一、安装hadoop前的准备工作
1.修改主机字符显示
vi /etc/sysconfig/i18n
修改为LANG="zh_CN"
2. 修改主机名称
1) vi /etc/sysconfig/network
修改为HOSTNAME=master(/slave1/slave2)------每台主机改成自己的名称
2) vi /etc/hosts
将如下内容添加到三台主机该文件的末尾
192.168.0.6 master
192.168.0.5 slave1
192.168.0.2 slave2
3) 以上方法需要重启主机才能生效,若要即使生效,可以使用<hostname 主机名>命令
3. ssh无密钥登陆
1) 通过以下命令检查是否已安装sshd服务:
rpm –qa | grep openssh
rpm –qa | grep rsync
2) 如果没有安装sshd服务和rsync,可以通过下面命令进行安装:
yum install ssh 安装SSH协议
yum install rsync (rsync是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件)
service sshd restart 启动服务
service iptables stop关闭防火墙
3) Master机器上生成密码对
在Master节点上执行以下命令,在root目录下创建.ssh目录(书上是home目录,代码是一样的,原因是我没有配用户组,直接以root用户来配置,进入系统时,root用户直接进入的是root目录,而其他用户直接进入的是home目录):
cd
mkdir .ssh
ssh-keygen –t rsa
这条命令是生成其无密码密钥对,一直按enter键(询问其保存路径时直接回车采用默认路径)。生成的密钥对:id_rsa和id_rsa.pub,默认存储在"/.ssh"目录下。
把生成的id_rsa.pub复制一份,命名为authorized_keys
cp id_rsa.pub authorized_keys
可以在.ssh目录下查看一下
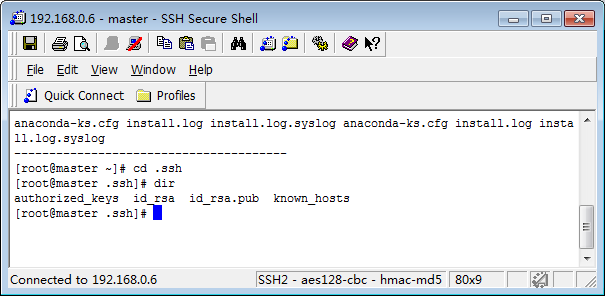
4) 将公钥文件authorized_keys分发到各DataNode节点:
[root@localhost .ssh]# scp authorized_keys root@192.168.0.5:/root/.ssh/
[root@localhost .ssh]# scp authorized_keys root@192.168.0.5:/root/.ssh/
(或者主机ip使用slave1,slave2)
scp -r hbase-1.0.0 root@slave1:/opt/
注意:在此过程中需要注意提问时要输入yes,不能直接回车。否则会出现下面的错误。

5) 验证无密钥是否配置成功
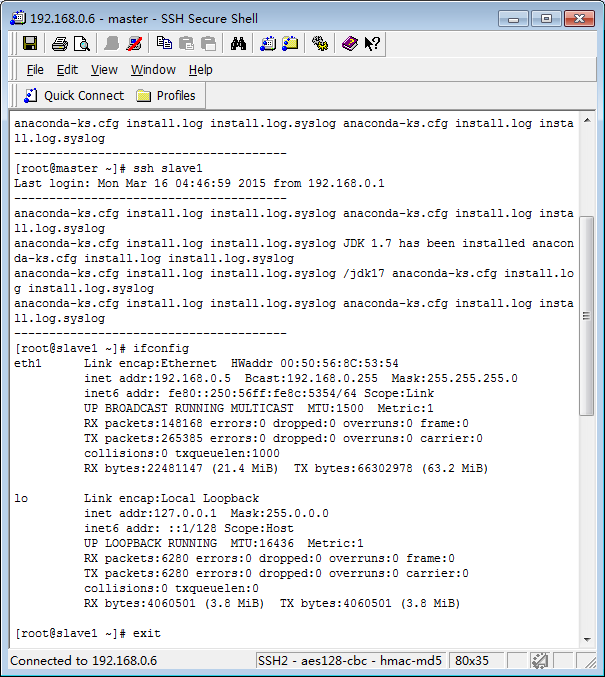
ssh slave1 (首次登陆时需要验证slave1的密码,之后就不用了)
ifconfig (查看ip是否已经变为slave1的ip)
exit (退出连接)
