本文首发于公众号「Python知识圈」,如需转载,请在公众号联系作者授权。
2019年发现两个有意思而且内容比较硬核的公众号。都是同一个人运营的,我们都叫他半佛老师,现实中的职业是风控,公众号内容涉及揭秘灰产的一些坑和硬核科普。文章内容硬核外,再配上大量的沙雕表情包。让整个文章非常有趣。不到一年,两个公众号,每篇文章都有10w+ 的阅读量。19 年年底。半佛老师入驻了 B 站。制作的 B 站视频文案上也和公众号文章一样硬核,配上大量的沙雕表情包。让看视频的读者有时候看着表情包在那里傻笑(包括我),目前 B 站 327 万粉,相当的硬核。

就这样,每天有大量的读者在半佛老师的公众号和 B 站之间来回横向跳动。
说了这么多,今天这篇文章不是给半佛老师打广告的。我仅仅只是我馋他的表情包了。所以今天我用爬虫批量的保存半佛老师公众号文章里面所有的沙雕表情包。
周末在 B 站发了一个保存半佛老师的骚表情包的视频,目前播放量 12万,8000+点赞,大家可以点击文末「阅读原文」直达视频页面。

半佛老师有两个公众号。据我观察,仙人jump 公众号的表情包相对来说多一些。所以今天就以这个公众号为目标。来批量保存里面的沙雕图片或者表情包。

单篇文章表情包爬取
首先。我们要学会爬取一篇文章里面所有的表情包或者图片。比如我们指定一篇文章,打开文章,查看页面源代码。
通过简单查找,我们就可以看到。文章的图片都在date-src后面。

