要求
根据贷款申请人的数据信息预测其是否有违约的可能,以此判断是否通过此项贷款。
数据概况
总数据量超过120w,包含47列变量信息,其中15列为匿名变量。从中抽取80万条作为训练集,20万条作为测试集A,20万条作为测试集B,同时对employmentTitle、purpose、postCode和title等信息进行脱敏
赛题地址:https://tianchi.aliyun.com/competition/entrance/531830/information?lang=zh-cn
评测标准
AUC评估模型
- AUC(area under the curve)是ROC曲线下的面积
学习路线: 混淆矩阵 -> ROC -> AUC - 混淆矩阵
以预测肿瘤是否为恶行为例:
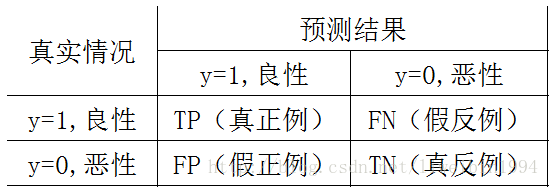
如图:TP表示预测为良性,而实际也是良性的样例数;
FN表示预测为恶性,而实际是良性的样例数;
FP表示预测为良性,而实际是恶性的样例数;
TN表示预测为恶性,而实际也是恶性的样例数;
以上四个数构成混淆矩阵,然后定义两个变脸:
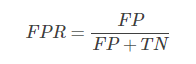
FPR表示,在所有的恶性肿瘤中,被预测成良性的比例。称为伪阳性率。伪阳性率告诉我们,随机拿一个恶性的肿瘤样本,有多大概率会将其预测成良性肿瘤。显然我们会希望FPR越小越好
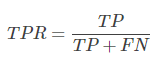
TPR表示,在所有良性肿瘤中,被预测为良性的比例。称为真阳性率。真阳性率告诉我们,随机拿一个良性的肿瘤样本时,有多大的概率会将其预测为良性肿瘤。显然我们会希望TPR越大越好
以FPR/TPR为坐标画图:(显然左上角的最好)
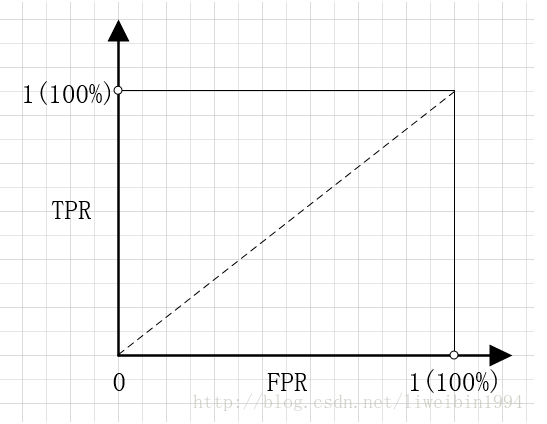
- 将正负样本分离的程度不同,不由不同的ROC曲线
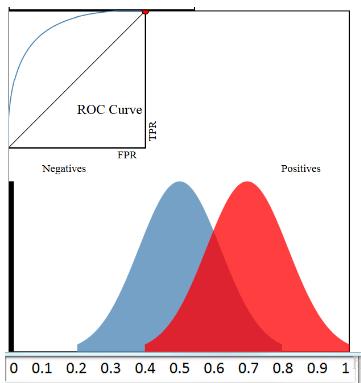
- ROC曲线下面的面积即为AUC,其除了考虑了准确性之外还考虑的阈值的影响,所以很稳定
参考:https://blog.csdn.net/liweibin1994/article/details/79462554