scrapy——8 scrapyd使用
- 什么是scrapyd
- 怎么安装scrapyd
- 如何使用scrapyd--运行scrapyd
- 如何使用scrapyd--配置scrapy.cfg
- 如何使用scrapyd--添加到爬虫工程
- 如何使用scrapyd--运行爬虫任务
- 如何使用scrapyd--停止爬虫任务
- 如何使用scrapyd--删除爬虫项目
- 如何使用scrapyd--查看存在的爬虫工程
什么是scrapyd?
scrapyd是运行scrapy爬虫的服务程序,它支持以http命令方式发布、删除、启动、停止爬虫程序。而且scrapyd可以同时管理多个爬虫,每个爬虫还可以有多个版本。
特点:
- 可以避免爬虫源码被看见。
- 有版本控制。
- 可以远程启动、停止、删除
scrapyd官方文档:https://scrapyd.readthedocs.io/en/stable/overview.html
怎么安装scrapyd
-
安装scrapyd
主要有两种方法:
pip install scrapyd (安装的版本可能不是最新的)
从 https://github.com/scrapy/scrapyd 中下载源码,
运行python setup.py install 命令进行安装
2. 安装scrapyd-deploy
主要有两种安装方式:
pip install scrapyd-client(安装的版本可能不是最新版本)
从 http://github.com/scrapy/scrapyd-client 中下源码,
运行python setup.py install 命令进行安装。
如何使用scrapyd?
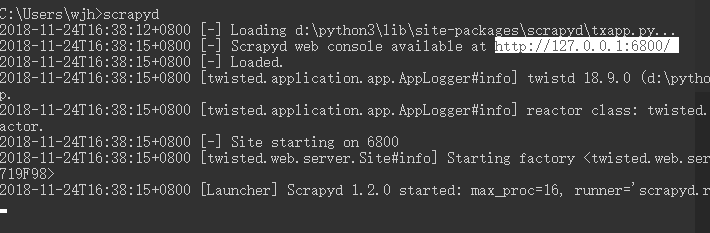
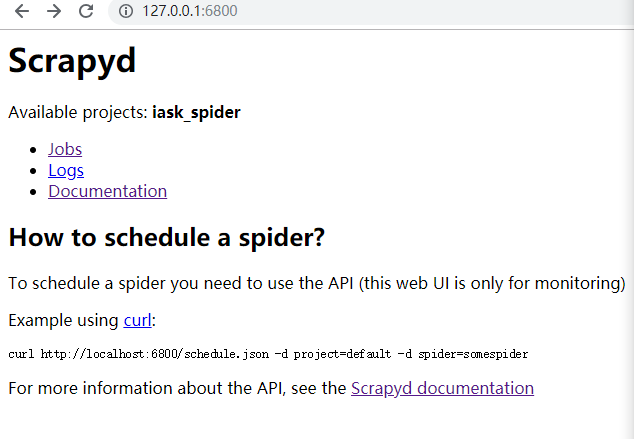
直接在终端输入scrapyd,访问http链接
这时进入到我们的scrapy项目中,找到新建scrapy项目都会生成的scrapy.cfg文件
打开后是这样的内容
# Automatically created by: scrapy startproject # # For more information about the [deploy] section see: # https://scrapyd.readthedocs.io/en/latest/deploy.html [settings] default = tencent.settings [deploy] #url = http://localhost:6800/ project = tencent
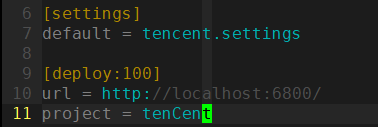
- 首先去掉url前面的注释符号,url是scrapyd服务器的网址
- 然后project=tenCent为项目名称,可以随意起名
- 修改[deploy]为[depoly:100],表示把爬虫发布到名为100的爬虫服务器上,一般在需要同时发布爬虫到多个目标服务器时使用
命令如下:
Scrapyd-deploy <target> -p <project> --version <version>
参数解释:
- target:deploy后面的名称。
- project:自行定义名称,跟爬虫的工程名字无关。
- version:自行定义版本号,不写的话默认为当前时间戳
现在我们来上传一个新的项目到scrapd中
来到项目的能运行scrapy的路径下,输入:
scrapyd-deploy 100 -p tenCent --version v1