我们用正则表达式去提取这些链接。所有的链接都提取出来,以列表的形式返回。
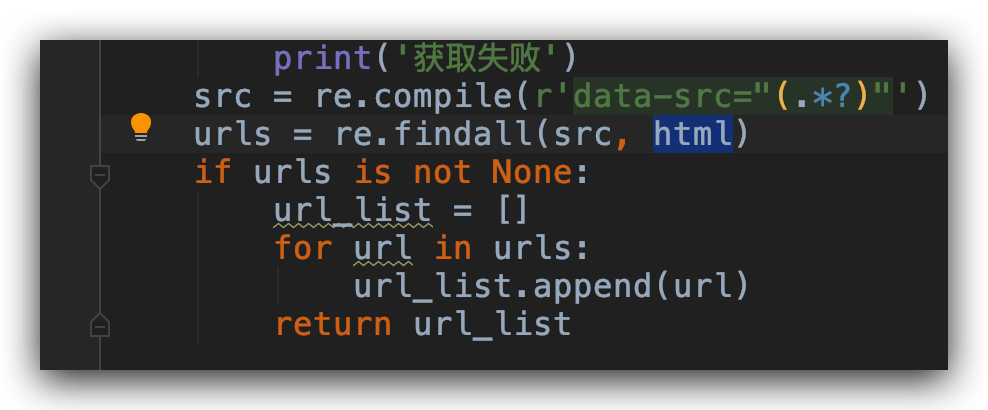
然后我们需要写一个下载图片的方法。
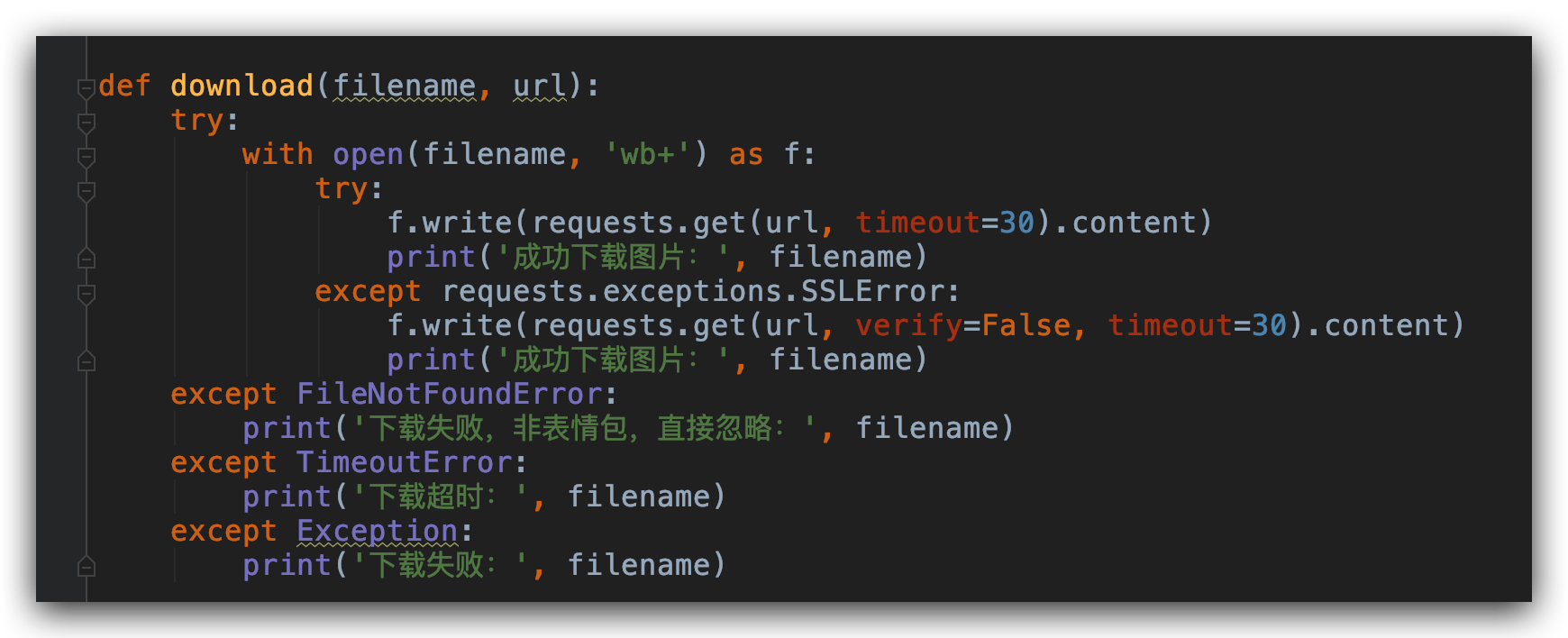
这样我们用一个for循环就可以把这篇文章里面所有的表情包或者图片全部下载下来了。
所有文章表情包爬取
接下来第2步。我们是需要保存一个公众号所有文章里面所有的表情包或者图片,所以这一步我们需要获取这个公众号所有文章的链接地址。