承base.html中的公共部分。
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <title>Title</title> 6 <style> 7 *{ 8 margin: 0; 9 } 10 11 .top{ 12 height: 45px; 13 background-color: darkblue; 14 } 15 16 .menu{ 17 width: 20%; 18 height: 700px; 19 background-color: cornflowerblue; 20 float: left; 21 margin-top: 5px; 22 } 23 24 .menu a{ 25 display: block; 26 text-align: center; 27 } 28 29 .content{ 30 width: 80%; 31 height: 700px; 32 float: left; 33 margin-top: 5px; 34 background-color: lightgray; 35 } 36 </style> 37 </head> 38 <body> 39 <div class="top"></div> 40 <div class="menu"> 41 <a href="/shopping_car/">Shopping Car</a> 42 <a href="/ordered/">Ordered</a> 43 </div> 44 <div class="content"> 45 {% block content %} 46 {% endblock %} 47 </div> 48 </body> 49 </html>
shopping_car.html:
1 {% extends 'base.html' %} 2 3 4 {% block content %} 5 <a>购物车</a> 6 {% endblock %}
ordered.html:
1 {% extends 'base.html' %} 2 3 4 {% block content %} 5 <a>订单</a> 6 {% endblock %}
八 Django modules(模型)
1 django默认支持sqlite,mysql, oracle,postgresql数据库。
<1> sqlite
django默认使用sqlite的数据库,默认自带sqlite的数据库驱动
引擎名称:django.db.backends.sqlite3
<2> mysql
引擎名称:django.db.backends.mysql
2 mysql驱动程序
MySQLdb(mysql python)
mysqlclient
MySQL
PyMySQL(纯python的mysql驱动程序)
3 Django的项目中默认使用sqlite数据库,在settings中设置如下:

如果想要使用mysql数据库,只需要做如下更改:
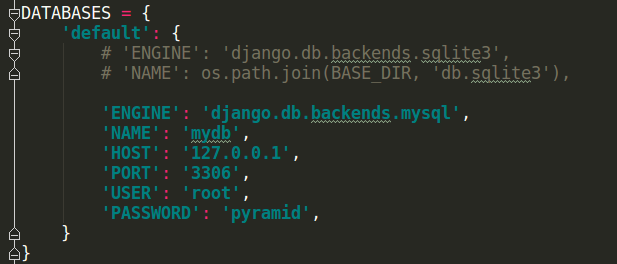
注意:NAME即数据库的名字,在mysql连接前该数据库必须已经创建,而上面的sqlite数据库下的db.sqlite3则是项目自动创建
USER和PASSWORD分别是数据库的用户名和密码。
设置完后,再启动我们的Django项目前,我们需要激活我们的mysql。
然后,启动项目,会报错:no module named MySQLdb
这是因为django默认你导入的驱动是MySQLdb,可是MySQLdb对于py3有很大问题,所以我们需要的驱动是PyMySQL
所以,我们只需要找到项目名文件下的__init__,在里面写入:

ORM(对象关系映射)
对象-关系映射(Object/Relation Mapping,简称ORM),是随着面向对象的软件开发方法发展而产生的。面向对象的开发方法是当今企业级应用开发环境中的主流开发方法,关系数据库是企业级应用环境中永久存放数据的主流数据存储系统。对象和关系数据是业务实体的两种表现形式,业务实体在内存中表现为对象,在数据库中表现为关系数据。内存中的对象之间存在关联和继承关系,而在数据库中,关系数据无法直接表达多对多关联和继承关系。因此,对象-关系映射(ORM)系统一般以中间件的形式存在,主要实现程序对象到关系数据库数据的映射。 面向对象是从软件工程基本原则(如耦合、聚合、封装)的基础上发展起来的,而关系数据库则是从数学理论发展而来的,两套理论存在显著的区别。为了解决这个不匹配的现象,对象关系映射技术应运而生。 让我们从O/R开始。字母O起源于"对象"(Object),而R则来自于"关系"(Relational)。几乎所有的程序里面,都存在对象和关系数据库。在业务逻辑层和用户界面层中,我们是面向对象的。当对象信息发生变化的时候,我们需要把对象的信息保存在关系数据库中。 当你开发一个应用程序的时候(不使用O/R Mapping),你可能会写不少数据访问层的代码,用来从数据库保存,删除,读取对象信息,等等。你在DAL中写了很多的方法来读取对象数据,改变状态对象等等任务。而这些代码写起来总是重复的。 如果打开你最近的程序,看看DAL代码,你肯定会看到很多近似的通用的模式。我们以保存对象的方法为例,你传入一个对象,为SqlCommand对象添加SqlParameter,把所有属性和对象对应,设置SqlCommand的CommandText属性为存储过程,然后运行SqlCommand。对于每个对象都要重复的写这些代码。 除此之外,还有更好的办法吗?有,引入一个O/R Mapping。实质上,一个O/R Mapping会为你生成DAL。与其自己写DAL代码,不如用O/R Mapping。你用O/R Mapping保存,删除,读取对象,O/R Mapping负责生成SQL,你只需要关心对象就好。 对象关系映射成功运用在不同的面向对象持久层产品中,如:Torque,OJB,hibernate,TopLink,Castor JDO, TJDO 等。
