文件 FILE
读取文件:
open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:
使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode):open(file, mode='r')
完整语法格式:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
- file: 必需,文件路径(相对或者绝对路径)。
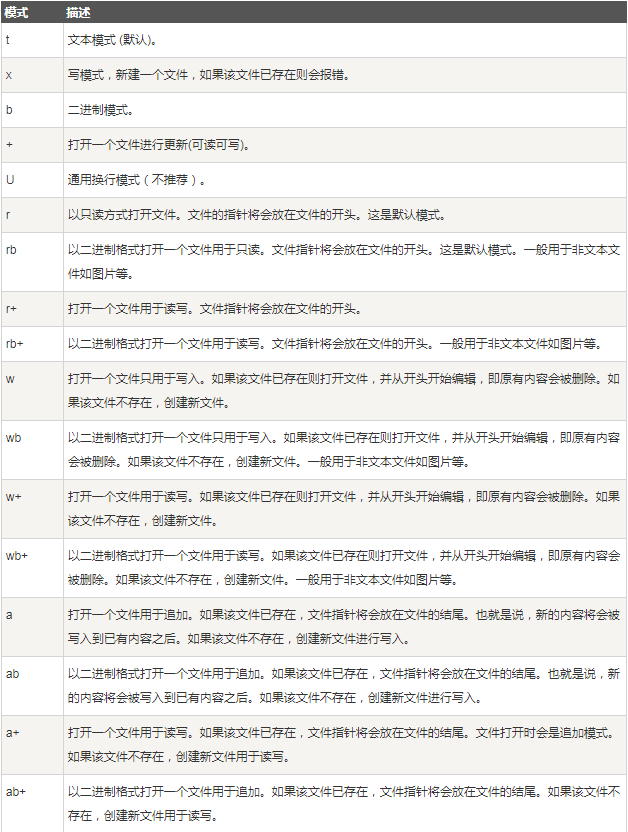
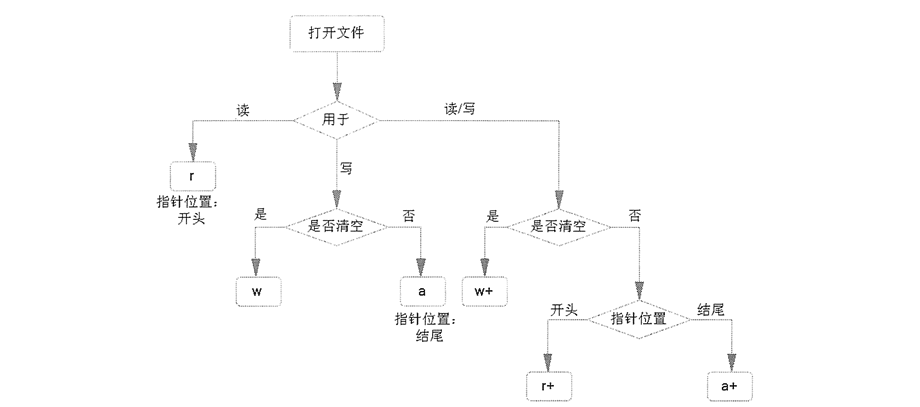
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf-8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener:
file的参数
相对路径:与当前运行的程序所在位置一致。
要么 将数据存储在程序文件所在的目录;要么将其存储在程序文件所在目录的下一个文件夹。中。
绝对路径:文件的准确位置。
windows系统使用反斜杠“”。因为“”是转移标记,所以在开头的单引号前加上r。
Linux和OS X中,使用斜杠“/”
mode的参数
读取整个文件与逐行读取。
读取整个文件
with open('py.txt') as file_object: contents = file_object.read() print(file_object) #out;<_io.TextIOWrapper name='py.txt' mode='r' encoding='cp936'> print(contents)
逐行读取文件
with open('py.txt') as file_object: for line in file_object: print(line.rstrip())
将文件中的各行存储到列表中
with open('py.txt') as file_object: lines =file_object.readlines() print(lines)
此时如果遍历列表,则相当于逐行读取文件。
使用读取的文件
在使用关键字with时,open()返回的文件的对象只在with代码块内可用。
如果想在代码块外使用,可以将各行存储在一个列表中,在操作列表。
写入文件
如果需要换行,需要增加换行符。
with open('pyw.txt','w') as file_w: file_w.write('hello world') file_w.write('hello python') with open('pyw.txt','r') as file_r: c = file_r.read() print(c) #out:hello worldhello python
with open('pyw.txt','w') as file_w: file_w.write('hello world ') file_w.write('hello python ') with open('pyw.txt','r') as file_r: c = file_r.read() print(c) #out:hello world # hello python
r,r+的区别
path_file_1 = r'E:正则表达式 ext_1.txt' path_file_2 = r'E:正则表达式 ext_2.txt' with open(path_file_1, 'r+') as file_1: file_1.write('hello world python ') file_1.write('Hello World ') # 接着上面写;并不会覆盖 with open(path_file_2, 'r+') as file_2: file_2.write('hello world python') with open(path_file_2, 'r+') as file_2: file_2.write('Hello World ') # 指针在开头,并不是接着上面写;会覆盖原有内容。会从开头对原内容进行覆盖
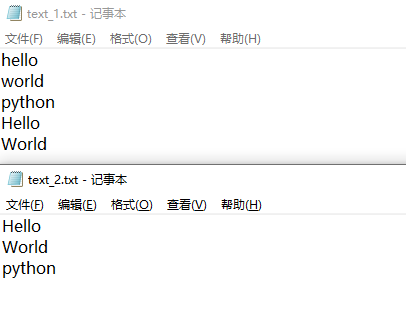
r+, w+, a+写入的区别