这是刷新6800端口网页,会发现已经有项目被添加进来了
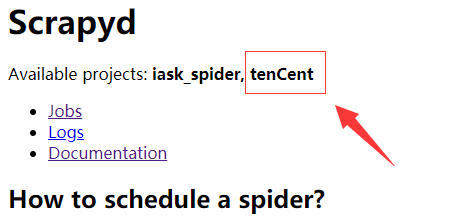
此时的job还是没有数据的
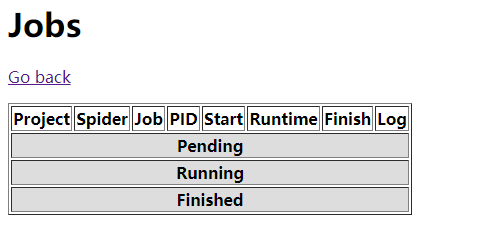
运行爬虫项目的命令如下:
curl http://localhost:6800/schedule.json -d project=project_name -d spider=spider_name
- project:scrapy.cfg中设置的project
- spider_name:运行scrapy的项目名称===》scrapy list

运行代码以后:


job_id:如图所致
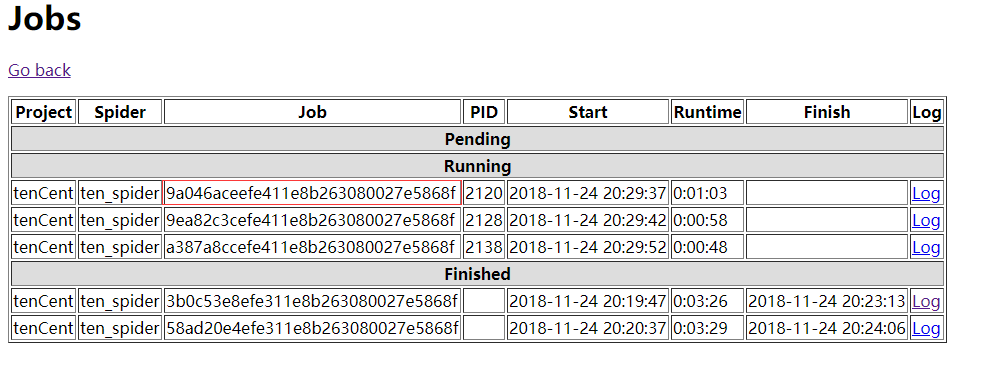

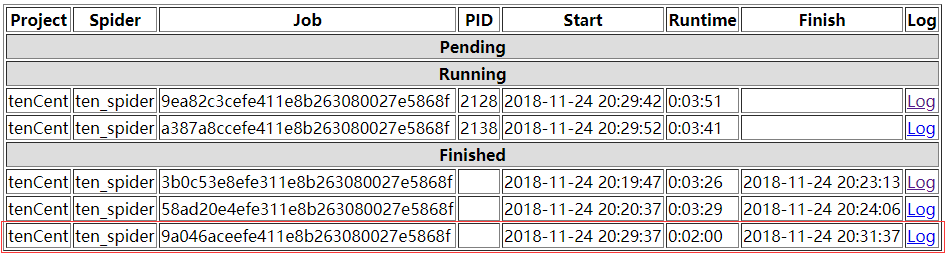
可以看出,爬虫在2:00时就停止了
log可以查看运行结果
curl http://localhost:6800/delproject.json -d project=project_name


curl http://localhost:6800/listprojects.json

还有其他更多的命令,请参考官网:https://scrapyd.readthedocs.io/en/latest/api.html