欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~
作者:李春晓
导语:
“从入门到第一个模型”差点就成了“从入门到放弃”。本文是机器学习在运维场景下的一次尝试,用一个模型实现了业务规律挖掘和异常检测。这只是一次尝试,能否上线运转还有待考究。试了几个业务的数据,看似有效,心里却仍然忐忑,担心哪里出错或者有未考虑到的坑,将模型介绍如下,请大侠们多多指教,帮忙指出可能存在的问题,一起交流哈。
背景:
业务运维需要对业务基础体验指标负责,过去的分析都是基于大数据,统计各个维度及其组合下关键指标的表现。比如我们可以统计到不同网络制式下打开一个app的速度(耗时),也可以获取不同命令字的成功率。针对移动APP类业务,基于经验,我们在分析一个指标时都会考虑这些因素:App版本、指标相关的特有维度(比如图片下载要考虑size、图片类型; 视频点播类要考虑视频类型、播放器类型等)、用户信息(网络制式、省份、运营商、城市)等。这些维度综合作用影响关键指标,那么哪些维度组合一定好,哪些一定不好?耗时类指标的表现往往呈现准正态分布趋势,其长尾永远存在并且无法消除,这种情况要不要关注? 针对命令字成功率,有些命令字成功率低是常态,要不要告警?过去我们会通过在监控中设置特例来避免告警。有没有一种方法,能自动识别常态与非常态?在机器学习如火如荼的现在,也许可以试一试。
目标:
-
挖掘业务潜在规律(针对耗时这类连续值指标,找出引起长尾的因素)
-
监控业务指标时,找出常态并忽略常态,仅针对突发异常产生告警并给出异常的根因。
之后就是艰苦的屡败屡战,从入门到差点放弃,最终搞出第一个模型的奋战史了。最大的困难是没写过代码,不会python,机器学习理论和代码都要同步学习;然后就是在基础薄弱的情况下一开始还太贪心,想要找一个通用的模型,对不同业务、不同指标都可以通用,还可以同时解决两个目标问题,缺少一个循序渐进入门的过程,难免处处碰壁,遇到问题解决问题,重新学习。好在最终结果还是出来了,不过还是要接受教训:有了大目标后先定个小目标,理清思路后由点及面,事情会顺利很多。
接下来直接介绍模型,过程中走的弯路就忽略掉(因为太多太弱了,有些理论是在遇到问题后再研究才搞明白)。
基本思路:
1.通过学习自动获取业务规律,对业务表现进行预测(ET算法),预测命中的就是业务规律,没命中的有可能是异常(请注意,是有可能,而非绝对);
2.将1的结果分别输入决策树(DT)进行可视化展示;用预测命中的部分生成业务潜在规律视图;用未命中的来检测异常,并展示根因。
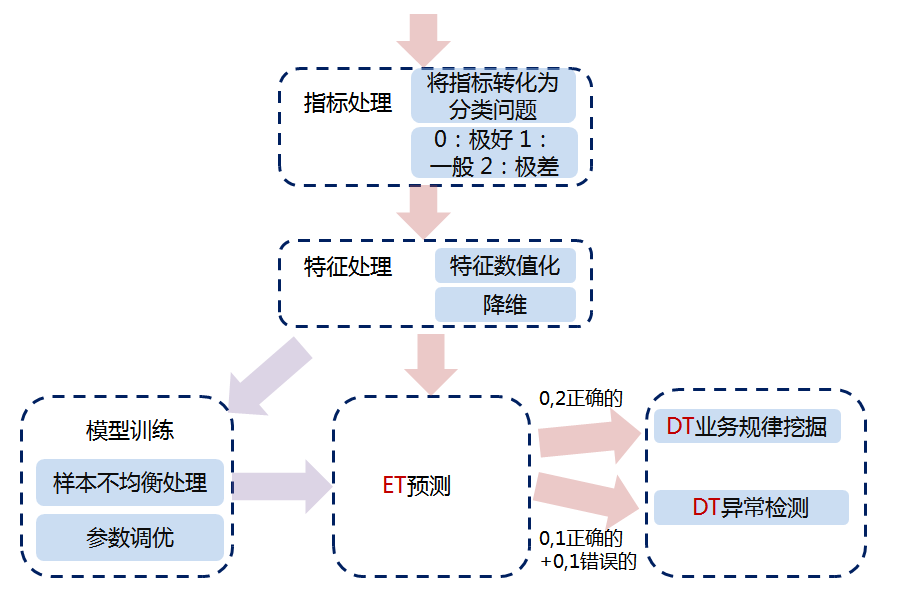
步骤简介(以耗时这个指标为例):
1. 准备两份不重合的数据,一份用于训练,一份用于预测
例:视频播放类业务的维度(如版本,机型,视频来源,视频编码类型等各种已有特征),及耗时数据
2. 将目标问题转化为分类问题,有可能是常见的二分类,也有可能是多分类,视情况而定
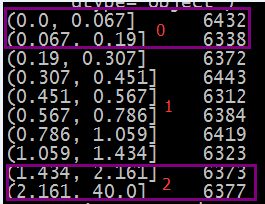
将耗时这种连续性指标转为离散值,目标是产生三个分类:“极好的/0”,“一般的/1”,“极差的/2”,将耗时按10分位数拆分,取第1份(或者前2份)作为“极好的”样本,中间几份为“一般的”的样本,最后1(或者2)份为“极差的“样本 。 这里的“极差的”其实就是正态分布的长尾部分。如下图,第一列是耗时区间(未加人工定义阈值,自动获取),第二列是样本量。
3. 特征处理
3.1 特征数值化
这里表现为两类问题,但处理方式都一样:
(1)文本转数值
(2)无序数值需要削掉数值的大小关系,比如Appid这类,本身是无序的,不应该让算法认为65538>65537
方法:one-hot编码, 如性别这个特征有三种取值,boy,girl和unknown,转换为三个特征sex==boy,sex==girl,sex==unknown, 条件满足将其置为1,否则置为0.