之前我也写过一篇文章,将一个公众号里面所有文章的链接和标题全部爬取下来:拒绝低效!Python教你爬虫公众号文章和链接
我们通过 Charles 抓包,直接抓取电脑 PC 端公众号。
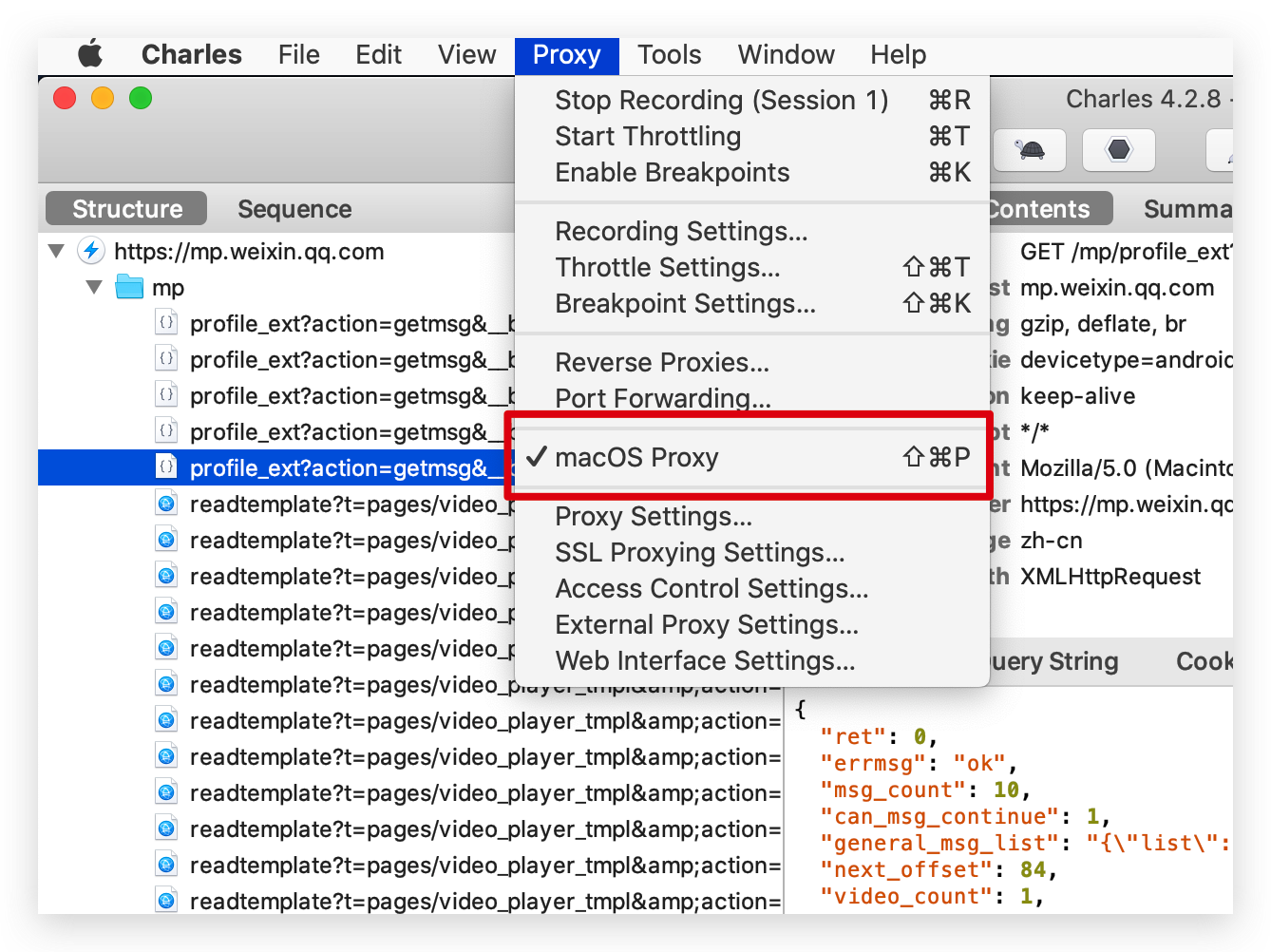
我们通过上滑公众号历史文章,在抓取的链接里面我们可以看到请求和具体的返回数据。它的返回是以 Json 信息的形式。文章的链接就在 Json 信息里面。