path_file_1 = r'E:正则表达式 ext_1.txt' path_file_2 = r'E:正则表达式 ext_2.txt' path_file_3 = r'E:正则表达式 ext_3.txt' with open(path_file_1, 'r+') as file_1: file_1.write('hello world python') with open(path_file_1, 'r+') as file_1: file_1.write('Hello World ') # 指针在开头,并不是接着上面写;会从开始覆盖原有内容,不一定能覆盖完,类似update with open(path_file_2, 'w+') as file_2: file_2.write('hello world python') with open(path_file_2, 'w+') as file_2: file_2.write('Hello World ') # 清空原有内容,重新写入类似先delete后insert with open(path_file_3, 'a+') as file_3: file_3.write('hello world python ') with open(path_file_3, 'a+') as file_3: file_3.write('Hello World ') # 指针在结尾,接着原有文件内容。类似insert
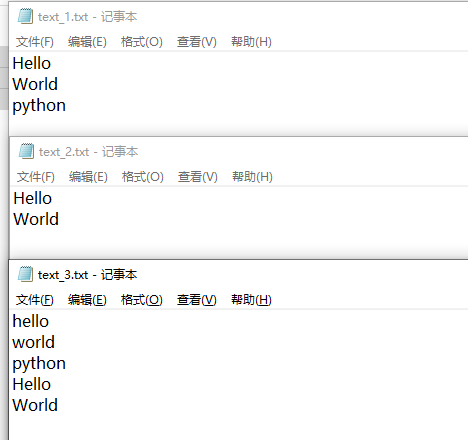
r, r+, w+, a+读取的区别
path_file_1 = r'E:正则表达式 ext_1.txt' path_file_2 = r'E:正则表达式 ext_2.txt' with open(path_file_1, 'r') as file_1: contents = file_1.read() print('r ', contents) # 可以直接读取文件 with open(path_file_1, 'r+') as file_1: contents = file_1.read() print('r+ ', contents) # 读取功能与r相同 with open(path_file_1, 'a+') as file_1: contents = file_1.read() print('a+ ', contents) # a+的指针在结尾,所以什么也没读到 with open(path_file_1, 'a+') as file_1: file_1.seek(0) contents = file_1.read() print('a+(0) ', contents) # a+的指针通过file_1.seek(0)移到开头,可以读到文件 with open(path_file_1, 'a+') as file_1: file_1.seek(1) contents = file_1.read() print('a+(1) ', contents) # a+的指针通过file_1.seek(1)进行移动,与seek(0)进行对比 with open(path_file_1, 'w+') as file_1: file_1.write('hello world python') file_1.seek(0) contents = file_1.read() print('w+ ', contents) # w+先清空,后写入,才可以读。此时指针在结尾,要移到开头。 with open(path_file_1, 'w+') as file_1: contents = file_1.read() print('w+ ', contents) # w+先清空,什么都没了,自然读不到。

总结:
加上f.seek(0)使得类指针的东西回到文件的开头然后从头开始读即可。
配合f.tell()使用,英文及字符返回的是那个类指针的位置(也就是字符个数),但是中文的话是字符 个数*3。
r+与w+啥区别呢,不能简单的理解为读写都可,细节之处略有不同!
r+:先读后写的话是在原有文本后添加, 因为读完后类指针已经在最末尾了,如果是先写后读的话,是从头开始覆盖式写(如只修改了前面的字符,后面字符是不会被删掉的),类指针停留在写完的末尾,不是文档末尾,可以读出未被覆盖写的部分;
w+:为先写后读,先写完后使用f.seek(0)回到初始位置然后开始读,如果先读的话是读不出任何东西的,因为w+也是纯粹的覆盖写,在未使用写操作前文档是完全空白的,无论之前该文件里有什么。so ,只能先写后读。
r和w的区别,r必须已经存在这个文件了而 w时文件可以有也可以没有,if有被覆盖,else没有则创建一个(慎用),r+的写也是覆盖的!
w与a的相同点:文件可以有也可以没有,if有被覆盖,else没有则创建一个(慎用)。指针都在末尾。
w与a的不同点:w先执行清空,a在原有的内容后面续写。
w+在w的基础上增加了读的功能,a+在a的基础上增加了读的功能。