重温SQL——行转列,列转行(转:http://www.cnblogs.com/kerrycode/archive/2010/07/28/1786547.html)
我们首先先通过一个老生常谈的例子,学生成绩表(下面简化了些)来形象了解下行转列


 代码
代码
(
[UserName]NVARCHAR(20), --学生姓名
[Subject]NVARCHAR(30), --科目
[Score]FLOAT, --成绩
)
INSERTINTO[StudentScores]SELECT'Nick', '语文', 80
INSERTINTO[StudentScores]SELECT'Nick', '数学', 90
INSERTINTO[StudentScores]SELECT'Nick', '英语', 70
INSERTINTO[StudentScores]SELECT'Nick', '生物', 85
INSERTINTO[StudentScores]SELECT'Kent', '语文', 80
INSERTINTO[StudentScores]SELECT'Kent', '数学', 90
INSERTINTO[StudentScores]SELECT'Kent', '英语', 70
INSERTINTO[StudentScores]SELECT'Kent', '生物', 85
如果我想知道每位学生的每科成绩,而且每个学生的全部成绩排成一行,这样方便我查看、统计,导出数据

接下来我们来看看第二个小列子。有一个游戏玩家充值表(仅仅为了说明,举的一个小例子),
代码
(
[ID]INTIDENTITY(1,1),
[UserName]NVARCHAR(20), --游戏玩家
[CreateTime]DATETIME, --充值时间
[PayType]NVARCHAR(20), --充值类型
[Money]DECIMAL, --充值金额
[IsSuccess]BIT, --是否成功 1表示成功, 0表示失败
CONSTRAINT[PK_Inpours_ID]PRIMARYKEY(ID)
)
INSERTINTO Inpours SELECT'张三', '2010-05-01', '支付宝', 50, 1
INSERTINTO Inpours SELECT'张三', '2010-06-14', '支付宝', 50, 1
INSERTINTO Inpours SELECT'张三', '2010-06-14', '手机短信', 100, 1
INSERTINTO Inpours SELECT'李四', '2010-06-14', '手机短信', 100, 1
INSERTINTO Inpours SELECT'李四', '2010-07-14', '支付宝', 100, 1
INSERTINTO Inpours SELECT'王五', '2010-07-14', '工商银行卡', 100, 1
INSERTINTO Inpours SELECT'赵六', '2010-07-14', '建设银行卡', 100, 1
代码
CASE PayType WHEN'支付宝'THENSUM(Money) ELSE0ENDAS'支付宝',
CASE PayType WHEN'手机短信'THENSUM(Money) ELSE0ENDAS'手机短信',
CASE PayType WHEN'工商银行卡'THENSUM(Money) ELSE0ENDAS'工商银行卡',
CASE PayType WHEN'建设银行卡'THENSUM(Money) ELSE0ENDAS'建设银行卡'
FROM Inpours
GROUPBY CreateTime, PayType
如图所示,我们这样只是得到了这样的输出结果,还需进一步处理,才能得到想要的结果
 代码
代码
SELECT
CreateTime,
ISNULL(SUM([支付宝]), 0) AS[支付宝],
ISNULL(SUM([手机短信]), 0) AS[手机短信],
ISNULL(SUM([工商银行卡]), 0) AS[工商银行卡],
ISNULL(SUM([建设银行卡]), 0) AS[建设银行卡]
FROM
(
SELECTCONVERT(VARCHAR(10), CreateTime, 120) AS CreateTime,
CASE PayType WHEN'支付宝'THENSUM(Money) ELSE0ENDAS'支付宝',
CASE PayType WHEN'手机短信'THENSUM(Money) ELSE0ENDAS'手机短信',
CASE PayType WHEN'工商银行卡'THENSUM(Money) ELSE0ENDAS'工商银行卡',
CASE PayType WHEN'建设银行卡'THENSUM(Money) ELSE0ENDAS'建设银行卡'
FROM Inpours
GROUPBY CreateTime, PayType
) T
GROUPBY CreateTime
其实行转列,关键是要理清逻辑,而且对分组(Group by)概念比较清晰。上面两个列子基本上就是行转列的类型了。但是有个问题来了,上面是我为了说明弄的一个简单列子。实际中,可能支付方式特别多,而且逻辑也复杂很多,可能涉及汇率、手续费等等(曾经做个这样一个),如果支付方式特别多,我们的CASE WHEN 会弄出一大堆,确实比较恼火,而且新增一种支付方式,我们还得修改脚本如果把上面的脚本用动态SQL改写一下,我们就能轻松解决这个问题
代码
DECLARE@tmpSqlVARCHAR(8000);
SET@cmdText='SELECT CONVERT(VARCHAR(10), CreateTime, 120) AS CreateTime,'+CHAR(10);
SELECT@cmdText=@cmdText+' CASE PayType WHEN '''+ PayType +''' THEN SUM(Money) ELSE 0 END AS '''+ PayType
+''','+CHAR(10) FROM (SELECTDISTINCT PayType FROM Inpours ) T
SET@cmdText=LEFT(@cmdText, LEN(@cmdText) -2) --注意这里,如果没有加CHAR(10) 则用LEFT(@cmdText, LEN(@cmdText) -1)
SET@cmdText=@cmdText+' FROM Inpours GROUP BY CreateTime, PayType ';
SET@tmpSql='SELECT CreateTime,'+CHAR(10);
SELECT@tmpSql=@tmpSql+' ISNULL(SUM('+ PayType +'), 0) AS '''+ PayType +''','+CHAR(10)
FROM (SELECTDISTINCT PayType FROM Inpours ) T
SET@tmpSql=LEFT(@tmpSql, LEN(@tmpSql) -2) +' FROM ('+CHAR(10);
SET@cmdText=@tmpSql+@cmdText+') T GROUP BY CreateTime ';
PRINT@cmdText
EXECUTE (@cmdText);
下面是通过PIVOT来进行行转列的用法,大家可以对比一下,确实要简单、更具可读性(呵呵,习惯的前提下)
代码
CreateTime, [支付宝] , [手机短信],
[工商银行卡] , [建设银行卡]
FROM
(
