在智能司法领域,法律判决文件的分析和挖掘已成为计算方法研究的热点。当前,许多公开的判决文件都以长篇幅发布,其内容主要包括案件编号,当事人,案件起因,审判程序,判决结果,判决标准等。即使在现场,呈现也很长且复杂。对于工作人员而言,阅读判决文件以快速准确地了解案件要点是一项复杂而耗时的任务。因此,利用人工智能技术快速准确地分解判断文档并构造文档中的重要信息已成为大数据时代司法领域的迫切需求之一。
2020年“路易斯杯”全国大学法律科学技术创新大赛是面向全国大学的高级别法律科学技术创新大赛。在本文中,我们将介绍冠军队采用的技术解决方案。该解决方案的优势在于它基于Bydo Flying Paddle Platform,使用ERNIE作为预训练模型,并使用“序列分类”作为完成竞争性项目计划的关键思想。该程序最终以F1 = 91.991赢得第一名。这比基线分数高3.267。
赛题分析
在挖掘信息和分析判决文件的众多问题中,由于判断结果的重要性和算法设计的困难,“分析法律要素与当事人之间关系的问题”来自法律科学技术研究人员。它越来越受到关注。例如,“多人多罪”是司法界一种相对普遍的现象,在司法界,个人需要判断不同的罪行。在本主题中,您需要使用模型和算法来确定输入文本,合法元素和各方的匹配以及当前输入文本中合法元素与各方之间的对应关系。 ..比赛的主题是“分析法律要素与当事方之间的关系”,其核心是根据所提供的信息确定要素是否与当事方匹配。
数据样例
这是数据示例,每个数据都包含上述字段。这些段落的内容直接来自公共法律文件,被告的收藏品是所有段落中提到的被告。语句是段落中的一个片段,其中包含要分析元素的原始表示。基于此已知信息,我们需要预测与元素名称相对应的被告。数据集中的所有正式文本均来自包含6,958个样本数据的官方法律文件。该模型的最终指标是宏平均F1(宏平均F1)。
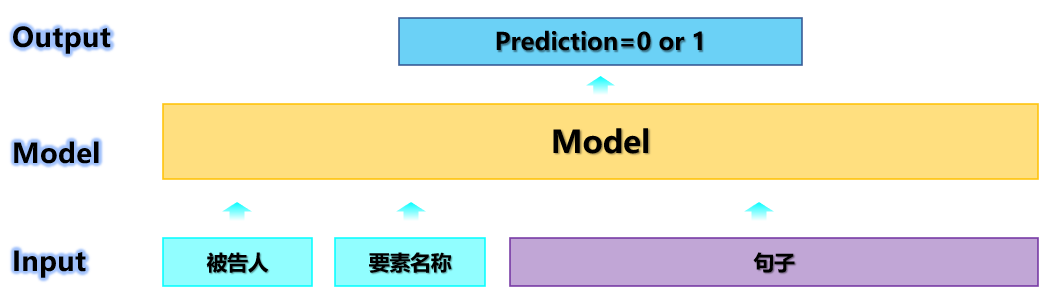
我们分析了官方基准程序。官方基准程序将此任务定义为NER,将语句的元素和原始值输入模型,并标记与语句元素的原始值相对应的人员姓名和模型结构。如图1所示。在此示例中,该语句包含多个名称(Zhao Mojia,Zhao Mo,Long),但是该模型仅标记Zhao Mojia,因为只有Zhao Mojia与特定元素相关联。 ..这种解决方案很难处理语句不包含人名或多个名字的情况。任务定义:如果语句没有名称或语句具有多个名称,则在“序列分类基准”方案中使用的NER表格效果较差,因此请组合给定的数据以重新考虑问题计划。做到了。考虑到数据中给出了一组被告,我们将比赛的任务重新定义为序列分类任务,如图2所示。输入被告,元素名称和句子,以确定输入的被告是否与特定元素名称相关联。如果相关,模型将预测1、否则将预测0。
模型描述
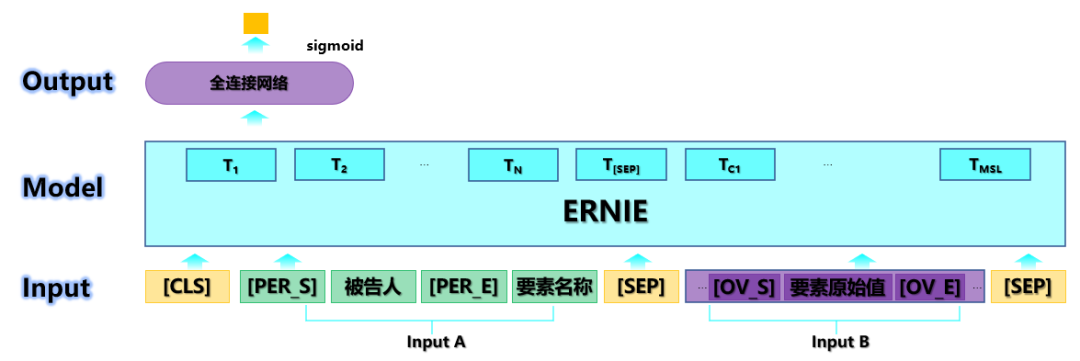
与BERT相比,ERNIE对中国实体更为敏感,因此此解决方案选择ERNIE作为主体。为了使输入与ERNIE的预训练方法更加一致,如图3所示,此解决方案使用被告和元素名称作为输入句子A,将句子作为句子B。 ..将CLS位置的隐藏状态连接到完全连接的网络,然后使用Sigmoid函数将logit压缩为0到1、为了增强信息的重要部分,在被告原始值的两端分别添加了四个特殊标记[PER_S]和[PER_E],以指示句子中“被告(人)”的开头和结尾。添加。 [OVS]和[OVE]分别表示“元素Ovalue”的开始和结束。希望该模型将学习此范例,并更多地关注这两部分信息。
class ErnieForElementClassification(ErnieModel): def __init__(self, cfg, name=None): super(ErnieForElementClassification, self).__init__(cfg, name=name) initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range']) self.classifier = _build_linear(cfg['hidden_size'], cfg['num_labels'], append_name(name, 'cls'), initializer) prob = cfg.get('classifier_dropout_prob', cfg['hidden_dropout_prob']) self.dropout = lambda i: L.dropout(i, dropout_prob=prob, dropout_implementation="upscale_in_train",) if self.training else i @add_docstring(ErnieModel.forward.