一般的ORM包括以下四部分: 一个对持久类对象进行CRUD操作的API; 一个语言或API用来规定与类和类属性相关的查询; 一个规定mapping metadata的工具; 一种技术可以让ORM的实现同事务对象一起进行dirty checking, lazy association fetching以及其他的优化操作。
1 django ORM——创建表(模型)
django模型常用的字段类型
| 字段名 |
参数 |
意义 |
|
AutoField |
|
一个能够根据可用ID自增的 IntegerField |
|
BooleanField |
|
一个真/假(true/false)字段 |
|
CharField |
(max_length) |
一个字符串字段,适用于中小长度的字符串。对于长段的文字,请使用 TextField |
|
CommaSeparatedIntegerField |
(max_length) |
一个用逗号分隔开的整数字段 |
|
DateField |
([auto_now], [auto_now_add]) |
日期字段 |
|
DateTimeField |
|
时间日期字段,接受跟 DateField 一样的额外选项 |
|
EmailField |
|
一个能检查值是否是有效的电子邮件地址的 CharField |
|
FileField |
(upload_to) |
一个文件上传字段 |
|
FilePathField |
(path,[match],[recursive]) |
一个拥有若干可选项的字段,选项被限定为文件系统中某个目录下的文件名 |
|
FloatField |
(max_digits,decimal_places) |
一个浮点数,对应Python中的 float 实例 |
|
ImageField |
(upload_to, [height_field] ,[width_field]) |
像 FileField 一样,只不过要验证上传的对象是一个有效的图片。 |
|
IntegerField |
|
一个整数。 |
|
IPAddressField |
|
一个IP地址,以字符串格式表示(例如: "24.124.1.30" )。 |
|
NullBooleanField |
|
就像一个 BooleanField ,但它支持 None /Null 。 |
|
PhoneNumberField |
|
它是一个 CharField ,并且会检查值是否是一个合法的美式电话格式 |
|
PositiveIntegerField |
|
和 IntegerField 类似,但必须是正值。 |
|
PositiveSmallIntegerField |
|
与 PositiveIntegerField 类似,但只允许小于一定值的值,最大值取决于数据库. |
|
SlugField |
|
嵌条 就是一段内容的简短标签,这段内容只能包含字母、数字、下 划线或连字符。通常用于URL中 |
|
SmallIntegerField |
|
和 IntegerField 类似,但是只允许在一个数据库相关的范围内的数值(通常是-32,768到 +32,767) |
|
TextField |
|
一个不限长度的文字字段 |
|
TimeField |
|
时分秒的时间显示。它接受的可指定参数与 DateField 和 DateTimeField 相同。 |
|
URLField |
|
用来存储URL的字段。 |
|
USStateField |
|
美国州名称缩写,两个字母。 |
|
XMLField |
(schema_path) |
它就是一个 TextField ,只不过要检查值是匹配指定schema的合法XML。 |
| 参数名 |
意义 |
|
null |
如果设置为 True 的话,Django将在数据库中存储空值为 NULL 。默认为 False 。 |
|
blank |
如果是 True ,该字段允许留空,默认为 False 。 |
|
choices |
一个包含双元素元组的可迭代的对象,用于给字段提供选项。 |
|
db_column |
当前字段在数据库中对应的列的名字。 |
|
db_index |
如果为 True ,Django会在创建表格(比如运行 manage.py syncdb )时对这一列创建数据库索引。 |
|
default |
字段的默认值 |
|
editable |
如果为 False ,这个字段在管理界面或表单里将不能编辑。默认为 True 。 |
|
help_text |
在管理界面表单对象里显示在字段下面的额外帮助文本。 |
|
primary_key |
如果为 True ,这个字段就会成为模型的主键。 |
|
radio_admin |
默认地,对于 ForeignKey 或者拥有 choices 设置的字段,Django管理界面会使用列表选择框(<select>)。如果 radio_admin 设置为 True 的话,Django就会使用单选按钮界面。 |
|
unique |
