
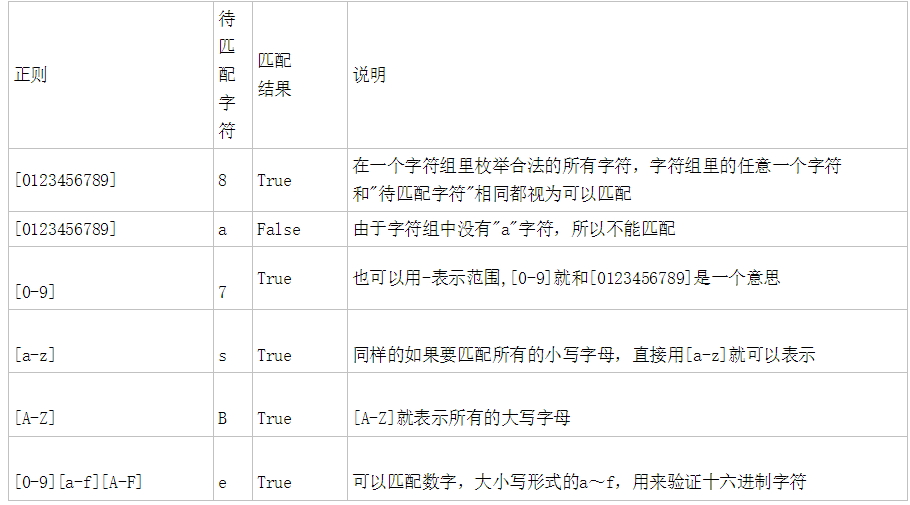

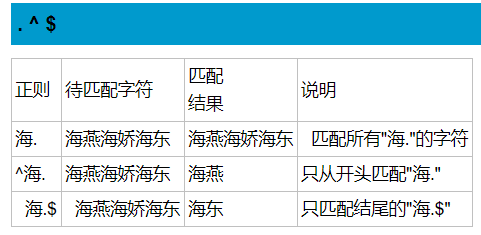

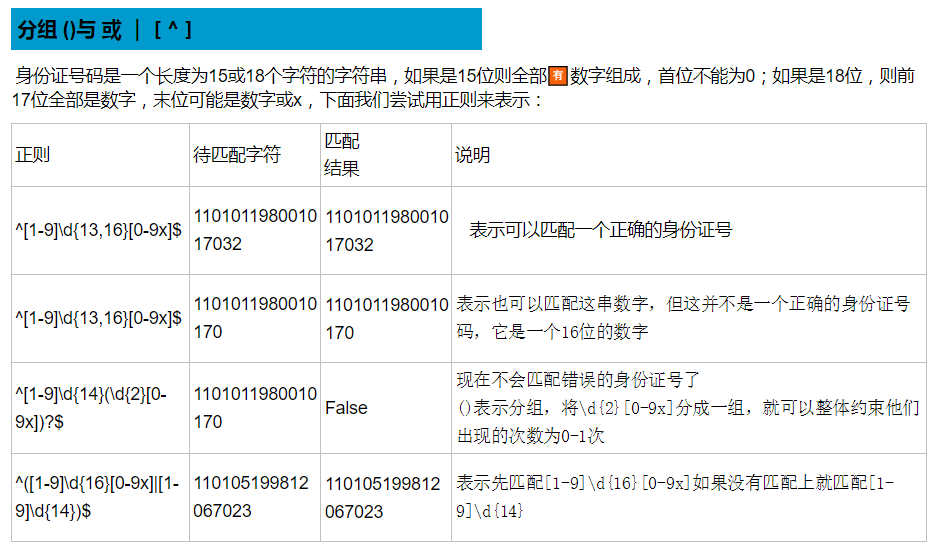


re模块下的常用方法


import re ret = re.findall('a', 'eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里 print(ret) #结果 : ['a', 'a'] ret = re.search('a', 'eva egon yuan').group() print(ret) #结果 : 'a' # 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以 # 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 ret = re.match('a', 'abc').group() # 同search,不过尽在字符串开始处进行匹配 print(ret) #结果 : 'a' ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割 print(ret) # ['', '', 'cd'] ret = re.sub('d', 'H', 'eva3egon4yuan4', 1)#将数字替换成'H',参数1表示只替换1个 print(ret) #evaHegon4yuan4 ret = re.subn('d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次) print(ret) obj = re.compile('d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串 print(ret.group()) #结果 : 123 import re ret = re.finditer('d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器 print(ret) # <callable_iterator object at 0x10195f940> print(next(ret).group()) #查看第一个结果 print(next(ret).group()) #查看第二个结果 print([i.group() for i in ret]) #查看剩余的左右结果
import requests import re import json def getPage(url): response=requests.get(url) return response.text def parsePage(s): com=re.compile('<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>d+).*?<span class="title">(?P<title>.*?)</span>' '.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',re.S) ret=com.finditer(s) for i in ret: yield { "id":i.group("id"), "title":i.group("title"), "rating_num":i.group("rating_num"), "comment_num":i.group("comment_num"), } def main(num): url='https://movie.douban.com/top250?start=%s&filter='%num response_html=getPage(url) ret=parsePage(response_html) print(ret) f=open("move_info7","a",encoding="utf8") for obj in ret: print(obj) data=json.dumps(obj,ensure_ascii=False) f.write(data+" ") if __name__ == '__main__': count=0 for i in range(10): main(count) count+=25
collections模块
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
>>> from collections import namedtuple >>> Point = namedtuple('Point', ['x', 'y']) >>> p = Point(1, 2) >>> p.x 1 >>> p.y 2
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
from collections import deque >>> q = deque(['a', 'b', 'c']) >>> q.append('x') >>> q.appendleft('y') >>> q deque(['y', 'a', 'b', 'c', 'x'])
3.Counter: 计数器,主要用来计数
c = Counter('abcdeabcdabcaba') print c 输出:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
其他详细内容 http://www.cnblogs.com/Eva-J/articles/7291842.html
4.OrderedDict: 有序字典
>>> from collections import OrderedDict >>> d = dict([('a', 1), ('b', 2), ('c', 3)]) >>> d # dict的Key是无序的 {'a': 1, 'c': 3, 'b': 2} >>> od = OrderedDict([('a', 1), ('b', 2), ('c', 3)]) >>> od # OrderedDict的Key是有序的 OrderedDict([('a', 1), ('b', 2), ('c', 3)])
5.defaultdict: 带有默认值的字典
>>> from collections import defaultdict >>> dd = defaultdict(lambda: 'N/A') >>> dd['key1'] = 'abc' >>> dd['key1'] # key1存在 'abc' >>> dd['key2'] # key2不存在,返回默认值 'N/A'