cblas_sgemm
int m = 40;
int k = 20;
int n = 40;
std::vector<float> a(m*k, 1.0);
std::vector<float> b(k*n, 1.0);
std::vector<float> c(m*n, 0.0);
float alpha = 1.0;
float beta = 0.0;
cblas_sgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans,
m, n, k, alpha,
a.data(), k,
b.data(), n, beta,
c.data(), n);
std::cout << "a.size(): " << a.size() << std::endl;
for (int i = 0; i < a.size(); ++i) {
std::cout << a[i] << " ";
if ((i + 1) % k == 0)
std::cout << std::endl;
}
std::cout << "b.size(): " << b.size() << std::endl;
for (int i = 0; i < b.size(); ++i) {
std::cout << b[i] << " ";
if ((i + 1) % n == 0)
std::cout << std::endl;
}
std::cout << "c.size(): " << c.size() << std::endl;
for (int i = 0; i < c.size(); ++i) {
std::cout << c[i] << " ";
if ((i + 1) % n == 0)
std::cout << std::endl;
}
std::cout << std::endl;
output:
a.size(): 800 ( 40 * 20 )
1 1 ... 1 1
...
1 1 ... 1 1
b.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
c_array.size(): 1600 (40 * 40)
20 20 ... 20 20
...
20 20 ... 20 20
cblas_sgemm_batch

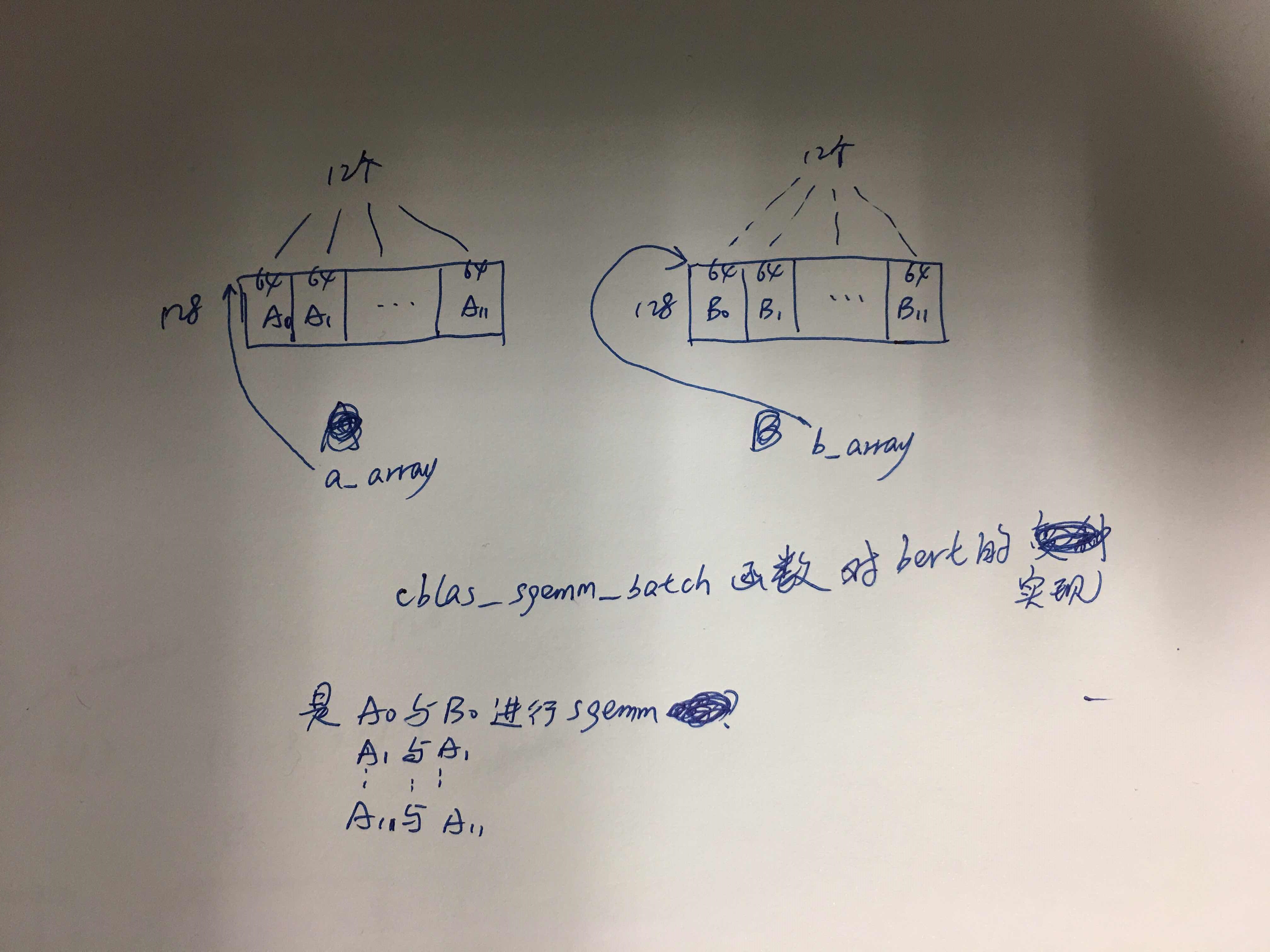
int raw_rows = 20;
int raw_cols = 40;
std::vector<float> a(raw_rows * raw_cols, 1.0);
std::vector<float> b(raw_rows * raw_cols, 1.0);
std::vector<float> c(1600, 0.0);
#define GRP_COUNT 1
MKL_INT m[GRP_COUNT] = {20};
MKL_INT k[GRP_COUNT] = {10};
MKL_INT n[GRP_COUNT] = {20};
MKL_INT lda[GRP_COUNT] = {40};
MKL_INT ldb[GRP_COUNT] = {40};
MKL_INT ldc[GRP_COUNT] = {80};
CBLAS_TRANSPOSE transA[GRP_COUNT] = { CblasNoTrans };
CBLAS_TRANSPOSE transB[GRP_COUNT] = { CblasTrans };
float alpha[GRP_COUNT] = {1.0};
float beta[GRP_COUNT] = {0.0};
const MKL_INT size_per_grp[GRP_COUNT] = {4};
const float *a_array[4], *b_array[4];
float *c_array[4];
for (int i = 0; i < 4; ++i) {
a_array[i] = a.data() + i * 10;
b_array[i] = b.data() + i * 10;
c_array[i] = c.data() + i * 20;
}
cblas_sgemm_batch (CblasRowMajor, transA, transB,
m, n, k, alpha,
a_array, lda,
b_array, ldb, beta,
c_array, ldc,
GRP_COUNT, size_per_grp);
std::cout << "a.size(): " << a.size() << std::endl;
for (int i = 0; i < a.size(); ++i) {
std::cout << a[i] << " ";
if ((i + 1) % 40 == 0)
std::cout << std::endl;
}
std::cout << "b.size(): " << b.size() << std::endl;