如果是 True ,这个字段的值在整个表中必须是唯一的。 |
|
unique_for_date |
把它的值设成一个 DataField 或者 DateTimeField 的字段的名称,可以确保字段在这个日期内不会出现重复值。 |
|
unique_for_month |
和 unique_for_date 类似,只是要求字段在指定字段的月份内唯一。 |
|
unique_for_year |
和 unique_for_date 及 unique_for_month 类似,只是时间范围变成了一年。 |
|
verbose_name |
除 ForeignKey 、 ManyToManyField 和 OneToOneField 之外的字段都接受一个详细名称作为第一个位置参数。 |
实例:创建一个书籍、作者、出版社数据库结构
一本书可能有多个作者,一个作者可以写多本书,一本书通常仅由一个出版社出版。因此作者与书为多对多关系,出版社与书为一对多关系。接下来,我们来创建表(模型)。
多对多关系(many-to-many):彼此一对多,自动创建第三张表来表示对应关系。
一对多关系(one-to-many):主外键关系,在many对应的表中给需要的字段添加外键。
一对一(one-to-one):在一对多基础上,在多的哪个表ForeignKey的基础上加unique=true。
1 每个数据模型都是django.db.models.Model的子类,它的父类Model包含了所有必要的和数据库交互的方法。并提供了一个简介漂亮的定义数据库字段的语法。
2 每个模型相当于单个数据库表(多对多关系例外,会多生成一张关系表),每个属性也是这个表中的字段。属性名就是字段名,它的类型(例如CharField)相当于数据库的字段类型(例如varchar)。
1 from django.db import models 2 3 # Create your models here. 4 class Publisher(models.Model): 5 6 name = models.CharField(max_length=64,verbose_name="出版社名称") 7 city = models.CharField(max_length=24,verbose_name="所在城市") 8 9 10 def __str__(self): 11 12 return self.name 13 14 15 class Author(models.Model): 16 17 name = models.CharField(max_length=20,verbose_name="作者名称") 18 sex = models.BooleanField(max_length=1,choices=((0,'男'),(1,'女'))) 19 email = models.EmailField() 20 birthday = models.DateField() 21 22 def __str__(self): 23 24 return self.name 25 26 27 class Book(models.Model): 28 29 title = models.CharField(max_length=64,verbose_name="书名") 30 authors = models.ManyToManyField(Author) 31 publish = models.ForeignKey(Publisher) 32 price = models.DecimalField(max_digits=5,decimal_places=2,default=10) 33 34 def __str__(self): 35 36 return self.title
确认当前app已经添加到settings设置中,然后执行数据库初始化操作: python3 manage.py makemigrations和python3 manage.py migrate。
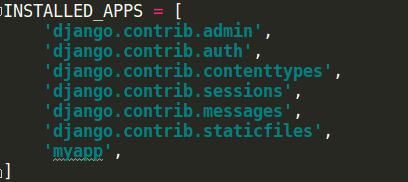
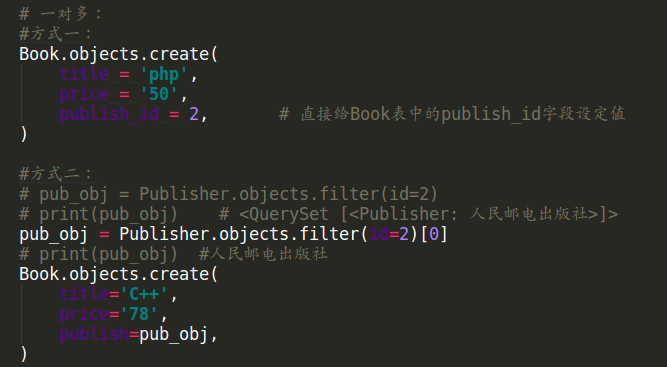
2 django ORM——增(create、save)
增加数据有两种方式: (数据表中的每一条数据代表一个对象)

创建一对多关系:
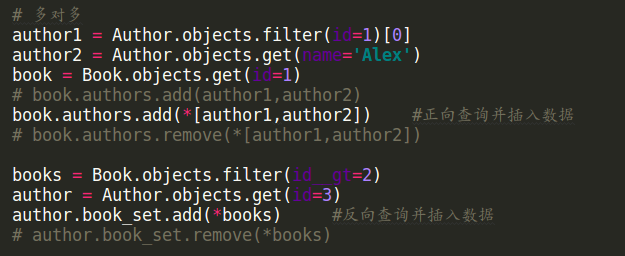
创建多对多关系:
3 django ORM——删(delete)

4 django ORM——改(update、save)
只有QuerySet对象才有update方法,因此查找行对象时只能使用filter,不能使用get。返回的整数表示受影响的行数。
![]()
save方法会将所有属性重新设定一遍,而update只对指定的属性值进行设定,故update方法更高效。

5 django ORM——查