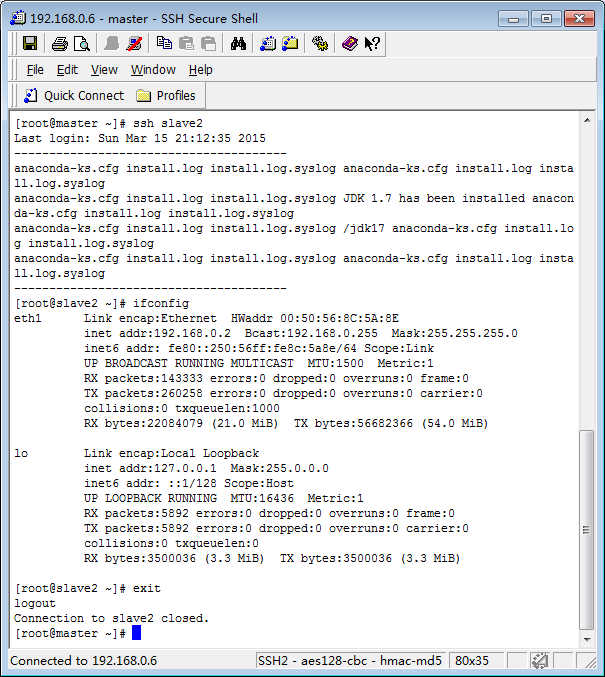
ssh slave2 (验证方式同slave1)
ifconfig
exit
验证结果如下图所示,则无密钥登陆配置成功。接下来就可以安装hadoop了。
二、安装hadoop
1.下载编译安装包
从官网下载hadoop2.5.2安装包,这时候要注意hadoop-2.5.2.tar.gz是编译过的文件,而hadoop-2.5.2-src.tar.gz是没有编译的文件。由于官网的hadoop-2.5.2.tar.gz编译的是32位系统的,所以我们需要下载hadoop-2.5.2-src.tar.gz,再在本机上编译成64位系统的安装包。
可参照教程http://f.dataguru.cn/forum.php?mod=viewthread&tid=454226
(由于村长已经编译好了,我们直接去他的机子下面将安装包scp到自己的机子上即可。村长的主机ip是192.168.0.10)
1) master/slave1/slave2 创建hadoop文件夹存放安装包和解压后的文件:
cd /home
mkdir hadoop
2) 从村长的机子上将安装包scp到自己的机子上
cd /root/download/hadoop-2.5.2-src/hadoop-dist/target
scp hadoop-2.5.2.tar.gz root@192.168.0.6:/home/hadoop/
scp hadoop-2.5.2.tar.gz root@192.168.0.5:/home/hadoop/
scp hadoop-2.5.2.tar.gz root@192.168.0.2:/home/hadoop/
2. 解压安装包
cd /home/hadoop
tar -zvxf hadoop-2.5.2.tar.gz
3. 修改配置
cd /home/hadoop/hadoop-2.5.2/etc/hadoop
1) vi core-site.xml
|
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>4096</value> </property> </configuration> |
2) vi hdfs-site.xml
|
<configuration> <property> <name>dfs.nameservices</name> <value>hadoop-cluster1</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:50090</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///home/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///home/hadoop/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> --------------------------slave个数 </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration> |