for (int i = 0; i < b.size(); ++i) {
std::cout << b[i] << " ";
if ((i + 1) % 40 == 0)
std::cout << std::endl;
}
std::cout << "c_array.size(): " << 20 * 20 * 4 << std::endl;
for (int i = 0; i < 1600; ++i) {
std::cout << c[i] << " ";
if ((i + 1) % 80 == 0)
std::cout << std::endl;
}
std::cout << std::endl;
output:
a.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
b.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
c_array.size(): 1600 (40 * 40)
10 10 ... 10 10
...
10 10 ... 10 10
int raw_rows = 20;
int raw_cols = 40;
std::vector<float> a(raw_rows * raw_cols, 1.0);
std::vector<float> b(raw_rows * raw_cols, 1.0);
std::vector<float> c(400, 0.0);
#define GRP_COUNT 1
MKL_INT m[GRP_COUNT] = {5};
MKL_INT k[GRP_COUNT] = {10};
MKL_INT n[GRP_COUNT] = {5};
MKL_INT lda[GRP_COUNT] = {40};
MKL_INT ldb[GRP_COUNT] = {40};
MKL_INT ldc[GRP_COUNT] = {20};
CBLAS_TRANSPOSE transA[GRP_COUNT] = { CblasNoTrans };
CBLAS_TRANSPOSE transB[GRP_COUNT] = { CblasTrans };
float alpha[GRP_COUNT] = {1.0};
float beta[GRP_COUNT] = {0.0};
const MKL_INT size_per_grp[GRP_COUNT] = {16};
const float *a_array[16], *b_array[16];
float *c_array[16];
for (int i = 0; i < 4; ++i) {
for (int j = 0; j < 4; ++j) {
a_array[i*4+j] = a.data() + i * 5 * 40 + j * 10;
b_array[i*4+j] = b.data() + i * 5 * 40 + j * 10;
c_array[i*4+j] = c.data() + i * 5 * 20 + j * 5;
}
}
cblas_sgemm_batch (CblasRowMajor, transA, transB,
m, n, k, alpha,
a_array, lda,
b_array, ldb, beta,
c_array, ldc,
GRP_COUNT, size_per_grp);
std::cout << "a.size(): " << a.size() << std::endl;
for (int i = 0; i < a.size(); ++i) {
std::cout << a[i] << " ";
if ((i + 1) % 40 == 0)
std::cout << std::endl;
}
std::cout << "b.size(): " << b.size() << std::endl;
for (int i = 0; i < b.size(); ++i) {
std::cout << b[i] << " ";
if ((i + 1) % 40 == 0)
std::cout << std::endl;
}
std::cout << "c_array.size(): " << 5 *5 * 16 << std::endl;
for (int i = 0; i < 400; ++i) {
std::cout << c[i] << " ";
if ((i + 1) % 20 == 0)
std::cout << std::endl;
}
std::cout << std::endl;
output:
a.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
b.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
c_array.size(): 400 (20 * 20)
10 10 ... 10 10
...
10 10 ... 10 10