1 # 查询相关API: 2 3 # <1>filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 4 5 # <2>all(): 查询所有结果 6 7 # <3>get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。 8 9 #-----------下面的方法都是对查询的结果再进行处理:比如 objects.filter.values()-------- 10 11 # <4>values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列 12 13 # <5>exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 14 15 # <6>order_by(*field): 对查询结果排序 16 17 # <7>reverse(): 对查询结果反向排序 18 19 # <8>distinct(): 从返回结果中剔除重复纪录 20 21 # <9>values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 22 23 # <10>count(): 返回数据库中匹配查询(QuerySet)的对象数量。 24 25 # <11>first(): 返回第一条记录 26 27 # <12>last(): 返回最后一条记录 28 29 # <13>exists(): 如果QuerySet包含数据,就返回True,否则返回False。
>>> Book.objects.all() <QuerySet [<Book: python>, <Book: php>, <Book: python红宝书>, <Book: C语言>, <Book: C++>, <Book: 杜拉拉大结局>, <Book: 百年孤独>]> >>> Book.objects.filter(price__lt=50) <QuerySet [<Book: python红宝书>, <Book: 杜拉拉大结局>, <Book: 百年孤独>]> >>> Book.objects.get(title='python') <Book: python> >>> Book.objects.filter(price__lt=50).values() <QuerySet [{'title': 'python红宝书', 'price': Decimal('8.00'), 'publish_id': 4, 'id': 3}, {'title': '杜拉拉大结局', 'price': Decimal('32.00'), 'publish_id': 3, 'id': 6}, {'title': '百年孤独', 'price': Decimal('39.50'), 'publish_id': 4, 'id': 7}]> >>> Book.objects.filter(price__lt=50).exclude(price__gt=60) <QuerySet [<Book: python红宝书>, <Book: 杜拉拉大结局>, <Book: 百年孤独>]> >>> Book.objects.filter(price__lt=50).exclude(id=6) <QuerySet [<Book: python红宝书>, <Book: 百年孤独>]> >>> Book.objects.all().order_by('price') <QuerySet [<Book: python红宝书>, <Book: 杜拉拉大结局>, <Book: 百年孤独>, <Book: C语言>, <Book: php>, <Book: python>, <Book: C++>]> >>> Book.objects.all().reverse() <QuerySet [<Book: python>, <Book: php>, <Book: python红宝书>, <Book: C语言>, <Book: C++>, <Book: 杜拉拉大结局>, <Book: 百年孤独>]> >>> Book.objects.all().distinct() <QuerySet [<Book: python>, <Book: php>, <Book: python红宝书>, <Book: C语言>, <Book: C++>, <Book: 杜拉拉大结局>, <Book: 百年孤独>]> >>> Book.objects.all().values_list() <QuerySet [(1, 'python', 1, Decimal('78.00')), (2, 'php', 2, Decimal('54.00')), (3, 'python红宝书', 4, Decimal('8.00')), (4, 'C语言', 2, Decimal('50.00')), (5, 'C++', 1, Decimal('78.00')), (6, '杜拉拉大结局', 3, Decimal('32.00')), (7, '百年孤独', 4, Decimal('39.50'))]> >>> Book.objects.all().count() 7 >>> Book.objects.all().first() <Book: python> >>> Book.objects.all().last() <Book: 百年孤独> >>> Book.objects.all().exists() True
扩展查询:
#扩展查询,有时候DJANGO的查询API不能方便的设置查询条件,提供了另外的扩展查询方法extra: #extra(select=None, where=None, params=None, tables=None,order_by=None, select_params=None (1) Entry.objects.extra(select={'is_recent': "pub_date > '2006-01-01'"}) (2) Blog.objects.extra( select=SortedDict([('a', '%s'), ('b', '%s')]), select_params=('one', 'two')) (3) q = Entry.objects.extra(select={'is_recent': "pub_date > '2006-01-01'"}) q = q.extra(order_by = ['-is_recent']) (4) Entry.objects.extra(where=['headline=%s'], params=['Lennon']) extra
