sklearn使用方法,包括从制作数据集,拆分数据集,调用模型,保存加载模型,分析结果,可视化结果
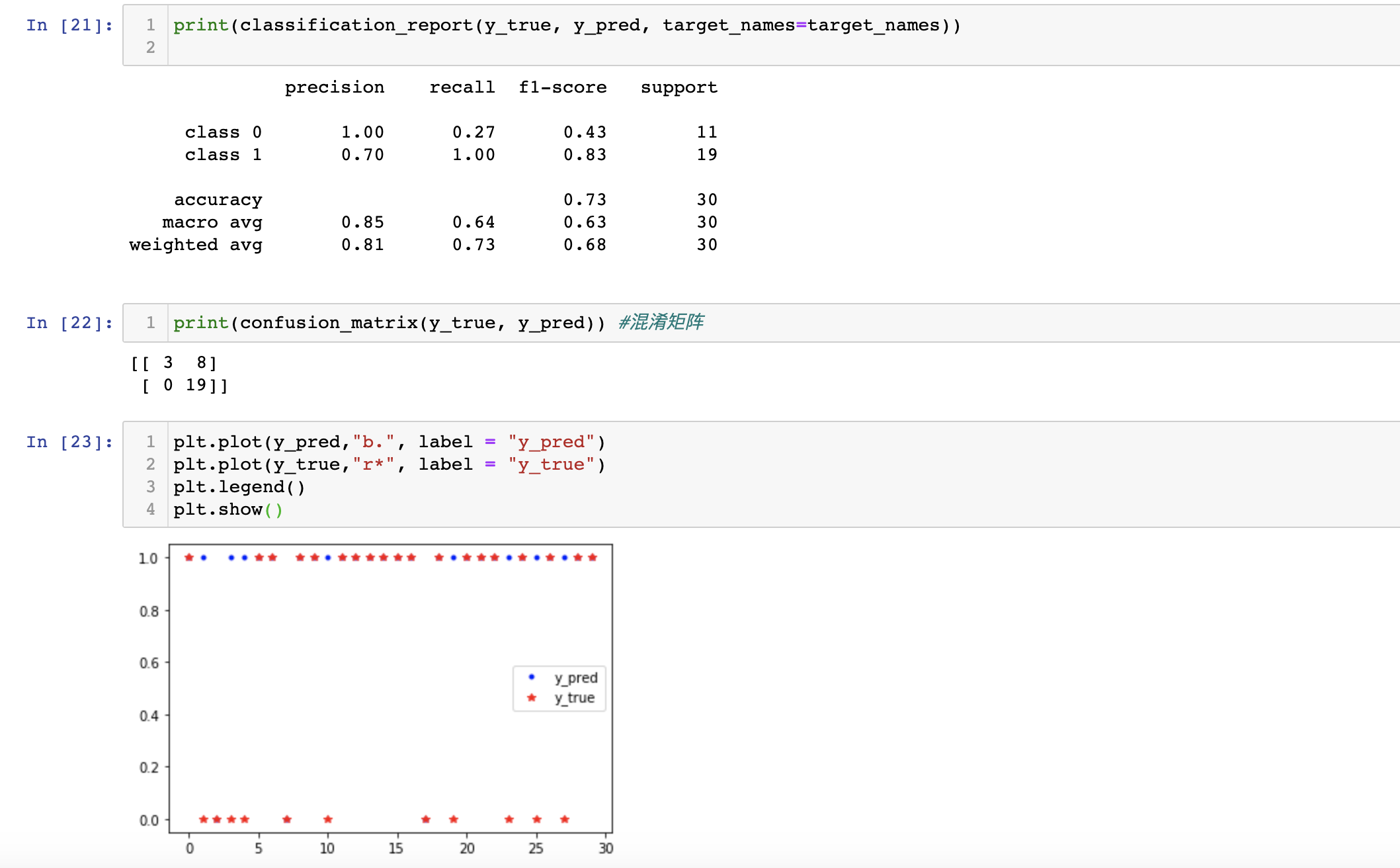
1 import pandas as pd 2 import numpy as np 3 from sklearn.model_selection import train_test_split #训练测试集拆分 4 from sklearn.linear_model import LogisticRegression #逻辑回归模型 5 import matplotlib.pyplot as plt #画图函数 6 7 from sklearn.externals import joblib #保存加载模型函数joblib 8 9 #以下为sklearn评测指标的一些函数 10 from sklearn.metrics import precision_score 11 from sklearn.metrics import classification_report 12 from sklearn.metrics import confusion_matrix 13 14 #1. 若有文件,建议用read_csv加载,用sep代表按照该符号分割,若文件无列标签名,则header设置为None,自定义标签名names 15 16 #file = "XXX_file" 17 #df = pd.read_csv(file, sep='###',header = None, names = ['flag','uuid','features'],engine = 'python') 18 #df.head() 19 20 21 #2. 准备好特征集合x 和 标签集合y 22 23 #x = df['features'] #x存储特征 24 #y = df['flag'] #y存储标签 25 x = np.random.rand(100,3) 26 print("x: ",x) 27 print(x.shape) 28 y = np.array([1 if i.sum()>1.2 else 0 for i in x]) #若三个维度之和大于1.2,则y分类为1,否则为0 29 print("y: ",y) 30 print(y.shape) #注意y的形式必须是(n,),即numpy中的一维格式 31 #当同时有 if 和 else 时,列表生成式构造为 [最终表达式 - 条件分支判断 - 范围选择] 32 33 34 #3. 拆分训练集和测试集(7:3) 35 x_train, x_test, y_train, y_test = train_test_split(x,y, random_state=666, train_size = 0.7) 36 37 38 #4. 生成模型,并喂入数据 39 clf = LogisticRegression() 40 clf.fit(x_train, y_train) 41 42 43 #5. 保存模型(用joblib,不用pickle) 44 joblib.dump(clf,"lr.model") #from sklearn.externals import joblib 45 #加载模型是: clf = joblib.load("lr.model") 46 47 48 #6. 预测结果,并评测 49 y_pred = clf.predict(x_test) #预测出来的值计做y_pred 50 y_true = y_test #真实值计做y_true,和sklearn参数一模一样 51 52 target_names = ['class 0', 'class 1'] 53 print(classification_report(y_true, y_pred, target_names=target_names)) #可以参考sklearn官网API 54 print(confusion_matrix(y_true, y_pred)) #混淆矩阵(记住!sklearn定义的混淆矩阵m行n列含义是:该样本真实值是m,预测值是n) 55 print("precision_score:", precision_score(y_test,y_pred)) #打印精确率(记住!默认是positive,即标注为1的精确率) 56 57 58 #7. 附加:结果可视化,利用plt(用seaborn也可以) 59 """ 60 #神秘代码,主要是保证plt字体显示正确 61 plt.rcParams['font.sans-serif'] = ['SimHei'] 62 plt.rcParams['font.family']='sans-serif' 63 plt.rcParams['axes.unicode_minus'] = False 64 """ 65 plt.plot(y_pred,"b.", label = "y_pred") #blue,点号 66 plt.plot(y_true,"r*", label = "y_true") #red,星号 67 plt.legend() 68 plt.show() #画的比较简略,可以进一步美化