3) vi mapred-site.xml
|
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobtracker.http.address</name> <value>master:50030</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration> |
4) vi yarn-site.xml
|
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> </configuration> |
5) vi slaves
删掉localhost
输入
master (这样master本身也作为一个dataNode)
slave1
slave2
6) vi hadoop-env.sh
修改export JAVA_HOME=/jdk17
7) vi yarn-env.sh
去掉#
export JAVA_HOME=/jdk17
8) 将主机配置scp到两台slave上
cd /home/hadoop/hadoop-2.5.2/etc
scp -r hadoop root@slave1:/home/hadoop/hadoop-2.5.2/etc
scp -r hadoop root@slave2:/home/hadoop/hadoop-2.5.2/etc
4. 主机上格式化文件系统
cd /home/hadoop/hadoop-2.5.2
bin/hdfs namenode -format
(格式化过程中会有一次需要输入yes)
5.启动
sbin/start-dfs.sh
sbin/start-yarn.sh
(或者sbin/start-all.sh)
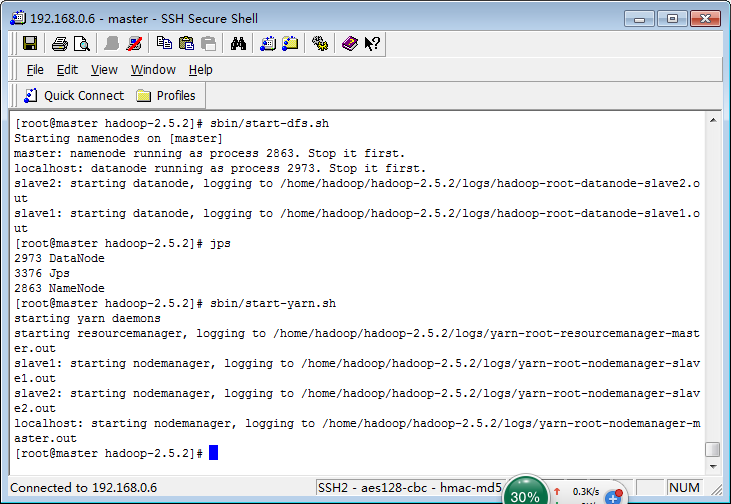
查看启动的进程jps
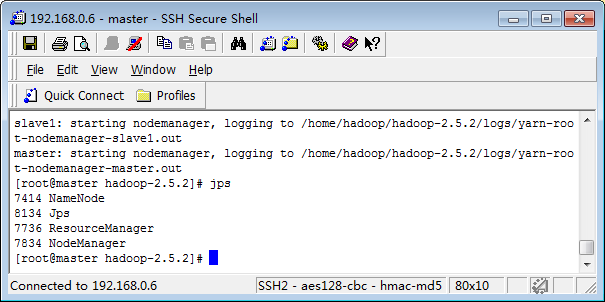
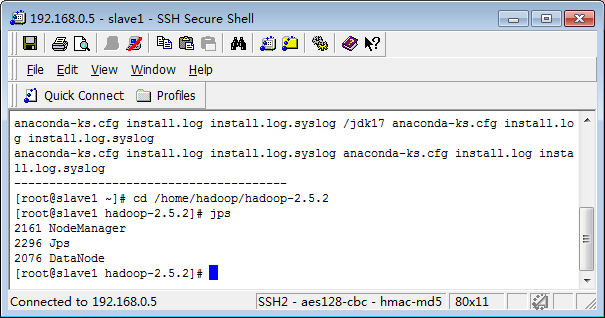
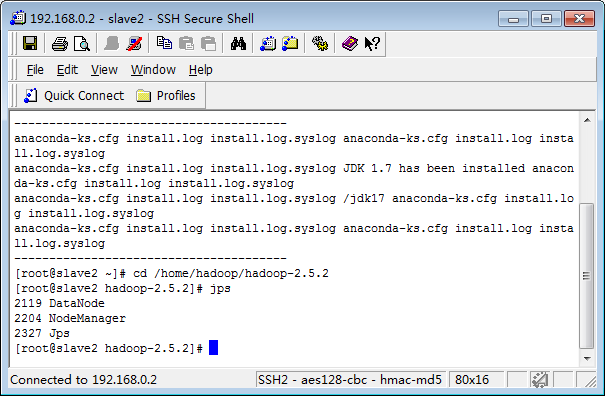
PS:停止
cd /home/hadoop/hadoop-2.5.2
sbin/stop-dfs.sh
sbin/stop-yarn.sh
6. 通过浏览器访问
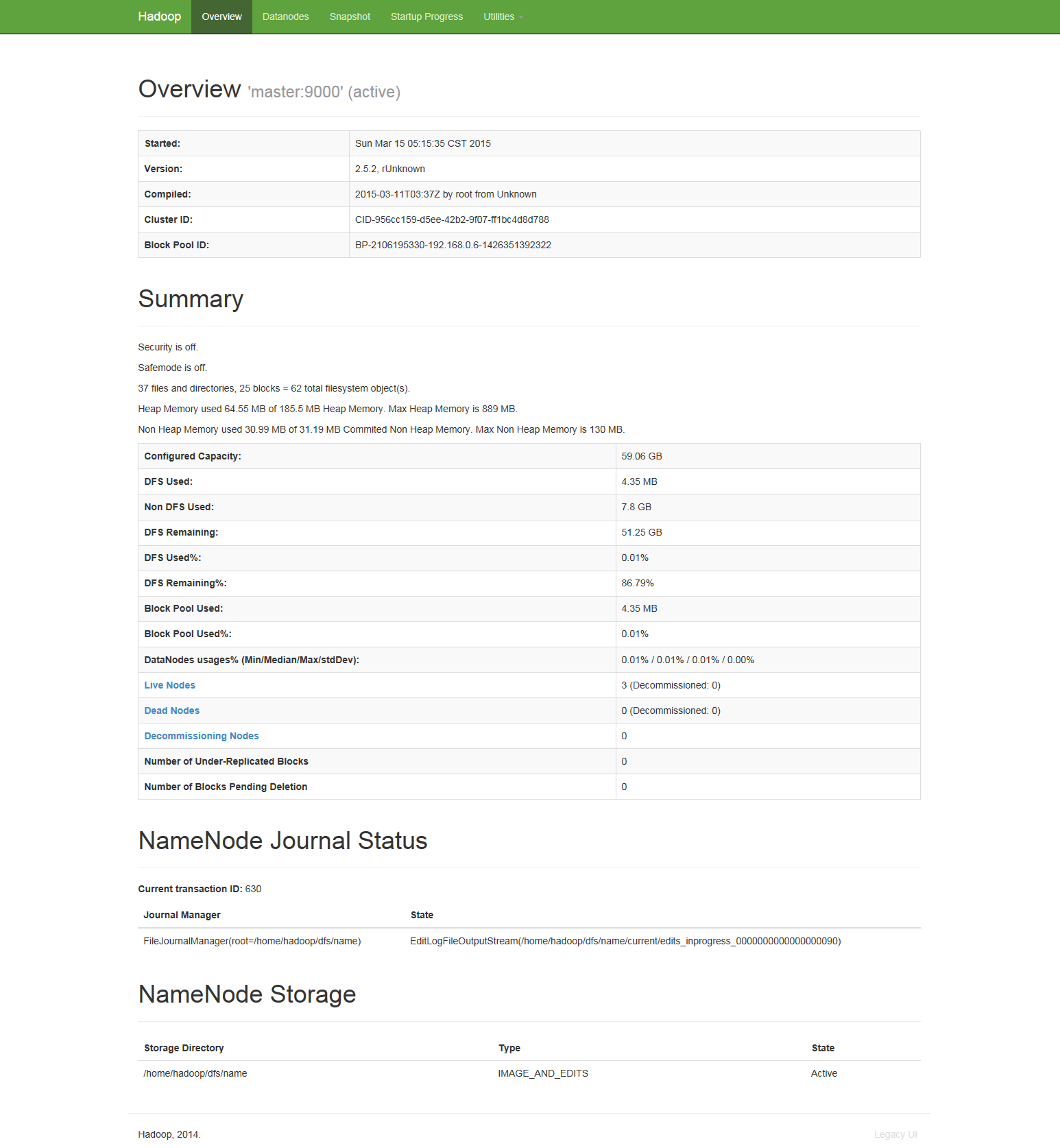

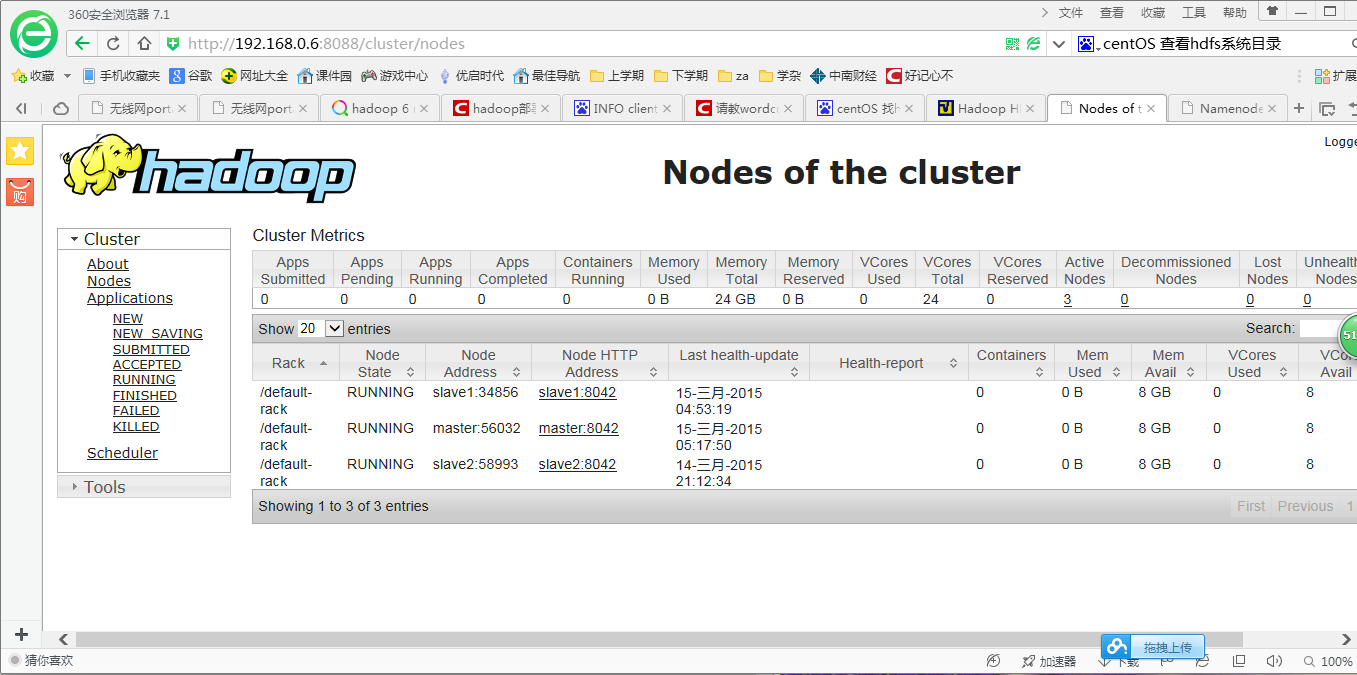
可以看到live节点数和集群节点数均为3,基本可以确定配置成功了,接下来就来测试一下吧。
三.集群测试
1.圆周率
这是mongodb蒙特卡洛算法计算圆周率的测试用例,pi后跟的两个数字分别表示使用多少个map以及计算的精度。
cd /home/hadoop/hadoop-2.5.2
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.2.jar pi 10 1000
测试结果如下:
|
[root@master ~]# cd /home/hadoop/hadoop-2.5.2 [root@master hadoop-2.5.2]# bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.2.jar pi 10 1000 Number of Maps = 10 Samples per Map = 1000 Wrote input for Map #0 Wrote input for Map #1 Wrote input for Map #2 Wrote input for Map #3 Wrote input for Map #4 Wrote input for Map #5 Wrote input for Map #6 Wrote input for Map #7 Wrote input for Map #8 Wrote input for Map #9 Starting Job 15/03/15 18:59:14 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.0.6:8032 15/03/15 18:59:14 INFO input.FileInputFormat: Total input paths to process : 10 15/03/15 18:59:14 INFO mapreduce.JobSubmitter: number of splits:10 15/03/15 18:59:15 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1426367748160_0006 15/03/15 18:59:15 INFO impl.YarnClientImpl: Submitted application application_1426367748160_0006 15/03/15 18:59:15 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1426367748160_0006/ 15/03/15 18:59:15 INFO mapreduce.Job: Running job: job_1426367748160_0006 15/03/15 18:59:21 INFO mapreduce.Job: Job job_1426367748160_0006 running in uber mode : false 15/03/15 18:59:21 INFO mapreduce.Job: map 0% reduce 0% 15/03/15 18:59:34 INFO mapreduce.Job: map 40% reduce 0% 15/03/15 18:59:41 INFO mapreduce.Job: map 100% reduce 0% 15/03/15 18:59:42 INFO mapreduce.Job: map 100% reduce 100% 15/03/15 18:59:43 INFO mapreduce.Job: Job job_1426367748160_0006 completed