惰性机制:
Book.objects.filter()或Book.objects.all()等只是返回一个QuerySet对象(查询结果集对象),并不会马上执行SQL,而是当调用QuerySet对象时才会执行SQL。
QuerySet特点:
<1>可迭代

<2>可切片

QuerySet的高效使用:
1 #<1>Django的queryset是惰性的 2 3 Django的queryset对应于数据库的若干记录(row),通过可选的查询来过滤。例如,下面的代码会得到数据库中 4 名字为‘Dave’的所有的人: 5 person_set = Person.objects.filter(first_name="Dave") 6 7 上面的代码并没有运行任何的数据库查询。你可以使用person_set,给它加上一些过滤条件,或者将它传给某个函数, 8 这些操作都不会发送给数据库。这是对的,因为数据库查询是显著影响web应用性能的因素之一。 9 10 #<2>要真正从数据库获得数据,你可以遍历queryset或者使用if queryset,总之你用到数据时就会执行sql. 11 为了验证这些,需要在settings里加入 LOGGING(验证方式) 12 13 obj=models.Book.objects.filter(id=3) 14 15 # for i in obj: 16 # print(i) 17 18 # if obj: 19 # print("ok") 20 21 #<3>queryset是具有cache的 22 当你遍历queryset时,所有匹配的记录会从数据库获取,然后转换成Django的model。这被称为执行(evaluation). 23 这些model会保存在queryset内置的cache中,这样如果你再次遍历这个queryset,你不需要重复运行通用的查询。 24 obj=models.Book.objects.filter(id=3) 25 26 # for i in obj: 27 # print(i) 28 29 # for i in obj: 30 # print(i) #LOGGING只会打印一次 31 32 33 #<4> 34 简单的使用if语句进行判断也会完全执行整个queryset并且把数据放入cache,虽然你并不需要这些数据! 35 为了避免这个,可以用exists()方法来检查是否有数据: 36 37 obj = Book.objects.filter(id=4) 38 # exists()的检查可以避免数据放入queryset的cache。 39 if obj.exists(): 40 print("hello world!") 41 42 #<5>当queryset非常巨大时,cache会成为问题 43 44 处理成千上万的记录时,将它们一次装入内存是很浪费的。更糟糕的是,巨大的queryset可能会锁住系统进程,让你的 45 程序濒临崩溃。要避免在遍历数据的同时产生queryset cache,可以使用iterator()方法来获取数据,处理完数据就 46 将其丢弃。 47 objs = Book.objects.all() 48 # iterator()可以一次只从数据库获取少量数据,这样可以节省内存 49 for obj in objs.iterator(): 50 print(obj.name) 51 当然,使用iterator()方法来防止生成cache,意味着遍历同一个queryset时会重复执行查询。所以使用iterator() 52 的时候要当心,确保你的代码在操作一个大的queryset时没有重复执行查询 53 54 总结: 55 queryset的cache是用于减少程序对数据库的查询,在通常的使用下会保证只有在需要的时候才会查询数据库。 56 使用exists()和iterator()方法可以优化程序对内存的使用。不过,由于它们并不会生成queryset cache,可能 57 会造成额外的数据库查询。
对象查询、单表条件查询、多表条件关联查询:
1 #--------------------对象形式的查找-------------------------- 2 # 正向查找 3 ret1=models.Book.objects.first() 4 print(ret1.title) 5 print(ret1.price) 6 print(ret1.publisher) 7 print(ret1.publisher.name) #因为一对多的关系所以ret1.publisher是一个对象,而不是一个queryset集合 8 9 # 反向查找 10 ret2=models.Publish.objects.last() 11 print(ret2.name) 12 print(ret2.city) 13 #如何拿到与它绑定的Book对象呢? 