欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~
作者:闫燕飞
1.背景
Ckafka是基础架构部开发的高性能、高可用消息中间件,其主要用于消息传输、网站活动追踪、运营监控、日志聚合、流式处理、事件追踪、提交日志等等需要高性能的场景,目前已经上线腾讯云。Ckafka完全兼容现有的Kafka协议,使现有Kafka用户可以零成本迁入Ckafka。Ckafka基于现有的Kafka进行了扩展开发和优化,为了方便用户理解Ckafka本文也将对Kafka的实现原理进行较为详细的介绍。
2.Kafka原理
2.1 Kafka诞生背景
Kafka是一种高吞吐量的采用发布订阅模式的分布式消息系统,最初由LinkedIn采用Scala语言开发,用作LinkedIn的活动流追踪和运营系统数据处理管道的基础。现已成为Apache开源项目,其主要的设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上的数据也能保证常数时间复杂度的访问性能。注:其实对于写Kafka的确保证了O(1)的常数时间性能。但对于读,是segment分片级别对数O(logn)时间复杂度。
- 高吞吐率。Kafka力争即使在非常廉价的商用机上也能做到单机支持100Kqps的消息传输能力。
- 支持Kafka Server间的消息分区(partition),及分布式消费,同时保证每个partition内的消息顺序传输。注:其实Kafka本身实现逻辑并不做该保证,主要的算法是集中在消费者端,由消费者的分配算法保证,详情下面会介绍。
- 同时支持离线数据处理和实时数据处理。
- 支持在线水平扩展,Kafka的水平扩展主要来源于其分区(partition)的设计理念。
2.2 主流消息队列对比
| RabbitMQ | RocketMQ | CMQ | Kafka | |
|---|---|---|---|---|
| 模式 | 发布订阅 | 发布订阅 | 传统queue/发布订阅 | 发布订阅 |
| 同步算法 | GM | 同步双写 | Raft | ISR(Replica) |
| 分布式扩展 | 否 | 支持 | 支持 | 支持 |
| 堆积能力 | 磁盘容量 | 磁盘容量 | 磁盘(水平扩展) | 磁盘(水平扩展) |
| 性能 | 中 | 高 | 高 | 很高 |
| 可靠性 | 一般 | 一般 | 极高 | 一般 |
| 持久化 | 内存/硬盘 | 磁盘 | 磁盘 | 磁盘 |
2.3 架构
2.3.1 整体架构图
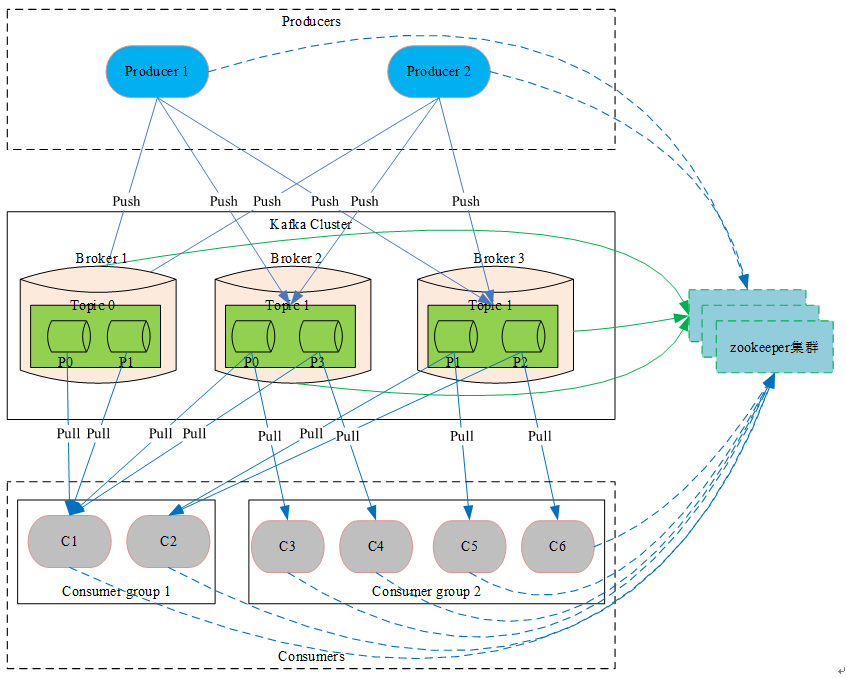
2.3.2 相关概念介绍
2.3.2.1 zookeeper集群
Kafka系统强依赖的组件。其存储了Kafka核心原数据 (如topic信息配置、broker信息、 消费分组等等,相当于DB充当了Kafka的配置管理中心) 。 Kafka的leader选举(如coordinator选举、controller选举、partition leader选举等等),同样也会借助于zookeeper。
2.3.2.2 coordinator
coordinator协调器模块,主要用来管理消费分组和消费offset,充当中介管理消费者并从消费分组中选举出一个消费者作为leader,然后将消费分组中所有消费者信息发往该leader由该leader负责分配partition。该模块为Kafka 0.9版本新加入的新的模块,Kafka集群中可以存在多个协调器分别管不同的消费分组,提高整个系统的扩展能力,主要用于解决之前消费者(high level消费者api)都需要通过与zookeeper连接进行相关的选举,导致zookeeper压力大、惊群及脑裂问题。
2.3.2.3 controller