successfully 15/03/15 18:59:44 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=226 FILE: Number of bytes written=1070916 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=2610 HDFS: Number of bytes written=215 HDFS: Number of read operations=43 HDFS: Number of large read operations=0 HDFS: Number of write operations=3 Job Counters Launched map tasks=10 Launched reduce tasks=1 Data-local map tasks=10 Total time spent by all maps in occupied slots (ms)=154713 Total time spent by all reduces in occupied slots (ms)=5591 Total time spent by all map tasks (ms)=154713 Total time spent by all reduce tasks (ms)=5591 Total vcore-seconds taken by all map tasks=154713 Total vcore-seconds taken by all reduce tasks=5591 Total megabyte-seconds taken by all map tasks=158426112 Total megabyte-seconds taken by all reduce tasks=5725184 Map-Reduce Framework Map input records=10 Map output records=20 Map output bytes=180 Map output materialized bytes=280 Input split bytes=1430 Combine input records=0 Combine output records=0 Reduce input groups=2 Reduce shuffle bytes=280 Reduce input records=20 Reduce output records=0 Spilled Records=40 Shuffled Maps =10 Failed Shuffles=0 Merged Map outputs=10 GC time elapsed (ms)=930 CPU time spent (ms)=5540 Physical memory (bytes) snapshot=2623418368 Virtual memory (bytes) snapshot=9755574272 Total committed heap usage (bytes)=1940914176 