@祁俊辉,2017年6月15日测试。
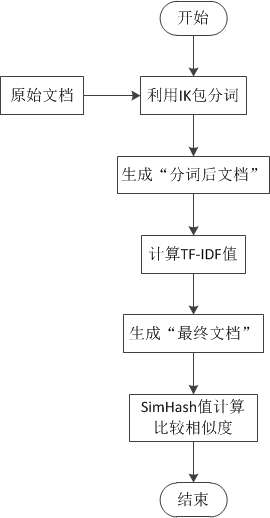
1 说明
- 本程序衔接关于SimHash算法的实现及测试V3.0;
- 改进1:增加TF-IDF算法,用于计算词权重(本地新增100篇txt文本库);
- 改进2:各个程序衔接,详情见流程图。
2 程序
目前项目中存在4个类,分别是分词“FenCi”,计算某个词在多少个文档中出现过“TxtComparison”,计算TF-IDF值“TF_IDF”,计算SimHash值及相似度比较“SimHash128Txt”。
2.1 FenCi
1 /* 【函数作用】对指定txt文档分词,存入另一文档中 2 * 【说明】1.该程序采用IK分词包(前向)进行分词 3 * 【时间】祁俊辉->2017.6.9 4 * */ 5 import java.io.*; 6 7 import org.apache.lucene.analysis.Analyzer; 8 import org.apache.lucene.analysis.TokenStream; 9 import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; 10 import org.wltea.analyzer.lucene.IKAnalyzer; 11 12 public class FenCi { 13 static String txt_ys = "./SimHash文档库/原始文档9.txt"; 14 static String txt_fch = "./SimHash文档库/分词后文档9.txt"; 15 static String txt_zh = "./SimHash文档库/最终文档9.txt"; 16 17 //输入字符串,输出分词后的字符串 18 public static String Seg(String sentence) throws IOException { 19 String text=""; 20 //创建分词对象 21 Analyzer anal=new IKAnalyzer(true); 22 StringReader reader=new StringReader(sentence); 23 //分词 24 TokenStream ts=anal.tokenStream("", reader); 25 CharTermAttribute term=ts.getAttribute(CharTermAttribute.class); 26 //遍历分词数据 27 while(ts.incrementToken()){ 28 text+=term.toString()+"/"; 29 } 30 reader.close(); 31 anal.close(); 32 return text.trim()+" "; 33 } 34 35 public static void main(String[] args) { 36 File file_ys = new File(FenCi.txt_ys);//原始文件 37 File file_fch = new File(FenCi.txt_fch);//分词后文件 38 try { 39 FileReader fr = new FileReader(file_ys); 40 BufferedReader bufr = new BufferedReader(fr); 41 FileWriter fw = new FileWriter(file_fch); 42 BufferedWriter bufw = new BufferedWriter(fw); 43 String s = null; 44 int i = 0; 45 while((s = bufr.readLine()) != null) { 46 i++; 47 String s_fch = FenCi.Seg(s); 48 System.out.println("第"+i+"行的原始数据:"); 49 System.out.println(s); 50 System.out.println("第"+i+"行分词后的结果:"); 51 System.out.println(s_fch); 52 bufw.write(s_fch); 53 bufw.newLine(); 54 } 55 bufr.close(); 56 fr.close(); 57 bufw.close(); 58 fw.close(); 59 System.out.println("文件处理完毕,已生成该文档的分词后文档!"); 60 } catch (Exception e) { 61 e.printStackTrace(); 62 } 63 } 64 }
2.2 TxtComparison
