目录
1 前置条件
1.1 需要软件
1.2 配置pom.xml
2 编写代码
3 运行
1 前置条件
1.1 需要软件
需要Kafka环境。
1.2 配置pom.xml
配置相关jar。
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_2.12</artifactId><!-- 与Scala大版本号一致--> <version>1.9.2</version><!-- 与Flink版本号一致--> </dependency>
2 编写代码
Java版本代码
import java.util.Properties; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer; import org.apache.flink.streaming.util.serialization.SimpleStringSchema; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.util.Collector; public class KafkaWordCount { private static final String READ_TOPIC = "student"; public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("zookeeper.connect", "localhost:2181"); props.put("group.id", "student-group"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("auto.offset.reset", "latest"); DataStreamSource<String> student = env.addSource(new FlinkKafkaConsumer<>( READ_TOPIC, new SimpleStringSchema(), props)).setParallelism(1); DataStream<Tuple2<String, Integer>> counts = student.flatMap(new LineSplitter()).keyBy(0).sum(1); counts.print(); env.execute("flink custom kafka"); } public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> { private static final long serialVersionUID = 1L; public void flatMap(String value, Collector<Tuple2<String, Integer>> out) { String[] tokens = value.toLowerCase().split("\W+"); for (String token : tokens) { if (token.length() > 0) { out.collect(new Tuple2<String, Integer>(token, 1)); } } } } }
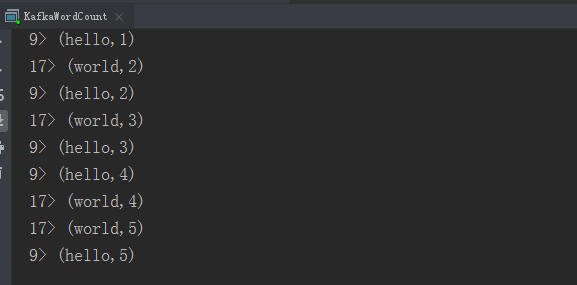
3 运行
1)运行结果