作为机器学习实践中分类领域下的一个模块,多分类问题建模也是生产生活应用中的重要组成部分;在模型构建完成之后,对多分类模型的评估影响到后期的模型决策甚至是机器学习解决方案的实际应用效果。
准确有效评估多分类模型的性能,有利于我们建立起对当前模型水平的正确认识;由此,本文着重探讨几种常用的多分类模型评估指标。
二分类评估指标基础
在谈及多分类评估指标之前,首先回顾几个常见的二分类建模评估指标:
True Positive (TP):正样本预测为正;
True Negative (TN):负样本预测为负;
False Positive (FP):负样本预测为正;
False Negative (FN):正样本预测为负;
在上述四个指标之上建立的精确率、召回率以及F1值定义如下:
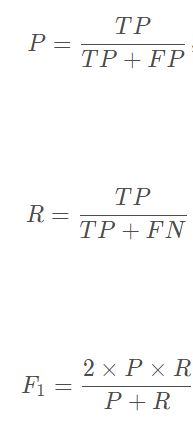
多分类评估指标之宏F1(macro-F1)
类比于二分类评估指标,计算出各类别的精确率、召回率,然后求上述精确率和召回率的均值,再按定义求出macro-F1,如下图(图中n表示类别数):
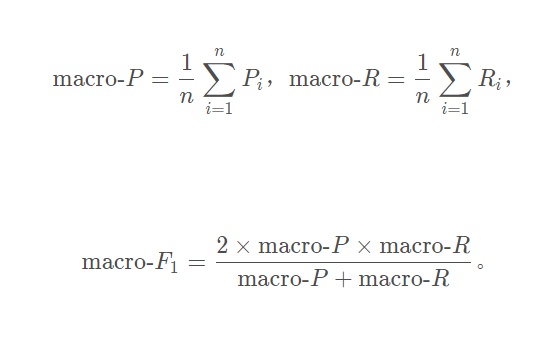
当然,另有一派计算macro-F1的公式,即求取各类别F1值的均值,如下图(图中n表示类别数):
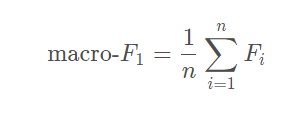
多分类评估指标之微F1(micro-F1)
micro-F1的计算同样用到各类别的有关指标均值,即算出各类别的TP、FP、TN、FN后再计算这四个指标的均值,然后按定义计算精确率、召回率和micro-F1值,如下图:

其实,经过数学推导可以发现,在微指标方面有以下等式:

多分类评估指标之准确率(Accuracy)
由前述内容,准确率(Accuracy)等于微F1值(micro-F1),其最本质的定义是指所有被正确分类的样本占总样本的比例。
在准确率基础上,还有一个平均准确率指标,即各类别准确率的均值。
多分类评估指标之分类报告(classification_report)和混淆矩阵(confusion_matrix)
当然,严格地说classification_report并不算是一个评估指标,只是sklearn在内置函数库中提供了这样一个接口,以供查看上述指标的详细状况:
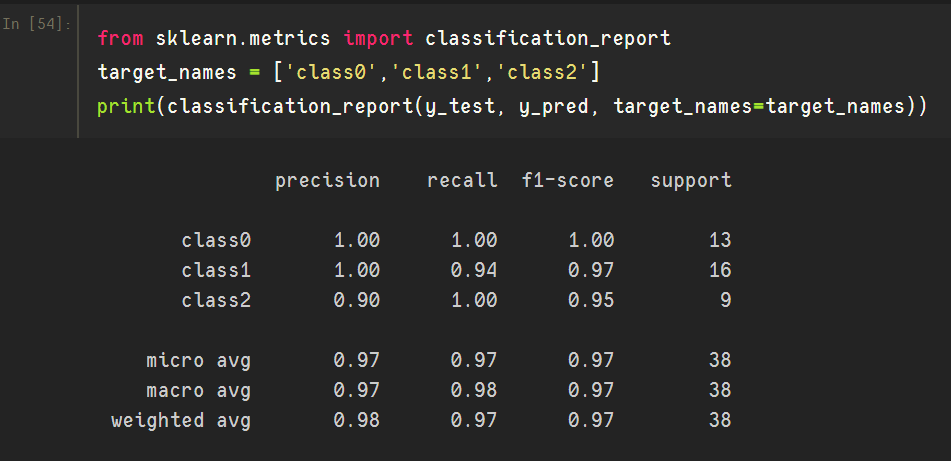
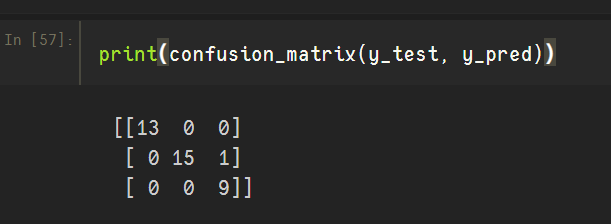
上图为鸢尾花三分类的分类报告情况;
下图为该实例的confusion_matrix情况: