
磁带文件系统时代。数据库最初的理念是采用单一数据源来支持所有用途。数据库这一概念是从管理主文件的磁带文件系统发展而来的。磁带可以存储较大的数据量,而且磁带上存储的记录是大小可变的,但磁带有很多缺陷。缺陷之一是磁带上的文件必须是按顺序访问,这就意味着分析师在寻找一条记录时不得不按照顺序搜索整个文件。磁带文件的另一个缺陷是,随着时间的推移,磁带上的氧化物会逐渐剥离,以氮氧化物消失,磁带上的数据就无法恢复了。事实上,我们常说,在磁带文件的一次操作中,100%的记录都要被访问到,但是只有5%或更少的记录是真正需要的。此外,访问整条磁带的文件可能要花去20-30分钟时间,这取决于文件上是什么数据及当前正在做什么处理。大约在60年代中期,主文件和磁带的使用量迅速膨胀。很快,处处都是主文件。随着主文件数量的增长,出现大量冗余数据。主文件的迅速增长和数据的巨大冗余引出了一些严重问题:
1、需要在更新数据时保持数据的一致性。
2、程序维护的复杂性。
3、开发新程序的复杂性。
4、支持所有主文件需要的硬件数量。
简言之,属于介质本身固有缺陷的主文件的问题成为发展的障碍。如果仍然只用磁带作为存储数据的唯一介质,那么难以想象现在的信息处理领域会是什么样子。
DASD的出现和OLTP的快速发展。20世纪70年代见到的磁盘存储,或者称之为直接存取存储设备(Direct-Attached Storage Device,DASD)。磁盘存储从根本上不同于磁带存储,因为DASD上的数据能够直接存取。由于磁带文件的缺陷,很快便被DASD所代替,他巨大优势在于可以直接对数据进行存取,不再需要仅仅为了访问一个纪录而读取整个文件了。有了磁盘存储器,就可以直接定位到某一个数据单元。
随DASD而来的是称之为数据库管理系统(Database Management System,DBMS)的一种新型系统软件。DBMS的目的是使程序员在DASD上方便地存储和访问数据。另外,DBMS关心的是在DASD上存储、索引数据等任务。随着DASD和DBMS的出现,解决主文件系统问题的一种技术解决方案应运而生。DBMS能够控制磁盘存储器上数据的存储、访问、更新和删除,将程序员从重复和复杂的工作中解脱出来。数据库系统的出现带来了将处理其关联到数据(和磁盘)的能力,以及数据库与计算机的紧密耦合。最初,所采用简单的单处理器架构,单处理器架构包括一个操作系统、DBMS、一个应用程序。早期的计算机可以管理所有这些组件,处理器的性能也得以提升扩展,但是很快单处理器的性能就达到了瓶颈,下一步重大的进展是多处理器的紧耦合。通过将多个处理器耦合在一起,处理能力也自然而然的提高了。
随着更强的处理能力和DBMS控制的出现,在线实时系统(Online Real-time System)应运而生,这类系统所做的处理被称为在线事务处理(Online Transaction Processing,OLTP)。有了OLTP,通过终端和合适的软件,技术人员发现更快速地访问数据是可能的--这就开辟了一种全新的视野。采用高性能联机事务处理,计算机可用来完成以前无法完成的工作。当今,计算机可用于建立预定系统、银行柜员系统、工业控制系统,等等。随着各类系统的爆发式增长,人们创建的数据量和数据类型也有了爆炸性的增长,人们开始希望能够拥有集成化数据,而不再仅仅满足与从某个应用程序获取数据。
编程语言及PC的发展。第四代编程语言(Fourth-Generation Language,4GL)为实现将数据从信息部门的控制之下解放出来的第一步,使得最终用户能够获取数据并且做自己所需的处理。4GL的流行不久,个人电脑也随之诞生,并且最终用户具有了更大的自主性,可以应用如Excel等一类技术对数据进行分析处理。管理信息系统(Management Information System,MIS)是一个以人为主导,利用计算机硬件、软件、网络通信设备以及其他办公设备,进行信息的收集、传输、加工、储存、更新、拓展和维护的系统。MIS其实是DSS(面向决策支持系统,Decision Support System)的前身。
抽取程序。大型联机高性能事务处理问世后不久,就开始出现一种称为“抽取”处理的程序,这种程序并不损害已有系统。抽取程序是所有程序中最简单的程序。它搜索整个文件或数据库,使用某些标准选择合乎限制的数据,并把数据传到其他文件或数据库中。抽取程序很快就流行起来,并渗透到信息处理环境中。至少有两个理由可以用来解释它为什么受到欢迎:
1、因为用抽取程序能将数据从高性能联机事务处理方式中转移出来,所以在需要总体分析数据时就与联机事务处理性能不发生冲突。
2、当用抽取程序将数据从操作型事务处理范围内移出时,数据的控制方式就发生了转变。最终用户一旦开始控制数据,他 (她)就最终“拥有”了这些数据。
由于这些原因(以及其他众多原因),抽取处理很快就无处不在。到了90年代已有了很多抽取程序。
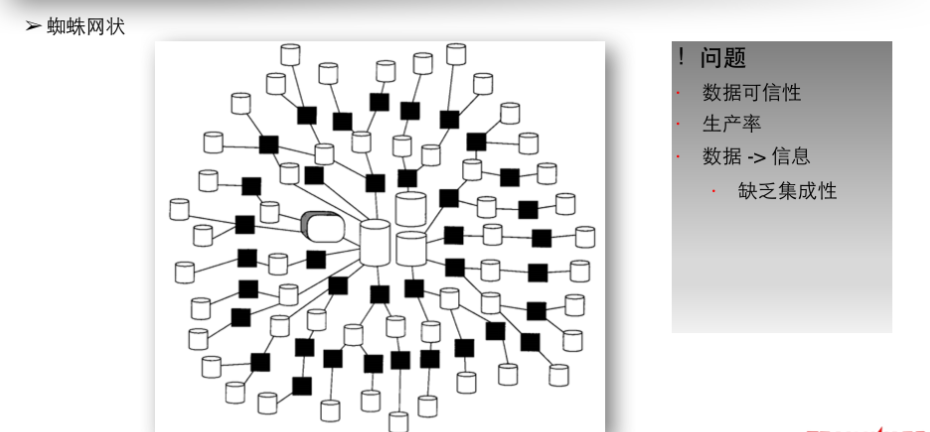
由早期的磁带文件形式到后期的数据库技术的更新迭代,数据量及复杂度也随之增长,数据也在不同的组织及数据集中出现,演化出来的架构也越发复杂,其中之一就是蛛网系统(Spider-web System)(蜘蛛网状)。起初只是抽取,随后是抽取之上的抽取,接着是在此基础上的再次抽取,如此等等(对于一个大公司,每天进行多达45000次的抽取不是没有听说过的)。当一个组织以放任自流的态度处理整个硬、软件体系结构时,就会发生这种情况,这种由失控的抽取过程产生的结构也被称为“自然演化体系结构”。组织越庞大,越成熟,自然演化体系结构问题就变得越严重。
蛛网系统环境中面临很多问题:
1、数据可信性。造成数据缺乏可信性的原因有:没有时间基准;数据算法上存在差异;多层次的数据抽取问题;数据正确性无法保证等。
举例来说:两个部门向管理者呈送报表,一个部门说业绩下降了15%,另一个部门说业绩上升了10%。两个部门的结论不但不吻合,而且相去甚远。另外,两个部门的工作也很难协调。管理者收到这两张报表时,他们不知如何是好,这是在自然演化体系结构中可信性危机的一个实例。造成这类问题的原因是:
a、数据无时基。一个部门在星期日晚上提取分析所需的数据,而另一个进行分析的部门在星期三下午就抽取了数据。没有任何理由相信对某一天抽取的数据样本进行的分析与对另一天抽取的数据样本进行的分析可能会相同,因为公司内的数据总是在变的,任何在不同时刻抽取出来用于分析的数据集之间只是大致相同。
b、数据算法上的差异。比如,一个部门选择所有的老帐号作分析。而另一个部门选择所有大帐号作分析。在有老帐号的顾客和有大帐号的顾客之间存在必要的相关性吗?可能没有。那么分析结果大相径庭就没有什么可大惊小怪的了。
c、抽取的多层次。每次新的抽取结束,因为时间和算法上的差异,抽取结果就可能出现差异。对一个公司而言,从数据进入公司系统到决策者准备好分析所采用的数据,经过八层或九层抽取不是罕见的。
d、外部数据问题。不同分析人员采用不同的外部数据源,对于其他分析人员来说对其所采用的数据一无所知,自然导致了数据缺乏可信性。
e、无起始公共数据源。导致数据缺乏可信性的最后一个因素是通常没有一个公共的起始数据源。
有了以上理由,在每一个企业或机构中,如果允许软件、硬件和数据的体系结构自然地演化为蜘蛛网,那么这种企业或机构中正酝酿着可信性危机就不足为奇了。
2、生产率。生产效率低,如系统繁杂产生过多的垃圾表;不同系统指标无法复用等。
3、数据 -> 信息。数据转化为信息的不可行性,缺乏集成性,也就容易产生维护积压问题,这也是所有问题中最大且最容易理解的一个。经过多年以后,随着系统数量的增长,维护积压问题也随之增长。维护积压其实是为系统需求中的变更而做出的请求。这一问题的解决上,耗费更多的技术和经费,其实是一种浪费,并没有实质的解决。因此,如果不对架构本身进行变更,那么就无法解决蛛网环境所面临的问题。
当发展到这样一种环境之时,数据仓库的概念应运而生。数据仓库的出现为可信的企业数据奠定了基础,它所表现的是整个企业的数据,而不仅仅是某个应用程序的数据。