1. 应用K-means算法进行图片压缩
读取一张图片
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
观察压缩图片的文件大小,占内存大小
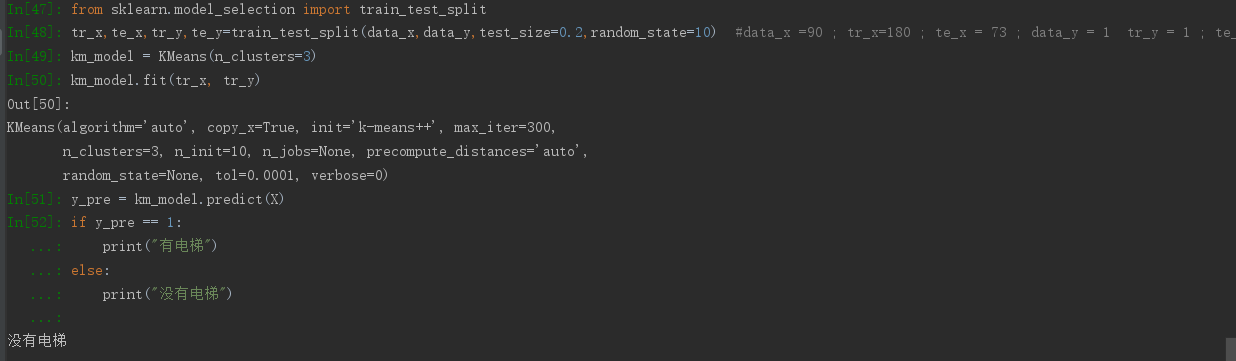
from sklearn.datasets import load_sample_image from sklearn.cluster import KMeans import matplotlib.pyplot as plt import sys import numpy as np china = load_sample_image("china.jpg") #读取加载图片 plt.imshow(china) #看图片 plt.show() #显示图片 china.shape #图片结构 sys.getsizeof(china) #查看图片的尺寸 import matplotlib.image as img img.imsave("D://china.jpg",china) #保存图片到D://china.jpg #图片压缩 #颜色聚类 # image = china[::3,::3] #让图片尺寸变小 X = china.reshape(-1,3) #china数据是三维数组,将数据拉平 # china.shape得到的是(横向上有多少的像素点,纵向上有多少的像素点,像素点的取值) print(china.shape,X.shape) n_colors = 64 #聚成64类,【255*255*255】 K_model = KMeans(n_colors) labels = K_model.fit_predict(X) #训练数据并预测数据 (一堆数组,30602个元素的类别) colors = K_model.cluster_centers_ #二维【64,3】,64种颜色,3个通道 print("颜色类别的数据结构",labels.shape) print("每个类别的颜色数据结构",colors.shape) # print(labels.shape,colors.shape) #还原图片 new_iamge = colors[labels].reshape(china.shape) #每一个像素具体的颜色,reshape成原来的形状 #原来的图片 plt.imshow(china) plt.show() #压缩的图片 plt.imshow(new_iamge.astype(np.uint8)) #np.uint8 类型转换,小数点转换为8位整形 plt.show() # #在进一步压缩 # plt.imshow(new_iamge.astype(np.uint8)[::3,::3]) # plt.show() sys.getsizeof(new_iamge) #压缩后图片占用空间大小 img.imsave("D://new_image.jpg",new_iamge) #保存图片
截图:


原图:

压缩后:

2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
import pandas as pd import numpy as np from sklearn.cluster import KMeans from sklearn.model_selection import train_test_split data = pd.read_csv('venv/data/201706120039邱杰(处理好).csv') #将列'电梯情况'进行条件的判断,替换为0、1 data.loc[data['电梯情况'] == ' 有' , '电梯情况'] = 1 # int 类型 data.loc[data['电梯情况'] == '暂无' , '电梯情况'] = 0 #提取列为'面积'、'总价'、'室'、'厅'为x data_x = data.iloc[:,[2,3,4,5]] #提取到面积、总价、室、厅 #将x改为二维数组形式 data_x = np.array(data_x) #将列为'电梯情况'为y data_y = data.iloc[:,10] #将y改为一维数据形式 data_y = np.array(data_y) #要预测的数据 X = np.array([[103,300,2,1]]) #对data_x,data_y进行训练 tr_x,te_x,tr_y,te_y=train_test_split(data_x,data_y,test_size=0.2,random_state=10) #data_x =90 ; tr_x=180 ; te_x = 73 ; data_y = 1 tr_y = 1 ; te_y = 1 # 要分成的簇数也是要生成的质心数 km_model = KMeans(n_clusters=3) #创建模型 km_model.fit(tr_x, tr_y) # #查看聚类结果 # km_model.labels_ y_pre = km_model.predict(X) if y_pre == 1: print("有电梯") else: print("没有电梯")
截图:
(我的csv文件)
结果截图: