
用之前所学的知识简单爬取了一个小说网站
这一次是这个网站

经过简单的爬取,前面步骤省略

可以得到这么个玩意

以及我想要的链接
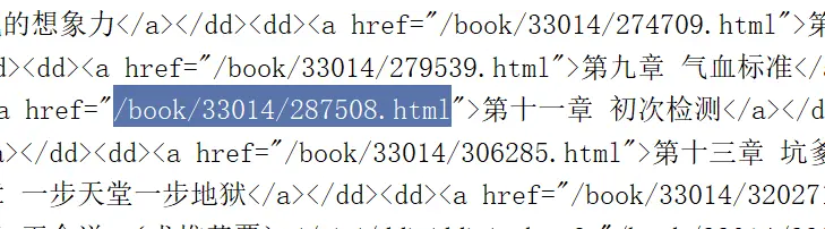
下一步,开始清除标签:
此时需要借用正则表达式来进行
首先导入re库
import re
再然后运用find_all()函数来寻找div标签下面的di_=list的内容
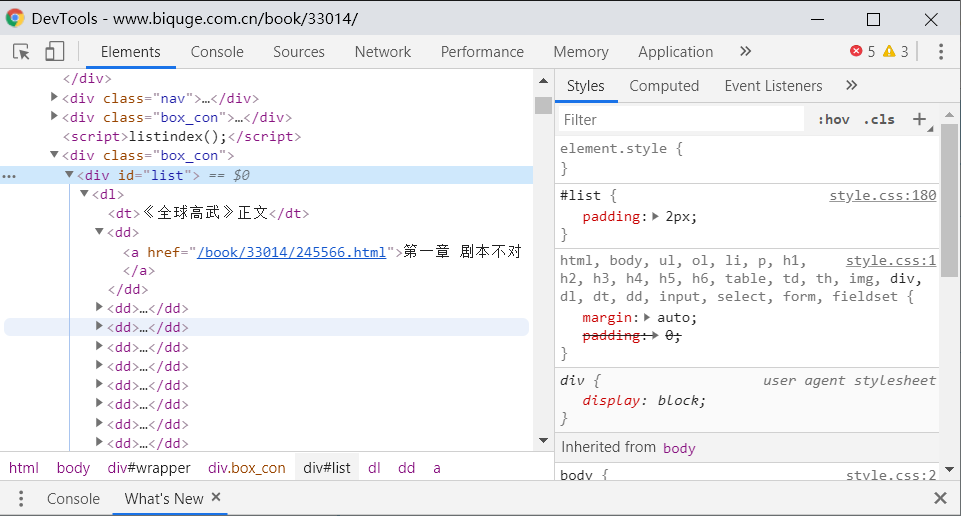
提取内容

那我们就可以以这里为开头,进行匹配
那在哪儿结束呢,这就涉及到了网页开发的知识了,
会有成对的字节,有a,那一定有/a,那也就是说有div,那一定有/div,
.*?呢,它表明了只要是以开头,以</div>结尾的字段,我都要。
注意每个网站的有可能不一样,不一定是div,其他的也行,html就是我们要匹配的对象
re.S(注意是大S)是说所有的符号都要匹配,默认换行等不匹配
[0]因为匹配到最后的是列表,要把它提取出来,如果匹配出来的有多个,
那也可以用这个去筛选,他在列表第一个就用[0],第二个就用[1],
一般来说不会出现这种情况,如果有,说明你用来匹配的字段不是唯一的

筛选到这里还是不行,它里面还有一些奇怪的字符
所以还要进行筛选

你不觉得我们要的内容他很有规律吗,我们只要以这个为模板,进行匹配就好了
(.*?) 这是什么,返向捕获,返回捕获的内容,把我们想要的url和章节名称捕获就好了
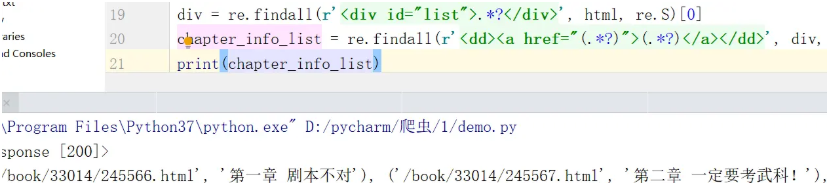
接下来我们循环访问我们捕获的url
再把url的内容下载下来就好了,在这之前我们还要再爬一个东西,
我们的小说名字,还是用我们的正则表达式
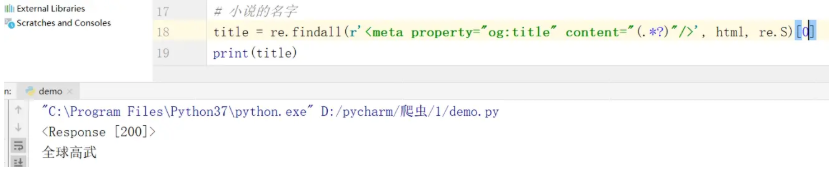
匹配字段一般来说是在head头里面
同时还要新建一个文件,以保存小说内容
接下来开始循环获取章节名和链接

再加上前缀域名就ok了
实际效果如下