SELECTCONVERT(VARCHAR(10), CreateTime, 120) AS CreateTime,PayType, Money
FROM Inpours
) P
PIVOT (
SUM(Money)
FOR PayType IN
([支付宝], [手机短信], [工商银行卡], [建设银行卡])
) AS T
ORDERBY CreateTime
有时可能会出现这样的错误:
消息 325,级别 15,状态 1,第 9 行
'PIVOT' 附近有语法错误。您可能需要将当前数据库的兼容级别设置为更高的值,以启用此功能。有关存储过程 sp_dbcmptlevel 的信息,请参见帮助。
这个是因为:对升级到 SQL Server 2005 或更高版本的数据库使用 PIVOT 和 UNPIVOT 时,必须将数据库的兼容级别设置为 90 或更高。有关如何设置数据库兼容级别的信息,请参阅 sp_dbcmptlevel (Transact-SQL)。 例如,只需在执行上面脚本前加上 EXEC sp_dbcmptlevel Test, 90; 就OK了, Test 是所在数据库的名称。
下面我们来看看列转行,主要是通过UNION ALL ,MAX来实现。假如有下面这么一个表
代码
(
ProgrectName NVARCHAR(20), --工程名称
OverseaSupply INT, --海外供应商供给数量
NativeSupply INT, --国内供应商供给数量
SouthSupply INT, --南方供应商供给数量
NorthSupply INT--北方供应商供给数量
)
INSERTINTO ProgrectDetail
SELECT'A', 100, 200, 50, 50
UNIONALL
SELECT'B', 200, 300, 150, 150
UNIONALL
SELECT'C', 159, 400, 20, 320
UNIONALL
SELECT'D', 250, 30, 15, 15
我们可以通过下面的脚本来实现,查询结果如下图所示
代码
MAX(OverseaSupply) AS'SupplyNum'
FROM ProgrectDetail
GROUPBY ProgrectName
UNIONALL
SELECT ProgrectName, 'NativeSupply'AS Supplier,
MAX(NativeSupply) AS'SupplyNum'
FROM ProgrectDetail
GROUPBY ProgrectName
UNIONALL
SELECT ProgrectName, 'SouthSupply'AS Supplier,
MAX(SouthSupply) AS'SupplyNum'
FROM ProgrectDetail
GROUPBY ProgrectName
UNIONALL
SELECT ProgrectName, 'NorthSupply'AS Supplier,
MAX(NorthSupply) AS'SupplyNum'
FROM ProgrectDetail
GROUPBY ProgrectName
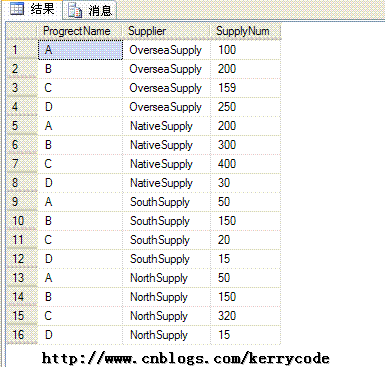
用UNPIVOT 实现如下:
代码
FROM
(
SELECT ProgrectName, OverseaSupply, NativeSupply,
SouthSupply, NorthSupply
FROM ProgrectDetail
)T
UNPIVOT
(
SupplyNum FOR Supplier IN
(OverseaSupply, NativeSupply, SouthSupply, NorthSupply )
) P
===================================================行转列============
===================================================行转列============
Connected to Oracle9i Enterprise Edition Release 9.2.0.1.0
Connected as SYS
SQL> create table t1("group" number(2),c1 number(2),c2 number(2),c3 number(2),c4 number(2));
Table created
SQL>
SQL> insert into t1 values(1,11,12,13,14);
1 row inserted
SQL> insert into t1 values(2,21,22,23,24);
1 row inserted
SQL> insert into t1 values(3,31,32,33,34);
1 row inserted
SQL> select * from t1;
group C1 C2 C3 C4
----- --- --- --- ---
1 11 12 13 14
2 21 22 23 24
3 31 32 33 34
SQL>
SQL> select "group",c1 c from t1
union all
select "group",c2 c from t1
union all
select "group",c3 c from t1
union all
select "group",c4 c from t1
order by "group";
group C
---------- ----------
1 11
1 12
1 13
1 14
2 21
2 23
2 24
2 22
3 31
3 34
3 33
3 32
12 rows selected
SQL>
===================================================列转行============
SQL> create table t2 as
select "group",c1 c from t1
union all
select "group",c2 c from t1
union all
select "group",c3 c from t1
union all
select "group",c4 c from t1
order by "group";
Table created
SQL> select * from t2;
group C
----- ---
1 11
1 12
1 13
1 14
2 21
2 23
2 24
2 22
3 31
3 34
3 33
3 32
12 rows selected
SQL>
SQL> SELECT "group",
MAX(decode(rn, 1, c, NULL)) AS c1,
MAX(decode(rn, 2, c, NULL)) AS c2,
MAX(decode(rn, 3, c, NULL)) AS c3,
MAX(decode(rn, 4, c, NULL)) AS c4
FROM (
select "group",c,row_number()over(partition by "group" order by "group") rn from t2
)
GROUP BY "group"
ORDER BY 1;
group C1 C2 C3 C4
----- ---------- ---------- ---------- ----------
1 11 12 13 14
2 21 23 24 22
3 31 34 33 32