scrapy提供了一个强大的工具类ItemLoader,本文通过一个实例介绍一些常用用法。
以链家的一个具体房源为目标,页面大概长这样的
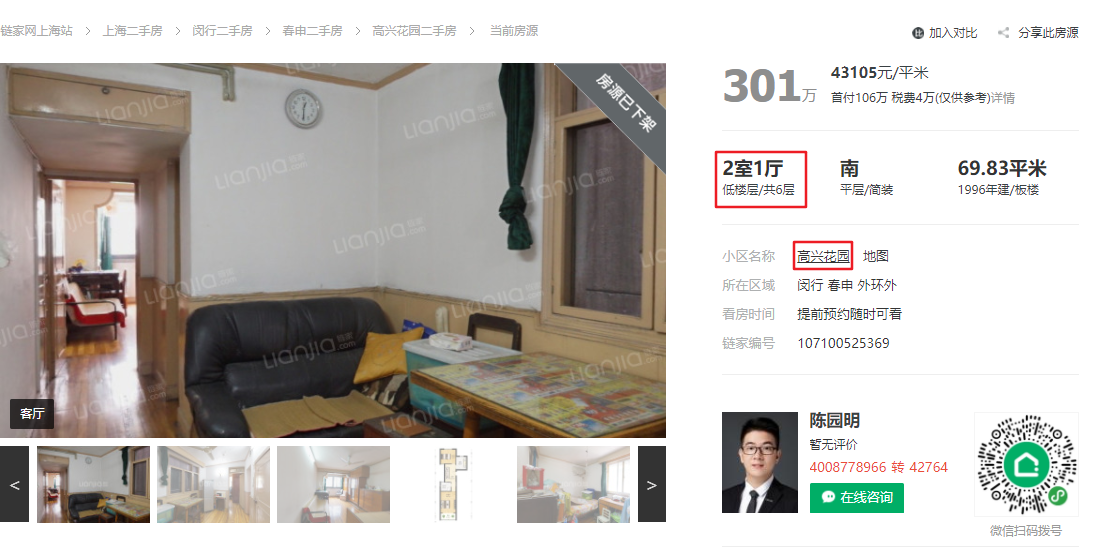
我们的目标是提取出红框中的信息。
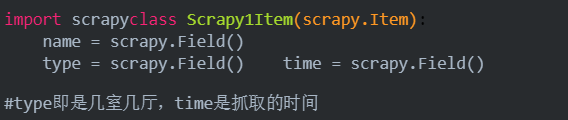
编写items
编写spider

ItemLoader有三个常用的函数,add_xpath,add_css,add_value,前面两个功能类似,第一个参数是抓取信息的名字,第二个参数是xpath或css表达式,第二和第三个add_xpath都是type字段,会将第二个抓取到的信息放到第一个后面。add_value第二个参数把值赋给第一个参数名称,这里以时间为值。且后面可以加正则表达式,如注释那一行所写。
运行结果如下:

type是一个有两个元素的列表,如何把两个元素合并起来,在很多电商网站会将商品价格拆分为多个,合并是很有必要的。
只需在items文件的Scrapy1Item类中修改为下面这种形式
from scrapy.loader.processors import Join
type = scrapy.Field(output_processor=Join())导入Join函数,定义output_processor即可。
运行结果:

ItemLoader抓取到的是一个列表,我们可以重定义一个Item类,取列表中的第一个元素。
在items文件中再创建一个类:
from scrapy.loader.processors import TakeFirst
class TeItem(ItemLoader):
default_output_processor = TakeFirst()
TakeFirst即是指取第一个不为空的元素。在spiders中要导入这个类,并实例化ItemLoader时用TeItem类:
sel = ItemLoader(item= Scrapy1Item(),response=response)
大家看到这里会有一点懵,什么output_processor之类的会不太理解,下篇文章介绍数据清洗,将会对此进行解释。
大家可以去我的公众号看一看,里面最新发布新闻章,而且排版,代码支持的相对博客要好一些。