这个 Json 看不全,我们复制到在线 json 解析工具里转换一下。

分析请求数据我们发现。链接里面除了 offset 是变化的,其他都是不变的。

用 requests 库请求链接的话,我们是需要给出 headers 信息和 cookies 信息的,笨办法的话,我们可以手动在请求头 Headers 里面找,然后复制过来。这里教大家一个非常简单的方法,我们直接右键,选择 Copy Curl Request。

复制完之后,我们放在转换地址里面。
https://curl.trillworks.com/
在左边粘贴刚才复制的 curl request,下面的语言默认是 Python。右边就会同步转换为 Python requests。
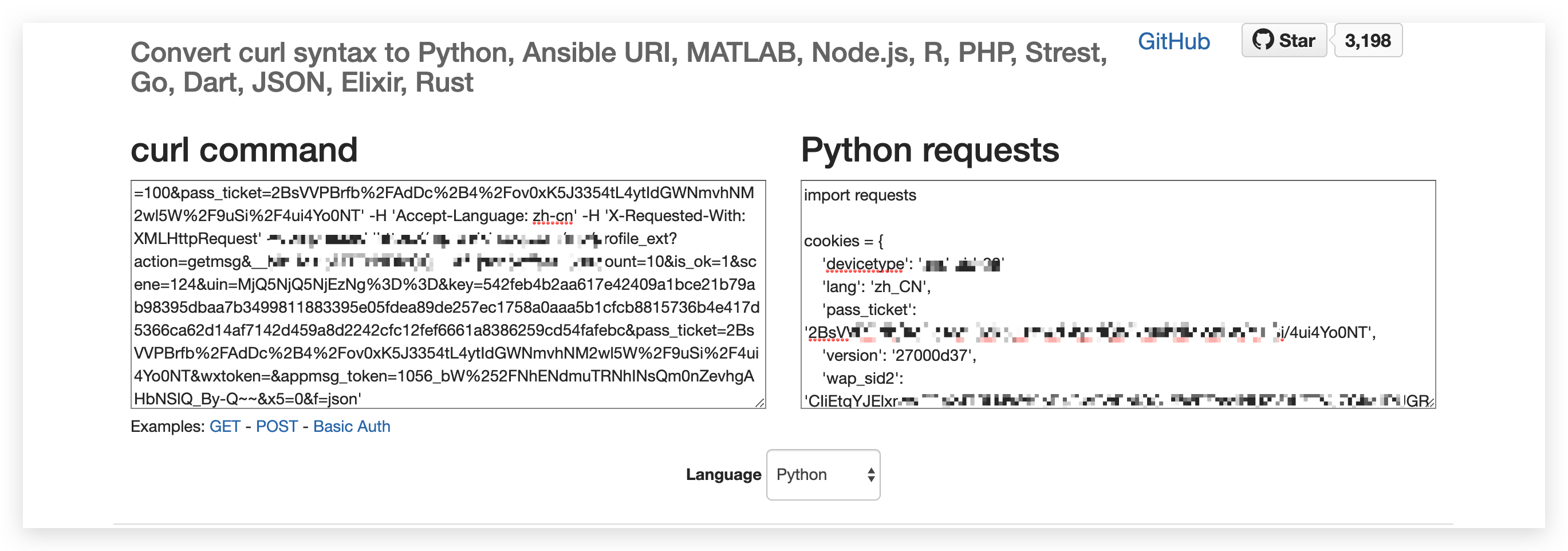
我们把右边的 Python requests 直接复制到编辑器里面就可以了。内容包括 hearders 信息和 cookies 信息,还有对应的参数,这样就避免我们对 cookies 和 headers 一个个去粘复制粘贴。这样是不是比较方便和简单!
这里有个地方注意下,复制过来的 params 里面有两个值需要去掉,offset 和 count。
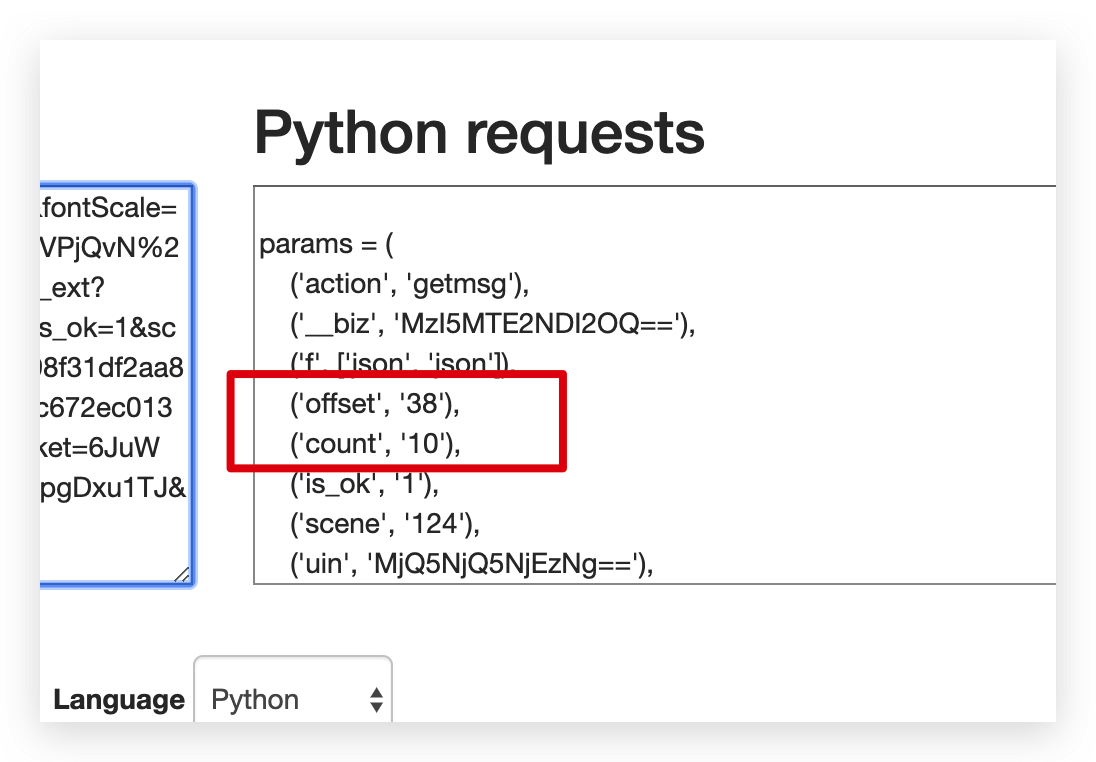
因为 offset 我需要把它做成动态的,我把它们放在了开头的基础链接里。

