zoukankan
html css js c++ java
虚拟机联网
虚拟机联网
一、打开虚拟网络编辑器
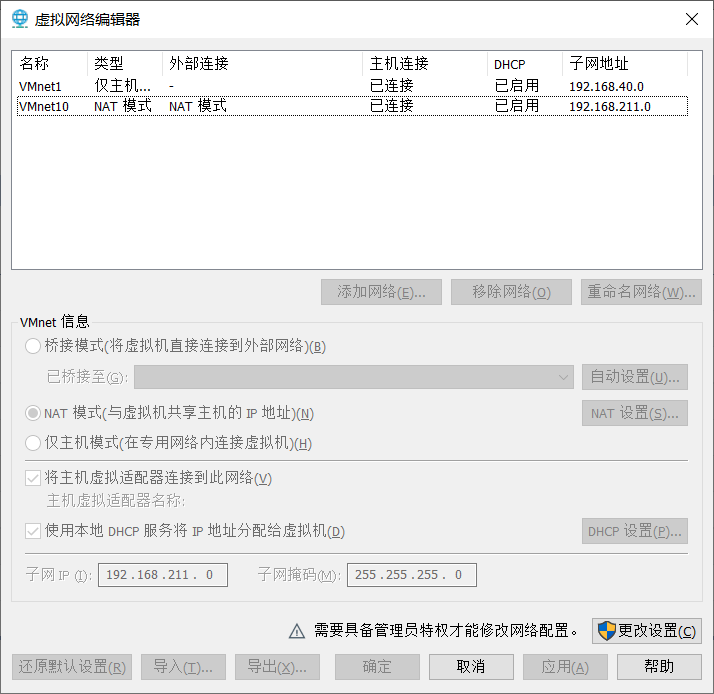
1.添加一个网络 选择net模式
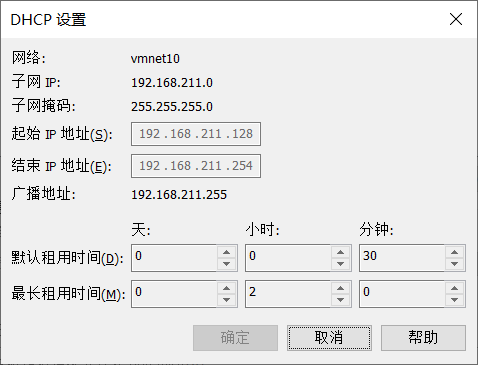
2.打开添加的网络的DHCP设置 记住ip段,之后在ubuntu内设置的ip要在这个ip段内
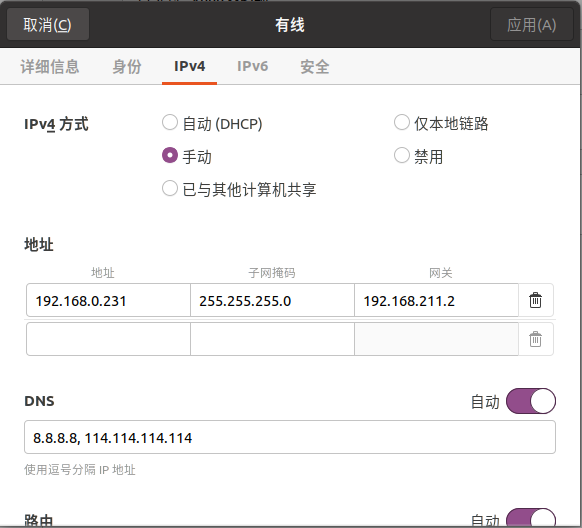
3.打开ubuntu内的网络设置,选择ipv4,手动方式,输入ip,掩码,网关,DNS
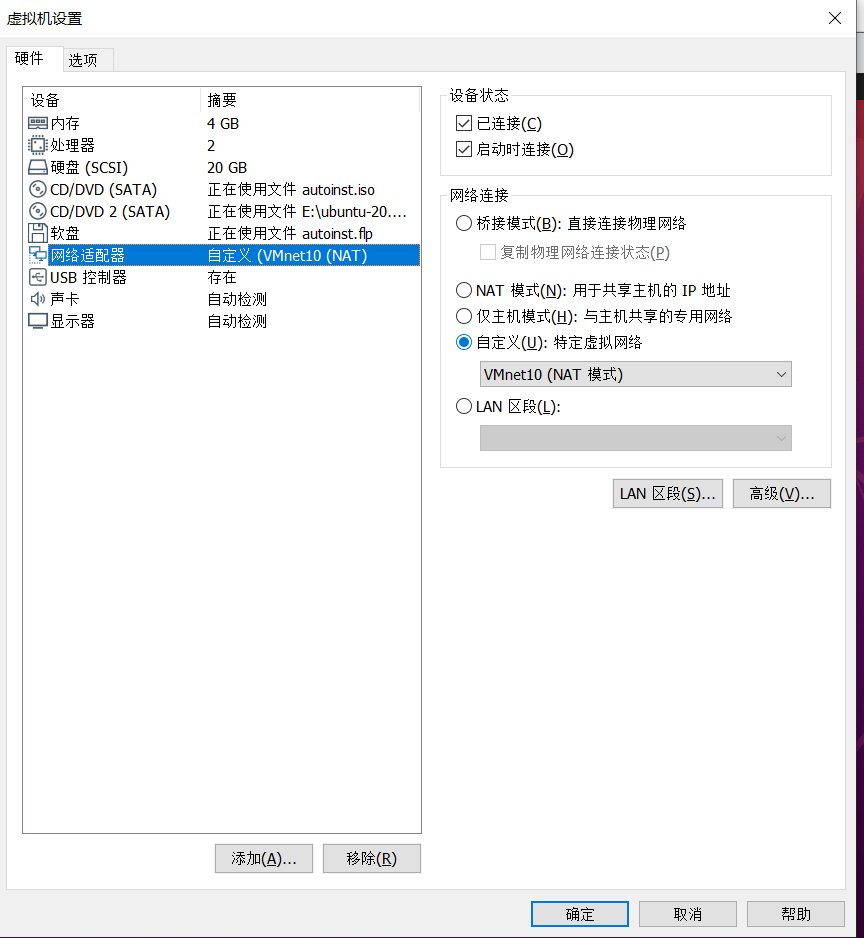
4.打开虚拟机设置,将网路适配器改成自定义,选用设置好的net网络
5.ping下百度,检查网络是否连接成功
查看全文
相关阅读:
C# 托管内存与非托管内存之间的转换
A*算法详解链接
【转】使用minizip解压缩多个文件(基于zlib)
lua中table的遍历,以及删除
clientHeight scrollHeight offsetHeight
消息中间件(转)
js 原型链和继承(转)
session 和 cookie (转)
java servlet
redis 命令
原文地址:https://www.cnblogs.com/qingjielaojiu/p/15703764.html
最新文章
使用ELK收集k8s集群日志
k8s安全机制
k8s各种资源terminating状态处理
有状态部署StatefulSet控制器
Pod 数据持久化(数据卷与数据持久化卷)
应用配置管理Secret&ConfigMap
深入理解 Ingress
Crontab中shell每分钟执行一次HDFS文件上传不执行的解决方案
windows环境下Eclipse开发MapReduce程序遇到的四个问题及解决办法
解决VS2010中在项目上右键鼠标,无“添加STS引用”菜单的问题
热门文章
Win7下VS2010使用“ASP.Net 3.5 Claims-aware Template”创建ClaimsAwareWebSite报"HRESULT: 0x80041FEB"错误的解决办法
分布式Hadoop安装(二)
分布式Hadoop安装(一)
J2EE Web开发入门—通过action是以传统方式返回JSON数据
[转]TrueType字体结构
TrueType字体
[转]TrueType(TTF)字体文件裁剪(支持简体中文,繁体中文TTF字体裁剪)
Lpeg
C#与C/C++的交互
理解 __declspec(dllexport)和__declspec(dllimport)
Copyright © 2011-2022 走看看