controller模块,主要负责partition leader选举、监听创建及删除Topic事件然后下发到指定broker进行处理等功能,整个Kafka集群中只能有一个controller,Kafka利用zookeeper的临时节点特性来进行controller选举。
2.3.2.4 Broker
消息缓存代理,Kafka集群包含一个或多个服务器,这些服务器被称为Broker,负责消息的存储于转发,作为代理对外提供生产和消费服务。
2.3.2.5 Topic
消息主题(类别),逻辑上的概念,特指Kafka处理的消息源的不同分类,用户可以根据自己的业务形态将不同业务类别的消息分别存储到不同Topic。用户生产和消费时只需指定所关注的topic即可,不用关注该topic的数据存放的具体位置。
2.3.2.6 Partition
Topic物理上的分组,在创建Topic时可以指定分区的数量,每个partition是一个有序的队列,按生产顺序存储着每条消息,而且每条消息都会分配一个64bit的自增长的有序offset(相当于消息id)。Partition是整个Kafka可以平行扩展的关键因素。
2.3.2.7 Replication
副本,topic级别的配置,可以理解为topic消息的副本数。Kafka 0.8版本加入的概念,主要目的就是提高系统的可用性。防止broker意外崩溃导致部分partition不可以服务。
2.3.2.8 ISR
In-Sync Replicas ,Kafka用来维护跟上leader数据的broker列表,当leader崩溃后,优先从该列中选举leader
2.3.2.9 Producer
Producer 生产者,采用Push方式进行消息发布生产。Producer可以通过与zookeeper连接获取broker信息, topic信息等等元数据,然后再与broker交互进行消息发布。在此过程中zookeeper相当于一个配置管理中心(类似于Name Server提供相关的路由信息)。采用直接向Producer暴露zookeeper信息存在以下两个非常大的弊端:
- zookeeper属于整个Kafka系统的核心结构,其性能直接影响了整个集群的规模,故当暴露给生产者过多的生产者会导致zookeeper性能下降最终影响整个Kafka集群的规模和稳定性。
- zookeeper存储着Kafka的核心数据,若公开暴露出去则容易受到恶意用户的攻击,最终导致Kafka集群不可服务,故非常不建议Kafka服务提供方向使用者暴露zookeeper信息。
正因为存在上面的问题,Kafka也提供了Metadata RPC,通过该RPC生产者可以获取到broker信息、topic信息以及topic下partition的leader信息,然后生产者在访问指定的broker进行消息生产,从而对生产者隐藏了zookeeper信息使的整个系统更加安全、稳定、高效。
2.3.2.10 Consumer
消费者,采用Pull方式,从Broker端拉取消息并进行处理。当采用订阅方式(一般通过使用consumer high level api或new consumer来进行订阅)订阅感兴趣的Topic时,Consumer必须属于一个消费分组,而且Kafka保证同一个Topic的一条消息只能被同一个消费分组中的一个Consumer消费,但多个消费分组可以同时消费这一条消息。
其实Kafka本身不对这个(同一个topic的一条消息只能被同一个消费分组中一个消费者消费)做任何保证,尤其是在0.9版本之前Kafka Broker根本都没有消费分组的概念也没有消费offset概念,Kafka只是提供FetchMessage RPC供使用者去拉取消息,至于是谁来取,取多少次其根本不关心,该保证是由消费者api内部的算法自己完成。