通过 requests 库请求我们就可以获取返回的 Json 信息。然后我们提取 Json 信息里面的文章链接,为了全部获取所有文章。offset 值我们需要放在 range 里面,以 10 的步数往上增长, offset 最大值是多少呢?我们可以通过抓包获取,把公众号文章一直上滑到底,也就是滑动公众号的第 1 篇文章,我们点击这个请求,就可以看到里面的offset值。
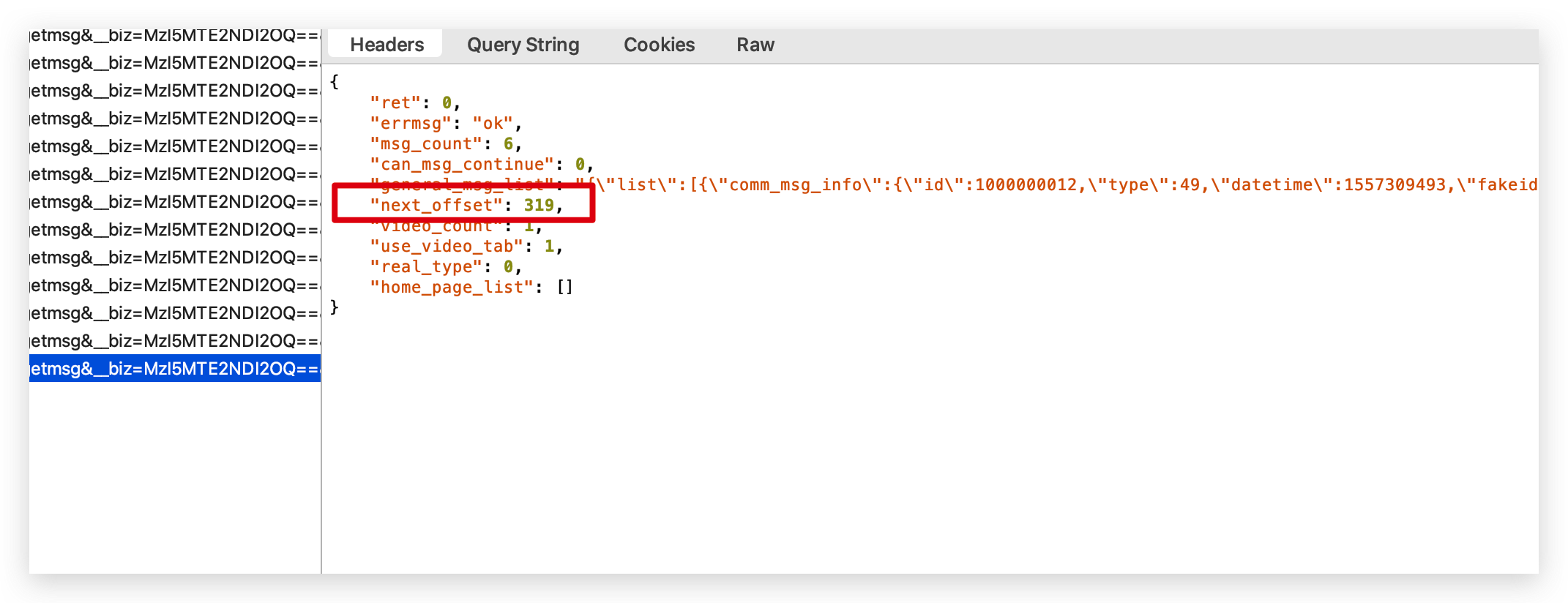
把这个值放在 range 值里。

这样的话,这个公众号所有的文章链接,我都以列表的形式返回。返回给之前第 1 步操作的爬取单篇文章所有图片。通过两个循环,公众号下面所有文章里面的所有表情包或者图片都可以批量下载下来。

这样,虽然我没有半佛老师任何的文案,但是我有他硬核而且沙雕的表情包。
总结下:
1、运行代码前抓包通过 Copy Curl Request 到转换工具里获取 headers、cookies、和 params 替换掉我代码中的 headers 相关信息,并把 params 中 offset 和 count 去掉。
2、代码请求里加了代理ip proxy,如果运行报 pxoxy 相关的错,请自行去西刺代理ip更换一个(https://www.xicidaili.com/)免费的。
3、点击阅读原文直达这个项目的 B 站视频版,目前 12万播放量了,有账号的伙伴来个三连加关注啊。
在本公众号后台回复「表情包」获取本文所有的代码。
欢迎关注公众号「Python知识圈」,公众号后台回复关键字,获取更多干货。
回复「英语」:送你英语 7000 单词速记法,亲测非常有效。
回复「编程」:免费获赠2019最新编程资料,认真学完BAT offer 拿到手软。
回复「赚钱」:领取简单可实操的 36 个赚钱的小项目,每天多赚100块零花钱。