python时间戳
将时间戳转为日期
#!/usr/bin/python # -*- coding: UTF-8 -*- # 引入time模块 import time #时间戳 timeStamp = 1581004800 timeArray = time.localtime(timeStamp) #转为年-月-日形式 otherStyleTime = time.strftime("%Y-%m-%d ", timeArray) print(otherStyleTime)
python爬取数据教程(教程用于爬取动态加载的数据)
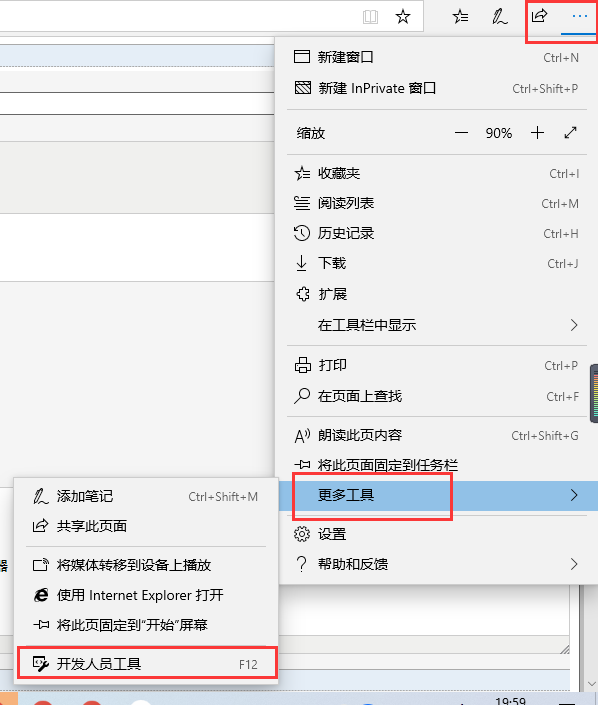
很多时候我们需要爬取网页动态加载的数据,这是我们通过打开该网页,按“Fn+F12”打开“开发者工具”。
edge浏览器打开开发者工具:
谷歌浏览器打开开发者工具:
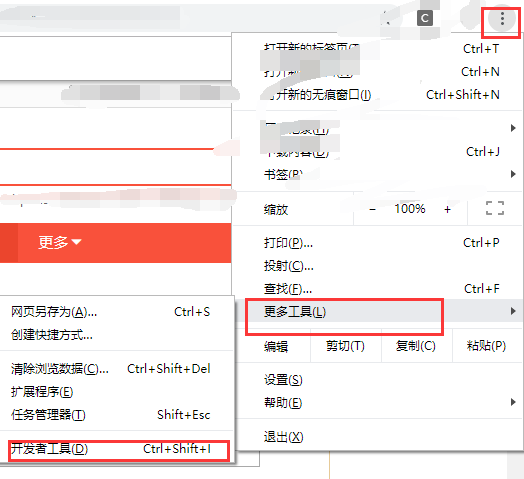
edge点击“网络”,谷歌点击“Network”,

找到我们要找文件,可以通过文件类型找,在标头我们可以看到请求URL在正文界面我们看到传过来的数据,我们要获取的就是dataprice,这个数据是json格式,python获取json数据就是一个字符串。
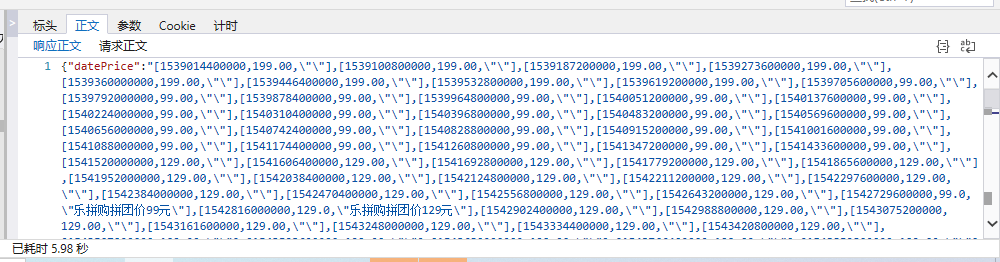
代码:
import requests import json import urllib request_url = "http://tool.manmanbuy.com/history.aspx?DA=1&action=gethistory&url=https%253A%2F%2Fproduct.suning.com%2F0070238646%2F10635620355.html&bjid=&spbh=&cxid=&zkid=&w=951&token=nvzld5767ed2371ac6b6e479dd20b3b3e191l9kvo7j" data = requests.get(request_url) data_price = json.loads(data.text) data_price = data_price['datePrice'] print(data_price)
运行结果:

这样我们就获取到了dataprice啦!
这不是结束,我们现在获取到了一个url对应的动态数据,但是我有几千条数据,所以我们研究一下这个requestURL,看看能不能进行构造(截图为谷歌浏览器截图)


通过对比几个requestURL,我发现这几个间不同之处为“url=”后和“token=”后不同,url是输入的链接,这个是我们自己可以传入的,但是这个token是什么呢?经过研究,我发现token在这里,但是他是随机生成的,如何获取这个字段呢?
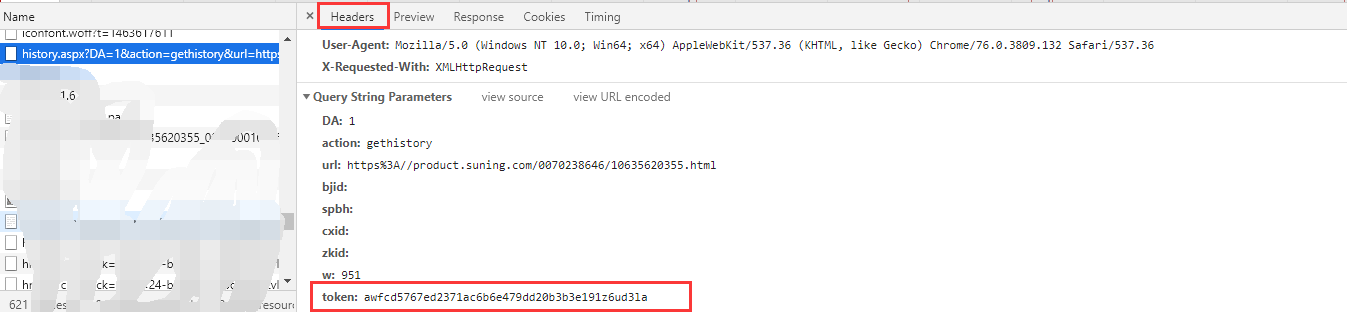
通过在网页右键“查看网页源代码”,或者在开发者工具点击第一个“Element”,查看源代码,我发现token在这里生成的。
但是没弄懂encrypt函数(有知道的大神可以告诉我,哈哈),只能另辟蹊径,再研究研究。哈哈,token又在这里出现了,最后,获取这个src路径,通过对字符串进行裁剪得到token的值。

这样我们就可以对requestURL进行构造啦,
request_url = "http://tool.manmanbuy.com/history.aspx?DA=1&action=gethistory&url={0}&bjid=&spbh=&cxid=&zkid=&w=951&token={1}".format(url,token)
再用上面的代码,我们就可以获取到所有的数据啦!