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=1180 File Output Format Counters Bytes Written=97 Job Finished in 29.79 seconds Estimated value of Pi is 3.14080000000000000000 [root@master hadoop-2.5.2]# |
2. 单词统计
|
1.进入到hadoop-2.5.2目录下 cd /home/hadoop/hadoop-2.5.2 2.创建tmp文件 bin/hdfs dfs -mkdir /tmp 3.事先在hadoop-2.5.2目录下创建好一个test.txt文件,作为测试文件 4.将测试文件上传到tmp文件中 bin/hdfs dfs -copyFromLocal / home/hadoop/hadoop-2.5.2/test.txt /tmp 5.查看是否上传成功 bin/hdfs dfs -ls /tmp 6.执行hadoop-mapreduce-examples-2.5.2.jar里面的wordcount bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.2.jar wordcount /tmp/test.txt /tmp-output 7.查看结果 bin/hdfs dfs -ls /tmp-output bin/hadoop fs -cat /tmp-output/part-r-00000 Ps:再次运行时需要先删除hdfs系统目录里的tmp-output文件夹 [root@master hadoop-2.5.2]# bin/hdfs dfs -rmdir /tmp-output |

四.实验中遇到的问题
1.Namenode无法启动
造成有个问题的原因最常见的是多次格式化namenode造成的,即 namespaceID 不一致。这种情况清空logs,重启启动有时候甚至有时候都没有datanode的日志产生。
解决方法:找到不一致的 VERSION 修改 namespaceID
或者:删除 hdfs/data 中全部文件,重新初始化namenode,这样做数据就全部没了(看到的结果是这样)
PS : 还有一种说法造成启动不了datanode的原因是 data文件的权限问题,这个问题目前没有遇到
删除了data中所有文件重新初始化后,问题解决
2. nodemanager无法启动
一开始他运行了,后来又停止了,查资料将所有的name文件夹清空,重新格式化,之后nodemanager出现。
3.结点信息中有两个slave的信息,但是集群信息中只有master的信息。
解决办法:将主机配置文件scp到slave上
cd /home/hadoop/hadoop-2.5.2/etc
scp -r hadoop root@slave1:/home/hadoop/hadoop-2.5.2/etc
scp -r hadoop root@slave2:/home/hadoop/hadoop-2.5.2/etc
4. 单词统计失败
出错原因与解决方法