1 /* 【函数作用】判断str字符串在多少个文档中出现过 2 * 【说明】1.目前文件库有100篇文档,查找总耗时小于1秒 3 * 【说明】2.调用时,用"TxtComparison.Txt(str)",返回值为(出现次数+1) 4 * 【说明】3.之所以加1,是因为如果该词在文件库没有出现,则计算IDF值时会出错 5 * 【时间】祁俊辉->2017.6.14 6 * */ 7 import java.io.*; 8 9 public class TxtComparison { 10 public static int Txt(String str) { 11 int text_num = 0;//定义总出现次数 12 for(int i=0; i<100; i++){//遍历100篇文档 13 String filename = "./SimHash文档库/文件库/参考文档"; 14 filename += (i+".txt");//组合定义文件路径及文件名 15 File file_name = new File(filename);//创建文件路径 16 try { 17 InputStreamReader isr = new InputStreamReader(new FileInputStream(file_name),"UTF-8"); 18 //编码方式UTF-8,防止中文乱码 19 BufferedReader bufr = new BufferedReader(isr); 20 String s = null;//临时存储每行数据 21 boolean num = false;//临时存储目标文档是否含有指定字符串 22 while((s = bufr.readLine()) != null) {//遍历目标文档每行 23 //System.out.println(s); 24 if(s.contains(str)){//如果含有指定字符串 25 //System.out.println("第" + i + "篇文章中有"); 26 num = true;//标志位赋值 27 break;//退出(节省时间) 28 } 29 } 30 bufr.close(); 31 isr.close(); 32 if(num) {//根据标志位状态,让总出现次数增加 33 text_num ++; 34 } 35 } catch (Exception e) { 36 e.printStackTrace(); 37 } 38 } 39 return text_num+1;//返回总出现次数+1 40 } 41 }
2.3 TF_IDF
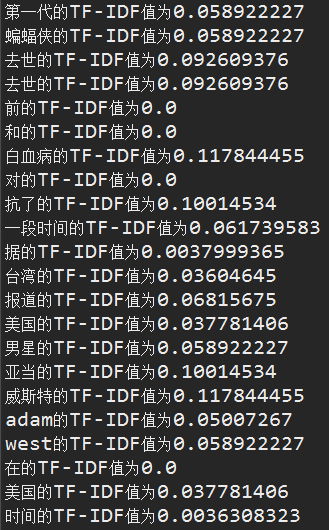
1 /* 【函数作用】计算分词后的文档各词的IF-IDF值 2 * 【说明】1.目前文件库有100篇文档,查找总耗时小于1秒 3 * 【说明】2.调用时,用"TxtComparison.Txt(str)",返回值为(出现次数+1) 4 * 【说明】3.之所以加1,是因为如果该词在文件库没有出现,则计算IDF值时会出错 5 * 【时间】祁俊辉->2017.6.14 6 * */ 7 import java.io.BufferedWriter; 8 import java.io.File; 9 import java.io.FileWriter; 10 import java.io.IOException; 11 12 public class TF_IDF { 13 14 public static void main(String[] args) throws IOException { 15 //生成的最终文件 16 File file_zh = new File(FenCi.txt_zh);//最终文件 17 FileWriter fw = new FileWriter(file_zh); 18 BufferedWriter bufw = new BufferedWriter(fw); 19 //对分词后的文档进行处理 20 String s = SimHash128Txt.Txt_read(FenCi.txt_fch); 21 String[] WordArray = s.split("/"); 22 23 for(int i=0; i<WordArray.length; i++){//遍历每个词 24 /*第一步:计算TF值*/ 25 int TF_Fre = 0;//定义频率为0 26 //计算每个词的频率 27 for(int j=0; j<WordArray.length; j++){ 28 if(WordArray[i].equals(WordArray[j])){ 29 TF_Fre++; 30 } 31 } 32 //频率归一化 33 float TF = (float) (1.0*TF_Fre/WordArray.length); 34 //System.out.println(WordArray[i]+"的TF值为"+TF); 35 /*第二步:计算IDF值*/ 36 //计算每个词在文件库出现的文件数 37 int IDF_a = TxtComparison.Txt(WordArray[i]); 38 //System.out.println(WordArray[i]+"在文件库中出现了"+IDF_a); 39 //总文件数 除以 该词在文件库中出现的次数 40 float IDF_b = (float) (101.0/IDF_a); 41 //System.out.println(IDF_b); 42 //IDF = log 2 (IDF_b) 43 float IDF = (float) (Math.log(IDF_b)/Math.log(2)); 44 //System.out.println(WordArray[i]+"的IDF值为"+IDF); 45 /*第三步:计算TF-IDF值*/ 46 float TFIDF = TF * IDF; 47 System.out.println(WordArray[i]+"的TF-IDF值为"+TFIDF); 48 /*第四步:将计算结果写入txt文件*/ 49 bufw.write(WordArray[i] + "##" + TFIDF + "/"); 50 bufw.newLine(); 51 } 52 bufw.close(); 53 fw.close(); 54 System.out.println("文件处理完毕,已生成该文档的最终文档!"); 55 } 56 }
