Sqoop 产生背景
Sqoop 的产生主要源于以下几种需求:
1、多数使用 Hadoop 技术处理大数据业务的企业,有大量的数据存储在传统的关系型数据库(RDBMS)中。
2、由于缺乏工具的支持,对 Hadoop 和 传统数据库系统中的数据进行相互传输是一件十分困难的事情。
3、基于前两个方面的考虑,极需一个在 RDBMS 与 Hadoop 之间进行数据传输的项目。
sqoop 是什么
Sqoop 是连接传统关系型数据库和 Hadoop 的桥梁。它包括以下两个方面:
1、 将关系型数据库的数据导入到 Hadoop 及其相关的系统中,如 Hive和HBase。
2、 将数据从 Hadoop 系统里抽取并导出到关系型数据库。
Sqoop 的核心设计思想是利用 MapReduce 加快数据传输速度。也就是说 Sqoop 的导入和导出功能是通过 MapReduce 作业实现的。
所以它是一种批处理方式进行数据传输,难以实现实时的数据进行导入和导出。
为什么选择 Sqoop
我们为什么选择 Sqoop 呢?通常基于三个方面的考虑:
1、它可以高效、可控地利用资源,可以通过调整任务数来控制任务的并发度。另外它还可以配置数据库的访问时间等等。
2、它可以自动的完成数据类型映射与转换。我们往往导入的数据是有类型的,它可以自动根据数据库中的类型转换到 Hadoop 中,当然用户也可以自定义它们之间的映射关系。
3、它支持多种数据库,比如,Mysql、Oracle和PostgreSQL等等数据库。
Sqoop 架构
Sqoop 架构是非常简单的,它主要由三个部分组成:Sqoop client、HDFS/HBase/Hive、Database。下面我们来看一下 Sqoop 的架构图。
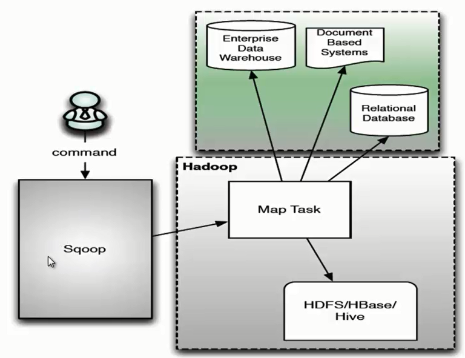
用户向 Sqoop 发起一个命令之后,这个命令会转换为一个基于 Map Task 的 MapReduce 作业。Map Task 会访问数据库的元数据信息,通过并行的 Map Task 将数据库的数据读取出来,然后导入 Hadoop 中。 当然也可以将 Hadoop 中的数据,导入传统的关系型数据库中。它的核心思想就是通过基于 Map Task (只有 map)的 MapReduce 作业,实现数据的并发拷贝和传输,这样可以大大提高效率。
Sqoop 环境安装部署
我们 Hadoop 集群安装的是 Hadoop2.2.0 版本,所以 Sqoop 安装版本也要与之相匹配,否则后面 Sqoop 工具的使用会出现问题。这里我们选择 sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz版本安装。 安装 Sqoop 很简单,分为以下几步完成。
1、首先将下载的 sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz放到 /usr/java/目录下,然后对安装包解压、修改文件名和修改用户权限。
[root@single-hadoop-dajiangtai-com java]# tar zxvf sqoop-1.4.6.bin__hadoop-1.0.0.tar.gz //解压
[root@single-hadoop-dajiangtai-com java]# rm sqoop-1.4.6.bin__hadoop-1.0.0.tar.gz //删除安装包
[root@single-hadoop-dajiangtai-com java]# mv sqoop-1.4.6.bin__hadoop-1.0.0 sqoop //修改安装文件目录
[root@single-hadoop-dajiangtai-com java]# chown -R hadoop:hadoop sqoop //赋予sqoop hadoop用户权限
2、切换到/sqoop/conf 目录下,执行以下命令。
[hadoop@single-hadoop-dajiangtai-com java]$ cd sqoop/conf
[hadoop@single-hadoop-dajiangtai-com java]$ mv sqoop-env-template.sh sqoop-env.sh
然后使用 vi sqoop-env.sh 命令,打开文件添加如下内容。
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/usr/java/hadoop-2.2.0-x64
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/usr/java/hadoop-2.2.0-x64
#set the path to where bin/hbase is available
#export HBASE_HOME=
#Set the path to where bin/hive is available
export HIVE_HOME=/usr/java/hive-1.0.0
#Set the path for where zookeper config dir is
#export ZOOCFGDIR=
如果数据读取不涉及hbase和hive,那么相关hbase和hive的配置可以不加;如果集群有独立的zookeeper集群,那么配置zookeeper,反之,不用配置。
3、将相关的驱动 jar 包拷贝到 sqoop/lib 目录下。安装 Hadoop2.2.0 的核心 jar包有三个需要导入:commons-cli-1.2.jar、hadoop-common-2.2.0.jar和hadoop-mapreduce-client-core-2.2.0.jar。 数据库驱动 jar 包需要导入,这里我们使用的是 mysql 数据库,所以需要导入mysql-connector-java-5.1.21.jar包。
[hadoop@single-hadoop-dajiangtai-com lib]$ cp commons-cli-1.2.jar /usr/java/sqoop/lib
[hadoop@single-hadoop-dajiangtai-com common]$ cp hadoop-common-2.2.0.jar /usr/java/sqoop/lib
[hadoop@single-hadoop-dajiangtai-com mapreduce]$ cp hadoop-mapreduce-client-core-2.2.0.jar /usr/java/sqoop/lib
[hadoop@single-hadoop-dajiangtai-com java]$ cp mysql-connector-java-5.1.21.jar /usr/java/sqoop/lib
4、添加环境变量。
[hadoop@single-hadoop-dajiangtai-com java]$ vi ~/.bash_profile
PATH=$PATH:$HOME/bin
export SQOOP_HOME=/usr/java/sqoop //sqoop安装目录
export PATH=$PATH:$SQOOP_HOME/bin
source ~/.bash_profile
5、测试运行
[hadoop@single-hadoop-dajiangtai-com java]$ sqoop list-databases
> --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop
> --username sqoop
> --password sqoop
15/06/03 02:47:27 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
15/06/03 02:47:27 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
15/06/03 02:47:28 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
information_schema
djtdb_demo
djtdb_hadoop
djtdb_www