实现方式3种:自己实现;sklearn调包;pandas的get_dummies方法。
One-hot编码后特征数量会剧烈膨胀,有个特征是手机机型,处理后会增加几千维,同时也要根据情况考虑是否需要对特征做过于细化的处理。
3.2 特征降维
是否需要降维,视情况而定,我这里做了降维,因为特征太多了,如果不降维,最终的树会非常庞大,无法突出关键因素。
所谓降维,也就是需要提取出特征中对结果起到关键影响因素的特征,去掉不重要的信息和多余信息,理论不详述了,参考:http://sklearn.lzjqsdd.com/modules/feature_selection.html
本文用了ET的feature_importance这个特性做降维,将5000+维的数据降至300左右
4. 用ET算法(随机森林的变种,ExtraTreesClassifier)训练一个分类模型(三分类)
4.1 评价模型的指标选取
对于分类算法,我们首先想到的准确性 precision这个指标,但它对于样本不均衡的场景下是失效的。举个例子,我们有个二分类(成功和失败)场景,成功的占比为98%。这种样本直接输入训练模型,必定过拟合,模型会直接忽略失败的那类,将所有都预测为成功。此时成功率可达98%,但模型其实是无效的。那么应该用什么?
对于二分类,可用roc_auc_score,对于多分类,可用confusion_matrix和classification report
4.2 样本不均衡问题处理
本文用的例子,显然0和2的数量非常少,1的数量是大头。为了不对1这种类型产生过拟合,可对0和2这两类做过抽样处理。
常见的有两类算法:
(1)直接复制少数类样本
(2)SMOTE过抽样算法(细节略)
这里两种算法都用过,最终选了SMOTE,不过本文研究的数据上没有看出明显差别。
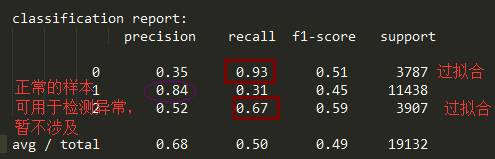
少数类的过抽样解决了大类的过拟合问题,同时也带来了小类的过拟合,不过这里的模型正好需要让小类过拟合,我们就是要把表现“极好”和“极坏”的部分找出来,表现平平的在异常检测时加入关注。过拟合这个问题,不用过于恐惧,反而可以利用。举个例子,“患病”和“不患病”这种分类场景,宁可将“患病”的检出率高一些。如下图这个分类报告,对于小类样本(0和2),我们需要利用recall高的特性,即把它找出来就好;而对于大类样本,我们需要precision高的特性,用于做异常检测。
4.3 模型参数选取
Sklearn有现成的GridSearchCV方法可用,可以看看不同参数组合下模型的效果。对于树类算法,常用的参数就是深度,特征个数;森林类算法加一个树个数。
Max_depth这个参数需要尤其注意,深度大了,容易过拟合,一般经验值在15以内。
4.4 模型训练好后,用测试数据预测,从中提取各个类别预测正确的和不正确的。
例:
预测正确的部分:获取预测为0,2,实际也为0,2的样本标示;
预测错误的部分:获取预测为0和1,实际为2的样本标示(根据情况调节)
5. 输入决策树进行可视化展示,分别做业务规律挖掘和异常检测
这里DT算法仅用于展示,将不同类别的数据区分开,必要时仍然要设置参数,如min_samples_leaf, min_impurity_decrease,以突出关键信息。
还可以通过DecisionTreeClassifier的内置tree_对象将想要找的路径打出来
以下分别给出例子:
5.1 业务规律挖掘
视频点播场景,取0和2这两类预测正确的部分,输入DT,如下图,自动找出了业务潜在规律,并一一用大数据统计的方式验证通过,结论吻合。这个树的数据相对纯净,因为输入给它的数据可以理解为必然符合某种规律。

5.2. 异常检测
本文模型还在研究阶段,未用线上真实异常数据,而是手工在测试数据某个维度(或者组合)上制造异常来验证效果。
针对成功率,可以视容忍程度做二分类或者三分类。
二分类:取一个阈值,如99%,低于99%为2,异常,否则为0正常。缺点是如果某个维度上的成功率长期在99%以下,如98%,当它突然下跌时会被当做常态忽略掉,不会告警。
三分类:99%以上为0, 96~99% 为1,低于96%为2,这种方式会更灵活。 三种分类也分别对应其重要性。重点关注,普通关注,忽略。
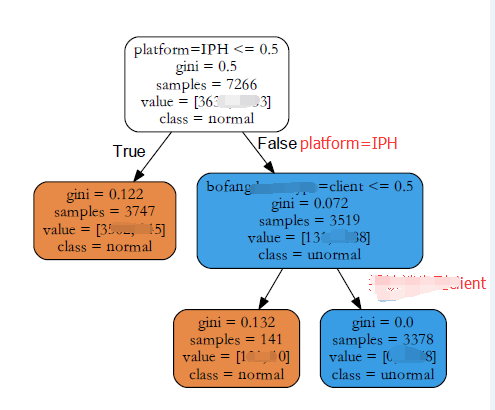
下图是一个二分类的例子(手工将平台为IPH和播放端为client的置为异常):
最后:这里只是一次小尝试,如果要平台化上线运转,还要很多因素要考虑,首要就是模型更新问题(定时更新?避免选取到异常发生时段?),这个将放在下阶段去尝试。
相关阅读
此文已由作者授权腾讯云技术社区发布,转载请注明文章出处
原文链接:https://cloud.tencent.com/community/article/477670