上一篇大概写了下lxml的用法,今天我们通过案例来实践,爬取我的博客博客并保存在本地
爬取博客园博客
爬取思路:
1、首先找到需要爬取的博客园地址
2、解析博客园地址
# coding:utf-8 import requests from lxml import etree # 博客园地址 url = 'http://www.cnblogs.com/qican/' headers = { "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36" } html =requests.get(url,headers=headers).text # 解析html内容 xml = etree.HTML(html)
3、通过博客名称抓取博客标题和详情链接。
经过分析数据我们需要a标签下的文字和href内容
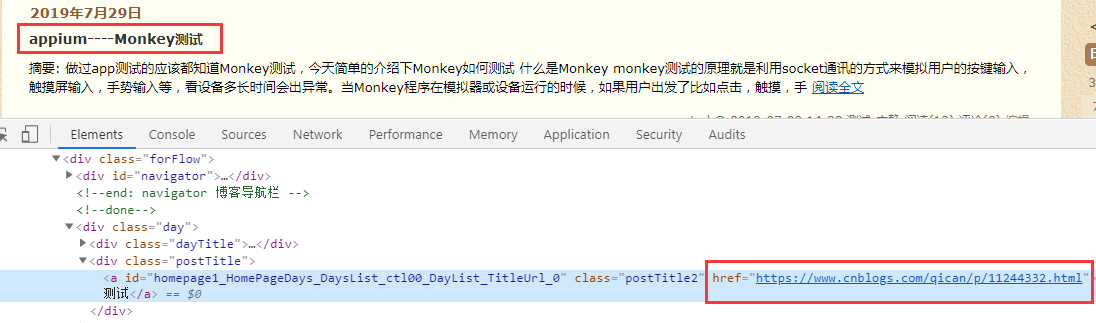
# 标题 title_list = xml.xpath('//div[@class="postTitle"]/a/text()') # 链接url url_list = xml.xpath('//div[@class="postTitle"]/a/@href')
4、再次请求博客详情链接获取博客内容
通过for循环获取到标题,链接内容,然后再次请求博客链接获取博客内容
for i,j in zip(title_list,url_list): # 再次请求博客链接 r2 = requests.get(j,headers=headers).text # 解析内容 xml_content = etree.HTML(r2) # 获取博客内容 content = xml_content.xpath('//div[@class="postBody"]//text()')
5、获取的博客内容写入到txt文件中。
通过with写入txt文件中,这里注意内容的编码格式
for x in content: print(x.strip()) with open(i+'.txt','a+',encoding='utf-8')as f: f.write(x)
写到这里发现我们都已经把博客内容写入了txt文件中,当然了这只是其中第一页的内容,我们通过观察url链接,发现分页是有page控制的,我们来模拟page数据获取全部博客内容
代码如下:
通过for循环获取模拟分页
# coding:utf-8 import requests from lxml import etree # 通过循环模拟url分页 for page in range(1,4): # 博客园地址 url = 'https://www.cnblogs.com/qican/default.html?page=%s'%page print(url) headers = { "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36" } html =requests.get(url,headers=headers).text # 解析html内容 xml = etree.HTML(html) # 标题 title_list = xml.xpath('//div[@class="postTitle"]/a/text()') # 链接url url_list = xml.xpath('//div[@class="postTitle"]/a/@href') for i,j in zip(title_list,url_list): print(i) # 再次请求博客链接 r2 = requests.get(j,headers=headers).text # 解析内容 xml_content = etree.HTML(r2) # 获取博客内容 content = xml_content.xpath('//div[@class="postBody"]//text()') # 写入内容 for x in content: print(x.strip()) with open(i+'.txt','a+',encoding='utf-8')as f: f.write(x)
简单的通过案例又一次加深了lxml的用法,当然方法很多种,喜欢哪种用哪种。~~~