2.4 SimHash128Txt
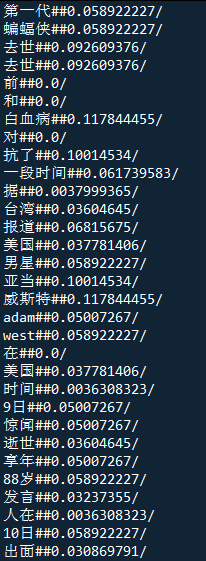
1 /* 【算法】SimHash->128位 2 * 【说明】1.加上权重(TF-IDF值) 3 * 【说明】2.经IK分词后,将分词后的文件存储,该程序进行读取 4 * 【时间】祁俊辉->2017.6.15 5 * */ 6 7 import java.io.*; 8 import java.math.BigInteger; 9 import java.security.MessageDigest; 10 11 public class SimHash128Txt { 12 //以下两个文档为新增文档,两段话,检测相似度 13 static String s9 = SimHash128Txt.Txt_read("./SimHash文档库/最终文档9.txt"); 14 static String s10 = SimHash128Txt.Txt_read("./SimHash文档库/最终文档10.txt"); 15 /* 函数名:Txt_read(String name) 16 * 功能:读取name文件的内容,name为txt文件名 17 * */ 18 static String Txt_read(String name){ 19 String s = ""; 20 File file = new File(name);//原始文件 21 try { 22 FileReader fr = new FileReader(file); 23 BufferedReader bufr = new BufferedReader(fr); 24 String s_x = null; 25 //int i = 0; 26 while((s_x = bufr.readLine()) != null) { 27 //i++; 28 //System.out.println("第"+i+"行的原始数据:"); 29 s += s_x; 30 } 31 bufr.close(); 32 fr.close(); 33 } catch (Exception e) { 34 e.printStackTrace(); 35 } 36 return s; 37 } 38 /* 函数名:MD5_Hash(String str) 39 * 功能:计算字符串str的128位hash值,并将其以String型返回 40 * */ 41 static String MD5_Hash(String str){ 42 try{ 43 // 生成一个MD5加密计算摘要 44 MessageDigest md = MessageDigest.getInstance("MD5"); 45 // 计算md5函数 46 //System.out.println("字符串:"+str); 47 //System.out.println("字符串的MD5_Hash:"+md.digest(str.getBytes())); 48 // digest()最后确定返回md5 hash值,返回值为8为字符串。因为md5 hash值是16位的hex值,实际上就是8位的字符 49 // BigInteger函数则将8位的字符串转换成16位hex值,用字符串来表示;得到字符串形式的hash值 50 return new BigInteger(1,md.digest(str.getBytes("UTF-8"))).toString(2); 51 }catch(Exception e){ 52 e.printStackTrace(); 53 return str; 54 } 55 } 56 /* 函数名:First_FC(String str) 57 * 功能:1.先创建一个存储SimHash值的128数组,并初始化为0 58 * 功能:2.将str字符串分词,并存入临时数组 59 * 功能:3.计算此字符串的SimHash值(加权、但没有降维),存储在数组中 60 * 功能:4.将数组中的SimHash值降维,并以字符串形式返回 61 * */ 62 static String First_FC(String str){ 63 //1.先创建一个存储SimHash值的128数组,并初始化为0 64 float Hash_SZ[] = new float[128]; 65 for(int i=0;i<Hash_SZ.length;i++) 66 Hash_SZ[i]=0; 67 //2.