基础知识
class scrapy.spiders.CrawlSpider
这是抓取一般网页最常用的类,除了从Spider继承过来的属性外,其提供了一个新的属性rules,它提供了一种简单的机制,能够为将要爬取的链接定义一组提取规则。
rules
这是一个Rule对象列表,每条规则定义了爬取网站链接的行为,如果一条链接命中多条规则,以第一条规则进行匹配,顺序由属性中定义的顺序决定。
Link Extractors
Link Extractors 是用于从网页(scrapy.http.Response )中抽取会被follow链接的对象。 Scrapy 自带的Link Extractors类由scrapy.linkextractors模块提供,你可以这样直接导入from scrapy.linkextractors import LinkExtractor,也可以通过实现一个简单的接口来创建自己个性化的Link Extractor来满足需求。每个LinkExtractor都有唯一的公共方法是 extract_links ,其接收 一个 Response 对象, 并返回scrapy.link.Link 对象。 Link Extractors只实例化一次,其 extract_links 方法会根据不同的response被调用多次来提取链接。默认的link extractor 是 LinkExtractor ,其实就是 LxmlLinkExtractor,在以前版本的Scrapy版本中还提供了其他的link extractor,不过都已经被废弃了。
LxmlLinkExtractor
classscrapy.linkextractors.lxmlhtml.LxmlLinkExtractor(
allow=(),
deny=(),
allow_domains=(),
deny_domains=(),
deny_extensions=None,
restrict_xpaths=(),
restrict_css=(),
tags=(‘a’, ‘area’),
attrs=(‘href’, ),
canonicalize=True,
unique=True,
process_value=None
)
参数解释:
allow 只有匹配这个正则表达式(或正则表达式列表)的URL才会被提取。如果没有给出(或None) ,它会匹配所有的链接。
deny 匹配这个正则表达式(或正则表达式列表)的URL将会被排除在外(即不提取)。它的优先级高于allow参数,如果没有给出(或None) ,将不排除任何链接。
allow_domains 包含特定域名的字符串或字符串列表,表示允许从这里面提取链接
deny_domains 包含特定域名的字符串或字符串列表, 表示不允许从这里面提取链接
deny_extensions 提取链接时,忽略扩展名的列表。如果没有给出,默认为scrapy.linkextractor模块中定义的ignored_extensions列表。
restrict_xpaths 单个xpath表达式或xpath表达式列表,若不为空,则只使用该参数去提取URL,和allow共同作用过滤链接。
restrict_css 单个css选择器或者选择器列表,作用和restrict_xpaths一样
tags 提取链接时要考虑的标签或标签列表。默认为 ( ‘a’ , ‘area’)
attrs 提取链接时应该寻找的attrbitues列表(仅在 tags 参数中指定的标签)。默认为 (‘href’)。
canonicalize 是否标准化每个提取的URL,使用w3lib.url.canonicalize_url。默认为True。
unique 是否过滤提取过的URL,布尔类型
process_value 处理tags和attrs提取到的URL的函数,它能修改并返回一个新值。如果为空则默认是lambda x: x
Rule
classscrapy.spiders.Rule(
link_extractor,
callback=None,
cb_kwargs=None,
follow=None,
process_links=None,
process_request=None
)
参数解释:
link_extractor 是一个Link Extractor对象,定义怎样提取每个需要爬取的页面中的链接。
callback 是一个可调用方法或者一个字符串(spider类中用这个字符串命名的方法)会被每个指定的link_extractor 调用,这个方法的第一个参数是response必须返回一个item或者Request的list。
cb_kwargs 是一个包含关键字参数的字典,可以传递给callback函数。
follow 是一个布尔值,指定这些通过规则匹配出来的链接是否需要继续,如果callback是None,follow默认为False,否则follow是True。
process_links 是一个可调用方法或者一个字符串(spider类中用这个字符串命名的方法)会被每个指定的link_extractor调用,这个主要作用是过滤。
process_request 是一个可调用方法或者一个字符串(spider类中用这个字符串命名的方法)会被这个规则的每个request调用,必须返回一个request或者None。
SQLAlchemy
是python的一款开源软件,提供了SQL工具包及对象关系映射(ORM)工具(需要安装第三方库)。它的优点用一句话概括就是可以避免写繁复的sql语句.(隐藏数据库,良好的数据接口,动态的数据映射,引入缓存)具体请参考官方文档
Xpath
scrapy支持使用xpath表达式来提取数据。XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。 XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。起初XPath的提出的初衷是将其作为一个通用的、介于XPointer与XSL间的语法模型。但是XPath很快的被开发者采用来当作小型查询语言。具体可参考http://www.runoob.com/xpath/xpath-tutorial.html
实践
有了前面的知识和基本概念之后,下面就是写代码了,本文目标是使用CrawlSpider和sqlalchemy实现如下网站中的高匿代理IP采集入库http://ip84.com,新建项目和spider的过程我就不写了,不会的可以参考之前的文章,本次项目名称为”ip_proxy_pool”,顾名思义就是IP代理池,学习爬虫的应该都知道,不过本文仅仅是采集特定网站公开的代理IP,维护一个IP代理池那是后话,OK,Talk is cheap,Show you the code!