在0.9版本之前消费分组只是消费者端的概念,同一个消费分组的所有消费者都通过与zookeeper连接注册,然后自主选择一个leader(一个消费分组一个leader),再通过该leader进行partition分配(分配算法默认是range,也可以配置成round robin甚至自己实现一个算法非常的灵活)。所有消费者都按照约定访问分配给自己的partition,并且可以选择将消费offset保持在zookeeper或自己存。该方式会暴露zookeeper从而导致存在和暴露zookeeper给Producer一样的问题,并且因为任何一个消费者退出都会触发zookeeper事件,然后重新进行rebalance,从而导致zookeeper压力非常大、而且还存在惊群及无法解决的脑裂问题,针对这个问题0.9版本(含)之后,Kafka Broker添加了coordinator协调器模块。
但coordinator模块也未进行任何分配算法相关的处理,只是替换了zookeeper的一些功能,充当了中介将之前消费者都要通过zookeeper自己选择leader, 变成统一和coordinator通信,然后由coordinator选择leader,然后将同一个消费分组中的消费者都发送给leader(消费者api),由leader负责分配。另一个方面就是coordinator当前多了管理offset的功能,消费者可以选择将offset提交给coordinator,然后由coordinator进行保存,当前默认情况下coordinator会将offset信息保存在一个特殊的topic(默认名称_consumer_offsets)中,从而减少zookeeper的压力。消费分组中partition的分配具体可以看下一个小结中消费分组的相关说明。
2.3.2.11 Consumer Group
消费分组,消费者标签,用于将消费者分类。可以简单的理解为队列,当一个消费分组订阅了一个topic则相当于为这个topic创建了一个队列,当多个消费分组订阅同一个topic则相当于创建多个队列,也变相的达到了广播的目的,而且该广播只用存储一份数据。 为了方便理解,通过下面的图片对消费分组相关概念进行讲解。
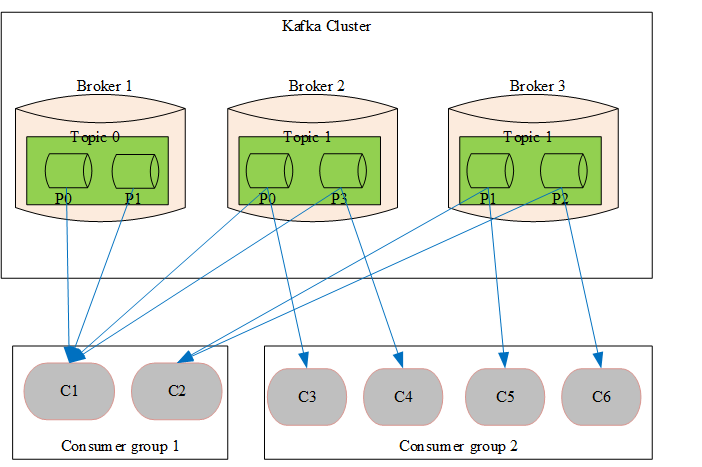
- 一个消费分组可以订阅多个topic,同理一个topic可以被多个消费分组订阅
- topic中的partition只会分配给同一个消费分组中的一个消费者,基于这种分配策略,若在生产消息时采用按照消息key进行hash将同一个用户的消息分配到同一partition则可以保证消息的先进先出。Kafka正是基于这种分配策略实现了消息的先进先出。
- 同一个消费分组中,不同的消费者订阅的topic可能不一样,但Kafka的partition分配策略保证在同一个消费分组的topic只会分配给订阅了该topic的消费者,即消费分组中会按照topic再划分一个维度。以上图为例Consumer group1中C1和C2同时订阅了Topic 1所以将Topic1下面的P0 ~ P3四个partition均分给C1和C2。同样Consumer group1中只有C1订阅了Topic0故Topic0中的两个partition只分配给了C1未分配给C2。
2.3.2.12 Message
消息,是通信和存储的最小单位。其包含一个变长头部,一个变长key,和一个变长value。其中key和value是用户自己指定,对用户来说是不透明的。Message的详细格式下面会有介绍,这里先不展开说明。
下一篇:《高性能消息队列 CKafka 核心原理介绍(下)》
相关阅读
此文已由作者授权腾讯云技术社区发布,转载请注明文章出处
原文链接:
此文已由作者授权腾讯云技术社区发布,转载请注明文章出处
原文链接:https://www.qcloud.com/community/article/549934