将str字符串分词,并将词和权重存入临时数组 68 String[] word_and_tfidf = str.split("/");//先分割 69 String[] word = new String[word_and_tfidf.length];//创建一个词数组,大小为词个数 70 String[] tfidf = new String[word_and_tfidf.length];//创建一个权重数组,大小为词个数 71 //分割词,存入数组 72 for(int i=0; i<word_and_tfidf.length; i++){ 73 String[] linshi = word_and_tfidf[i].split("##"); 74 word[i] = linshi[0]; 75 tfidf[i] = linshi[1]; 76 //System.out.println(word[i]+" "+tfidf[i]); 77 } 78 //3.计算此字符串的SimHash值(加权、但没有降维),存储在数组中 79 for(int i=0;i<word.length;i++){//循环传入字符串的每个词 80 String str_hash = SimHash128Txt.MD5_Hash(word[i]);//先计算每一个词的Hash值(128位) 81 //MD5哈希计算时,二进制转换若最高位为7以下,也就是转换成二进制最高位为0,会不存储该0,导致后面程序出错 82 //这里主要是为了保证它是128位的二进制 83 if(str_hash.length() < 128){ 84 int que = 128 - str_hash.length(); 85 for(int j=0;j<que;j++){ 86 str_hash = "0" + str_hash; 87 } 88 } 89 //System.out.println(str_hash);//输出该词的128位MD5哈希值 90 char str_hash_fb[]=str_hash.toCharArray();//将该词的哈希值转为数组,方便检查 91 //对每个词的Hash值(128位)求j位是1还是0,1的话加上该词的权重,0的话减去该词的权重 92 for(int j=0;j<Hash_SZ.length;j++){ 93 if(str_hash_fb[j] == '1'){ 94 Hash_SZ[j] += Float.parseFloat(tfidf[i]);//Hash_SZ中,0是最高位,依次排低 95 }else{ 96 Hash_SZ[j] -= Float.parseFloat(tfidf[i]); 97 } 98 } 99 } 100 //4.将数组中的SimHash值降维,并以字符串形式返回 101 String SimHash_number="";//存储SimHash值 102 for(int i=0;i<Hash_SZ.length;i++){//从高位到低位 103 System.out.print(Hash_SZ[i]+" ");//输出未降维的串 104 if(Hash_SZ[i]<=0)//小于等于0,就取0 105 SimHash_number += "0"; 106 else//大于0,就取1 107 SimHash_number += "1"; 108 } 109 System.out.println("");//换行 110 return SimHash_number; 111 } 112 /* 函数名:HMJL(String a,String b) 113 * 功能:a、b都是以String存储的二进制数,计算他们的海明距离,并将其返回 114 * */ 115 static int HMJL(String a,String b){ 116 char[] FW1 = a.toCharArray();//将a每一位都存入数组中 117 char[] FW2 = b.toCharArray();//将b每一位都存入数组中 118 int haiming=0; 119 if(FW1.length == FW2.length){//确保a和b的位数是相同的 120 for(int i=0;i<FW1.length;i++){ 121 if(FW1[i] != FW2[i])//如果该位不同,海明距离加1 122 haiming++; 123 } 124 } 125 return haiming; 126 } 127 128 public static void main(String[] args) { 129 String a9 = SimHash128Txt.First_FC(s9); 130 String a10 = SimHash128Txt.First_FC(s10); 131 System.out.println("【s9】的SimHash值为:"+a9); 132 System.out.println("【s10】的SimHash值为:"+a10); 133 System.out.println("【s9】和【s10】的海明距离为:" + SimHash128Txt.HMJL(a9,a10) + ",相似度为:" + (100-SimHash128Txt.HMJL(a9,a10)*100/128)+"%"); 134 } 135 }
3 测试结果
3.1 文件说明
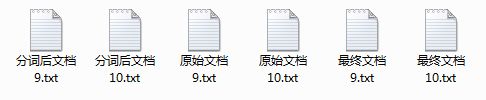
100篇文档(现代小说):

生成的文档(1篇待比较文本有3个文档:原始、分词后、最终):
3.2 输出结果