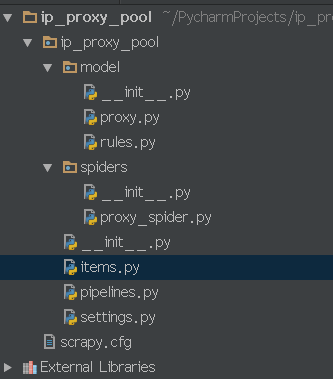
项目结构如上图所示,model目录存放数据库表的映射文件,proxy.py是目标表的映射文件,rules.py以及和model目录同级的__init__.py文件本文中暂时用不到先不管,其他文件都是本次实践需要用到的。
1.items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class IpProxyPoolItem(scrapy.Item):
ip_port = scrapy.Field()
type = scrapy.Field()
level = scrapy.Field()
country = scrapy.Field()
location = scrapy.Field()
speed = scrapy.Field()
source = scrapy.Field()
2.model目录下的__init__.py
# -*- coding: utf-8 -*-
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
# 创建对象的基类:
Base = declarative_base()
# 初始化数据库连接:
engine = create_engine('mysql+mysqldb://root:123456@localhost:3306/scrapy?charset=utf8')
#返回数据库会话
def loadSession():
Session = sessionmaker(bind=engine)
session = Session()
return session
3.proxy.py(数据库表proxies的映射文件)
# -*- coding: utf-8 -*-
from sqlalchemy import Column,String,Integer,DateTime
from . import Base
import datetime
class Proxy(Base):
__tablename__ = 'proxies'
ip_port=Column(String(30),primary_key=True,nullable=False)
type=Column(String(20),nullable=True)
level=Column(String(20),nullable=True)
location=Column(String(100),nullable=True)
speed=Column(Integer,nullable=True)
source = Column(String(500), nullable=False)
indate=Column(DateTime,nullable=False)
def __init__(self,ip_port,source,type=None,level=None,location=None,speed=None):
self.ip_port=ip_port
self.type=type
self.level=level
self.location=location
self.speed=speed
self.source=source
self.indate=datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
4.pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
from model import Base,engine,loadSession
from model import proxy
class IpProxyPoolPipeline(object):
#搜索Base的所有子类,并在数据库中生成表
Base.metadata.create_all(engine)
def process_item(self, item, spider):
a = proxy.Proxy(
ip_port=item['ip_port'],
type=item['type'],
level=item['level'],
location=item['location'],
speed=item['speed'],
source=item['source']
)
session = loadSession()
session.add(a)
session.commit()
return item
5.proxy_spider.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import IpProxyPoolItem
class ProxySpiderSpider(CrawlSpider):
name = 'proxy_spider'
allowed_domains = ['ip84.com']
start_urls = ['http://ip84.com/gn']
rules = (
#跟随下一页链接
Rule(LinkExtractor(restrict_xpaths="//a[@class='next_page']"),follow=True),
#对所有链接中含有"/gn/数字"的链接调用parse_item函数进行数据提取并过滤重复链接
Rule(LinkExtractor(allow=r'/gn/d+',unique=True), callback='parse_item'),
)
def parse_item(self, response):
print 'Hi, this is an item page! %s' % response.url
item=IpProxyPoolItem()
for proxy in response.xpath("//table[@class='list']/tr[position()>1]"):
ip=proxy.xpath("td[1]/text()").extract_first()
port=proxy.xpath("td[2]/text()").extract_first()
location1=proxy.xpath("td[3]/a[1]/text()").extract_first()
location2=proxy.xpath("td[3]/a[2]/text()").extract_first()
level=proxy.xpath("td[4]/text()").extract_first()
type = proxy.xpath("td[5]/text()").extract_first()
speed=proxy.xpath("td[6]/text()").extract_first()
item['ip_port']=(ip if ip else "")+":"+(port if port else "")
item['type']=(type if type else "")
item['level']=(level if level else "")
item['location']=(location1 if location1 else "")+" "+(location2 if location2 else "")
item['speed']=(speed if speed else "")
item['source']=response.url
return item
6.settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for ip_proxy_pool project
BOT_NAME = 'ip_proxy_pool'
SPIDER_MODULES = ['ip_proxy_pool.spiders']
NEWSPIDER_MODULE = 'ip_proxy_pool.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
ITEM_PIPELINES = {
'ip_proxy_pool.pipelines.IpProxyPoolPipeline': 300,
}
DOWNLOAD_DELAY = 2
7.运行spider,查看结果
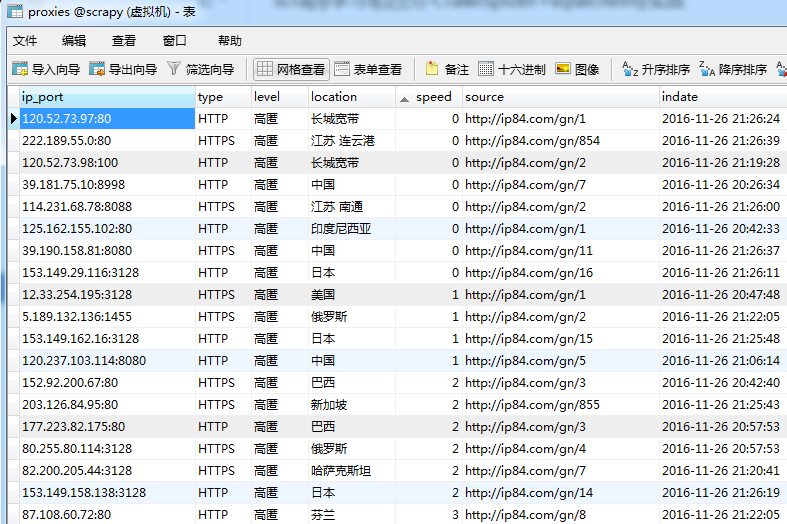
shell中执行scrapy crawl proxy_spider,发现数据库中已经自动生成了表proxies并且数据已经入库,Done!