Transformer架构是2017年由google研究团队提出的一项全新的自然语言处理模型架构,首次应用于机器翻译任务中,该模型出自论文《Attention is all you need》。
有别于传统的CNN、RNN架构,Transformer摒弃以往的序列建模思想,全面采用自注意力机制。
Transformer的提出开启了自然语言处理研究的一个新阶段,随后的预训练模型(Bert、GPT等)多以Transformer作为基础架构,辅以大量预料和预训练任务(语言模型、NSP等)。
本系列文章记录了笔者对于Transformer的理解和总结。
整体架构
Transformer整体由两部分构成,分别为Encoder与Decoder,如下图所示:

上图左边为Encoder-bolck,上图右边为Decoder-block;具体应用时是多个Encoder-bolck叠加构成Encoder(注意旁边的Nx),多个Decoder-bolck叠加构成Decoder(注意旁边的Nx),如下图以机器翻译任务为例所示:
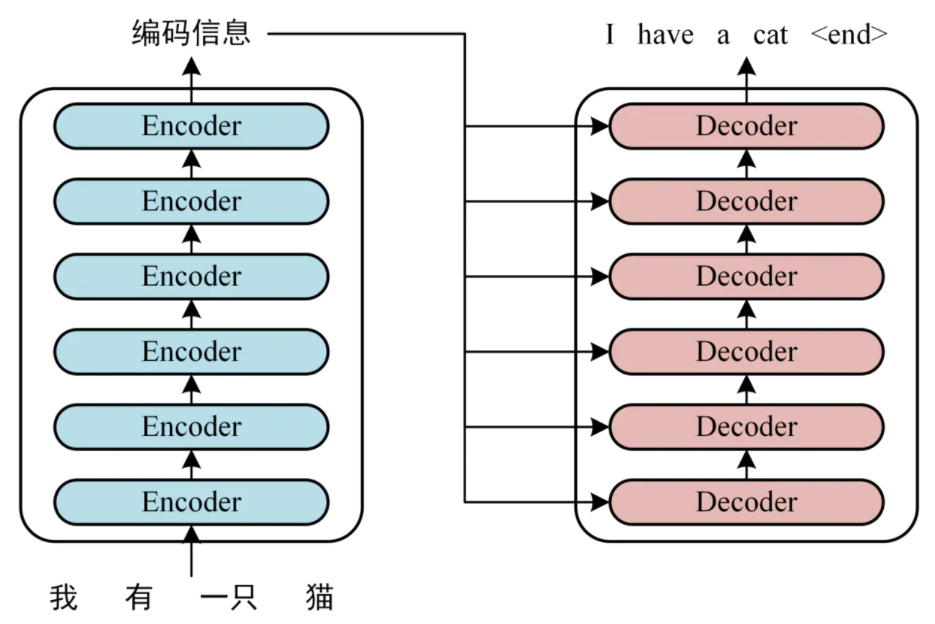
上图中,Encoder部分由6个Encoder-bolck组成,Decoder部分由6个Decoder-bolck组成。
Encoder输入
Encoder部分的输入为一句自然语言,在送入第一个Encoder-bolck之前,需要对自然语言进行数字化处理:
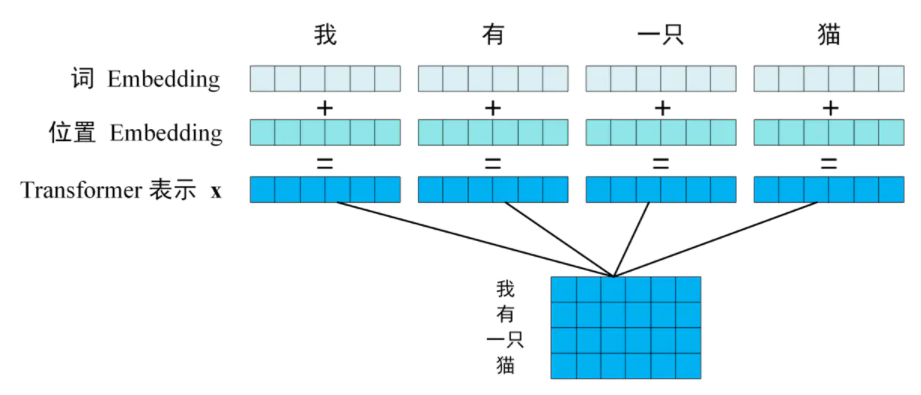
上图中,对于分词后的各个Token(中文情况下Token可理解为分词后的每一个词语,英文情况下Token可理解为以空格隔开的单词),分别将每个Token的词向量(word embedding)与位置向量(position embedding)作按位相加(此处要求每个Token的词向量与位置向量长度一致),得到语句中的每一个Token的表示向量,并将其逐行排列组织成能够代表一句话的输入矩阵 X(蓝色所示)。
每个Token的词向量(word embedding)可有word2vec、elmo等模型得到,也可以自行初始化并在训练过程中调整;
每个Token的位置向量(position embedding)由下式得到:
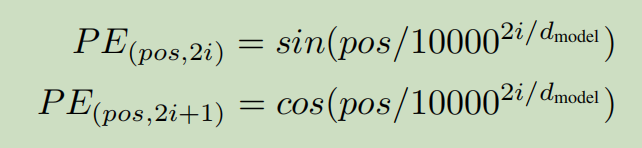
上式中,pos表示Token在一句话中的位置,2i表示Token的位置向量中第2i个位置(分奇偶两种情况计算,即正弦与余弦),d_model表示词向量维度(文中为512)
例如:对于输入“我 有 一只 猫”,则“有”对应的pos为1(从0开始计数),且“有”的位置编码中,奇数位置的值按余弦函数计算,如第7个位置(2i+1=7,此时i=3)代入余弦公式计算,偶数位置的值按正弦函数计算,如第8个位置(2i=8,此时i=4)代入正弦公式计算(最后一个位置应该是2i=512,此时i=256)。
当然,这种位置编码方式仅仅是一种权宜之计,后期Bert模型改进了输入语句的位置编码办法。
下期预告:Encoder-block理解
参考资源
链接:https://www.jianshu.com/p/9b87b945151e
《Attention Is All You Need》