14 print(ret2.book_set.all()) #ret2.book_set是一个queryset集合 15 16 #---------------了不起的双下划线(__)之单表条件查询---------------- 17 18 # models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值 19 # 20 # models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据 21 # models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in 22 # 23 # models.Tb1.objects.filter(name__contains="ven") 24 # models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感 25 # 26 # models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and 27 # 28 # startswith,istartswith, endswith, iendswith, 29 30 #----------------了不起的双下划线(__)之多表条件关联查询--------------- 31 32 # 正向查找(条件) 33 34 # ret3=models.Book.objects.filter(title='Python').values('id') 35 # print(ret3)#[{'id': 1}] 36 37 #正向查找(条件)之一对多 38 39 ret4=models.Book.objects.filter(title='Python').values('publisher__city') 40 print(ret4) #[{'publisher__city': '北京'}] 41 ret5=models.Book.objects.filter(publisher__address='北京').values('publisher__name') 42 print(ret5) #[{'publisher__name': '人大出版社'}, {'publisher__name': '人大出版社'}] 43 44 #正向查找(条件)之多对多 45 ret6=models.Book.objects.filter(title='Python').values('author__name') 46 print(ret6) 47 ret7=models.Book.objects.filter(author__name="alex").values('title') 48 print(ret7) 49 50 # 反向查找(条件) 51 52 #反向查找之一对多: 53 ret8=models.Publisher.objects.filter(book__title='Python').values('name') 54 print(ret8)#[{'name': '人大出版社'}] 注意,book__title中的book就是Publisher的关联表名 55 56 ret9=models.Publisher.objects.filter(book__title='Python').values('book__authors') 57 print(ret9)#[{'book__authors': 1}, {'book__authors': 2}] 58 59 #反向查找之多对多: 60 ret10=models.Author.objects.filter(book__title='Python').values('name') 61 print(ret10)#[{'name': 'alex'}, {'name': 'alvin'}]
>>> Publisher.objects.filter(book__price__gt=50).values('book__title') <QuerySet [{'book__title': 'python'}, {'book__title': 'php'}, {'book__title': 'C++'}]>
聚合查询和分组查询:
<1> aggregate(*args,**kwargs)
from django.db.models import Avg,Min,Sum,Max 从整个查询集生成统计值。比如,你想要计算所有在售书的平均价钱。Django的查询语法提供了一种方式描述所有 图书的集合。 >>> Book.objects.all().aggregate(Avg('price')) {'price__avg': 34.35} aggregate()子句的参数描述了我们想要计算的聚合值,在这个例子中,是Book模型中price字段的平均值 aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的 标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定 一个名称,可以向聚合子句提供它: >>> Book.objects.aggregate(average_price=Avg('price')) {'average_price': 34.35} 如果你也想知道所有图书价格的最大值和最小值,可以这样查询: >>> Book.objects.aggregate(Avg('price'), Max('price'), Min('price')) {'price__avg': 34.35, 'price__max': Decimal('81.20'), 'price__min': Decimal('12.99')}
<2> annotate(*args,**kwargs)
可以通过计算查询结果中每一个对象所关联的对象集合,从而得出总计值(也可以是平均值或总和),即为查询集的每一项生成聚合。
查询alex出的书总价格

查询各个作者出的书的总价格,这里就涉及到分组了,分组条件是authors__name

查询各个出版社最便宜的书价是多少

F查询和Q查询:
1 # F 使用查询条件的值,专门取对象中某列值的操作 2 3 # from django.db.models import F 4 # models.Tb1.objects.update(num=F('num')+1) 5 6 7 # Q 构建搜索条件 8 from django.db.models import Q 9 10 #1 Q对象(django.db.models.Q)可以对关键字参数进行封装,从而更好地应用多个查询 11 q1=models.Book.objects.filter(Q(title__startswith='P')).all() 12 print(q1)#[<Book: Python>, <Book: Perl>] 13 14 # 2、可以组合使用&,|操作符,当一个操作符是用于两个Q的对象,它产生一个新的Q对象。 15 Q(title__startswith='P') | Q(title__startswith='J') 16 17 # 3、Q对象可以用~操作符放在前面表示否定,也可允许否定与不否定形式的组合 18 Q(title__startswith='P') | ~Q(pub_date__year=2005) 19 20 # 4、应用范围: 21 22 # Each lookup function that takes keyword-arguments (e.g. filter(), 23 # exclude(), get()) can also be passed one or more Q objects as 24 # positional (not-named) arguments. If you provide multiple Q object 25 # arguments to a lookup function, the arguments will be “AND”ed 26 # together. For example: 27 28 Book.objects.get( 29 Q(title__startswith='P'), 30 Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)) 31 ) 32 33 #sql: 34 # SELECT * from polls WHERE question LIKE 'P%' 35 # AND (pub_date = '2005-05-02' OR pub_date = '2005-05-06') 36 37 # import datetime 38 # e=datetime.date(2005,5,6) #2005-05-06 39 40 # 5、Q对象可以与关键字参数查询一起使用,不过一定要把Q对象放在关键字参数查询的前面。 41 # 正确: 42 Book.objects.get( 43 Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)), 44 title__startswith='P') 45 # 错误: 46 Book.objects.get( 47 question__startswith='P', 48 Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)))
原生SQL的用法:
http://www.cnblogs.com/lijintian/p/6100097.html
附录 Django命令行工具
django-admin.py 是Django的一个用于管理任务的命令行工具,manage.py是对django-admin.py的简单包装,每一个Django Project里都会有一个mannage.py。
1 django-admin.py startproject project_name
创建一个新的django工程。
2 python manage.py startapp app_name
创建一个应用。
3 python manage.py runserver 8080
启动django项目。
4 python manage.py makemigrations
migrations目录下生成同步数据库的脚本。
同步数据库:python manage.py migrate
5 python manage.py createsuperuser
创建超级管理员,设置用户名和密码。当我们访问http://http://127.0.0.1:8080/admin/时,便可以通过超级管理员用户登录了。
6 python manage.py flush
清空数据库。
7 django-admin.py help startapp
查询某个命令的详细信息。
8 python manage.py shell
启动交互界面。
9 python manage.py
查看django提供的命令。