上一篇介绍了一些关于items进行数据清洗的一些用法,本章介绍scrapy中的pipelines的用法,pipelines一般是用来将爬取到的数据持久化。里面有几个常用的函数:
1.常用功能
class testPipeline(object):
def __init__(self):
"""
初始化一些事情,例如打开文件,写入表头,只运行一次
"""
pass
def process_item(self,item,spider):
"""
这个方法被每个item pipeline组件调用,并且必须返回
"""
return item
def open_spider(self,spider):
"""
爬虫开启时运行
"""
def close_spider(self,spider):
"""
爬虫关闭时运行
"""
@classmethod
def from_crawler(cls,crawler):
'''
当调用类方法时,会生成一个pipeline的实例,
也必须返回一个pipeline实例
比如得到settings文件中的mysql登录的端口号
val = crawler.settings.get("MYSQL_HOST")
return cls(val)
'''
上面几个函数都有spider参数,spider有name属性,是爬虫的名字,当一个文件里有多个spider和多个Pipeline类时可以通过这个来确保spider与Pipeline类对应起来。
2.DropItem
from scrapy.exceptions import DropItem
if item['price'] == ' ':
DropItem()
如果抓取到的房子价格为空,就可以用此方法丢掉。
当有多个pipeline类时,抓取的数据会按照优先级传递数据,这时也可以在return item前加上raise Dropitem()便不会向下一级传递item。
3.settings
写好pipelines后一定不要忘记在settings中进行设置
ITEM_PIPELINES = {
'scrapy1.pipelines.TestPipele': 300,
}
后面的数字从0到1000,数值越小优先级越高
scrapy也提供了很多方便的文件输出,例如在命令行下
scrapy runspider test.py -o test_data.csv
而且还提供了CsvItemExporter的类,我还没有搞懂,等明白了再分享出来。
4.ImagesPipeline
scrapy提高了图片的处理管道,在系列文章破冰中也简单运用了一下,若想做一些高级功能,还需对类中的方法进行重写。三个重要的方法:
1.get_media_requests(self, item, info)
2.file_path(self, request, response=None, info=None)
依旧对丫丫女神进行抓取:

这是四个图集,红框是等会要用来命名文件夹名称的,要进入图集后里面会有若干图片。
class ImagedowPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for img_url in item['image']:
yield Request(img_url, meta={'item':item})
#将图片链接交给Request,item传递给file_path函数
def file_path(self, request, response=None, info=None):
item = request.meta['item']
folder_name = item['name']
#接收传过来的item
filename = '{0}//{1}'.format(folder_name, str(random.random()))+".jpg"
#文件夹名称是红框里的信息,每个图片是用随机数命名
return filename
迫不及待运行......
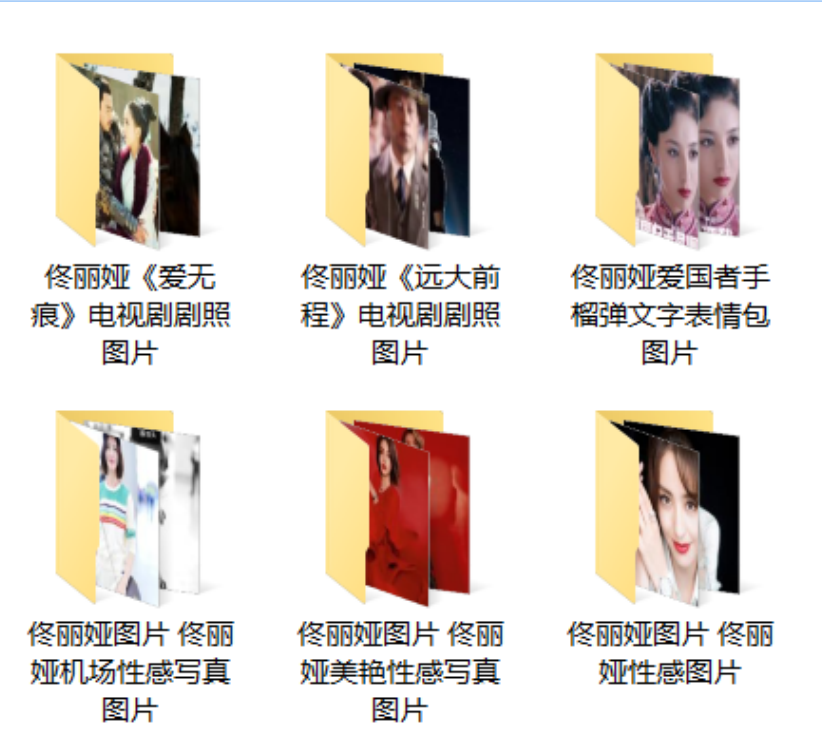
放上部分文件夹,是不是感觉很棒
若想了解更多过程,关注公众号,回复丫丫源码即可。
若想拿到高清大图,自己动手,丰衣足食。