__doc__) def forward(self, *args, **kwargs): labels = kwargs.pop('labels', None) pooled, encoded = super(ErnieForElementClassification, self).forward(*args, **kwargs) hidden = self.dropout(pooled) logits = self.classifier(hidden) logits = L.sigmoid(logits) sqz_logits = L.squeeze(logits, axes=[1]) if labels is not None: if len(labels.shape) == 1: labels = L.reshape(labels, [-1, 1]) part1 = L.elementwise_mul(labels, L.log(logits)) part2 = L.elementwise_mul(1-labels, L.log(1-logits)) loss = - L.elementwise_add(part1, part2) loss = L.reduce_mean(loss) return loss, sqz_logits else: return sqz_logits
数据去噪
在野外实验阶段,以上述格式处理了由政府提供的6958个官方数据(train.txt),获得了31030个新数据,训练集和测试集的比例为8:2、我分开了。对官方数据的分析表明,一些特定的培训数据存在两个问题: (1)该句子不包含被告人的姓名(在句子中未找到被告人)(2)该句子不是该段落内容的一部分(该句子未在该段落中找到)。如果数据(1)有问题,则不能仅由给定的句子确定与元素名称相对应的被告,并且必须将句子放在段落中并基于前后。该信息将得到进一步的判断。如果数据同时具有问题(1)和(2),则基于数据提供的信息不足以确定该元素对应的被告。此解决方案将同时满足问题(1)和问题(2)的数据视为噪声数据,并且在训练过程中删除了这部分数据。在处理完下表中的数据集信息之后:

计划概述该计划将竞争任务重新定义为序列分类任务。该任务表使用直接确定元素名称和被告之间的关系所需的关键信息作为模型输入,并在关键信息中添加特殊符号。这是有效的。重要信息得到增强,模型决策的难度降低。对于训练数据,此解决方案消除了一些噪声数据。实验结果还表明,该操作可以提高模型的预测性能。在测试阶段,该程序在句子中没有被告的情况下采用正向拉伸方法。这种方法可以解决一些问题,但是在前一句中还没有包括被告的情况下效果不佳。同样,扩展该语句会增加输入序列的长度,并且输入序列的最大长度不能超过512、因此,此解决方案需要解决两种情况: (1)即使句子被向前扩展,被告也不包括在句子中。 (2)长输入序列(分词后超过1000个令牌)的改进上一节中总结的两个问题有以下解决方案,但是由于时间限制,它们并未完全实现。 ..以下是我们的想法:**(1)滑动窗口策略:**如果句子中未包含被告,请在句子前使用所有信息(或直接输入段落) ..以这种方式,输入序列的长度显着增加。此时,使用多个ERNIE 512窗口(步幅= 128)来滑动整个序列,如果不同的窗口重叠,则池将获得最终的隐藏状态。这打破了ERNIE 512输入长度限制。 (2)关键向量拼接:在滑动窗口策略中,输入序列增加后,相应的冗余信息也增加。因此,关于元素的被告和原始价值的信息得到进一步增强。现有的解决方案是在[CLS]位置使用最终的隐藏层矢量来连接完全连接的层并执行两个分类。最终的隐藏层矢量在[Defendant]和[Original Element Value]的每个标记位置平均,然后与[CLS]位置的矢量连接,以将原始768维矢量扩展到2304维。并将新向量用于两个分类。该项目基于Flying Paddle深度学习框架完成。作为初学者,首先接触过桨,在使用动态图形ERNIE代码的过程中,我体会到了它的独特魅力。这完全归功于百度为Paddle用户开发的详细用户手册和广泛的学习资料。当然,我还要感谢AI Studio提供的GPU计算资源。 AIStudio提供了训练和评估模型的必要条件。