(一)Linux基本概念及操作
一、Linux桌面环境
常见的桌面环境有: KDE,GNOME,XFCE,LXDE
二、终端
终端本质上是对应着 Linux 上的 /dev/tty 设备,Linux 的多用户登录就是通过不同的 /dev/tty 设备完成的。
Linux 默认提供了 6 个纯命令行界面的 “terminal”(准确的说这里应该是 6 个 virtual consoles)来让用户登录。在物理机系统上你可以通过使用[Ctrl]+[Alt]+[F1]~[F6]进行切换,不过在我们的在线实验环境中可能无法切换,因为特殊功能按键会被你的主机系统劫持。当你切换到其中一个终端后想要切换回图形界面,你可以按下[Ctrl]+[Alt]+[F7]来完成。
三、Shell
Shell是指“提供给使用者使用界面”的软件(命令解析器),类似于 DOS 下的 command(命令行)和后来的 cmd.exe 。普通意义上的 Shell 就是可以接受用户输入命令的程序。它之所以被称作 Shell 是因为它隐藏了操作系统底层的细节。
在 UNIX/Linux 中比较流行的常见的 Shell 有 bash、zsh、ksh、csh 等等,Ubuntu 终端默认使用的是 bash,默认的桌面环境是 GNOME 或者 Unity(基于 GNOME)。
四、命令行操作
1、重要快捷键
| 快捷键 | 作用 |
| Tab | 用于补全命令、目录、命令参数等 |
| Ctrl+C | 强行终止当前程序 |
| Ctrl+D | 键盘输入结束或退出终端 |
| Ctrl+Z | 将当前程序放到后台运行,恢复到前台为命令fg |
| Ctrl+A | 将光标移至输入行头,相当于Home键 |
| Ctrl+E | 将光标移至输入行末,相当于End键 |
| Ctrl+K | 删除从光标所在位置到行末 |
| Alt+Backspace | 向前删除一个单词 |
| Shift+PgUp | 将终端显示向上滚动 |
| Shift+PgDn | 将终端显示向下滚动 |
2) 历史输入命令
使用键盘上的方向上键↑,恢复之前输入过的命令。
3)Shell 常用通配符
| 字符 | 含义 |
| * | 匹配 0 或多个字符 |
| ? | 匹配任意一个字符 |
| [list] | 匹配 list 中的任意单一字符 |
| [^list] | 匹配 除 list 中的任意单一字符以外的字符 |
| [c1-c2] | 匹配 c1-c2 中的任意单一字符 如:[0-9][a-z] |
| {string1,string2,...} | 匹配 string1 或 string2 (或更多)其一字符串 |
| {c1..c2} | 匹配 c1-c2 中全部字符 如{1..10} |
4)在命令行中获取帮助
man <command_name> //获得某个命令的说明和使用方式的详细介绍
比如你想查看 man 命令本身的使用方式,你可以输入:
man man
man手册一般被分为八个区,说明如下: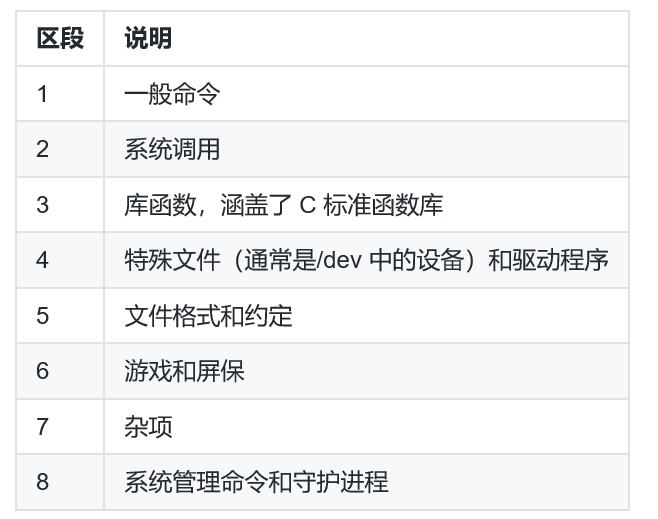
(二)用户及文件权限管理
一、Linux用户管理
1)查看用户
1. who am i
2. who mom likes
2)创建用户
在 Linux 系统里, root 账户拥有整个系统至高无上的权限,比如新建和添加用户。
用到了sudo命令,使用这个命令有两个大前提,一是你要知道当前登录用户的密码,二是当前用户必须在 sudo 用户组。
1. 新建一个名叫lilei的用户
sudo adduser lilei
用户密码以通过 sudo passwd 命令进行设置
2. 切换用户
su -l lilei
3)用户组
在 Linux 里面如何知道自己属于哪些用户组呢?
方法一:groups shiyanlou
方法二:cat /etc/group
4)删除用户和用户组
sudo deluser lilei --remove-home //删除用户,使用--remove-home参数在删除用户时候会一并将该用户的工作目录一并删除
groupdel 用户组名 //删除用户组,若该群组中仍包括某些用户,则必须先删除这些用户后,才能删除群组。
二、Linux文件权限
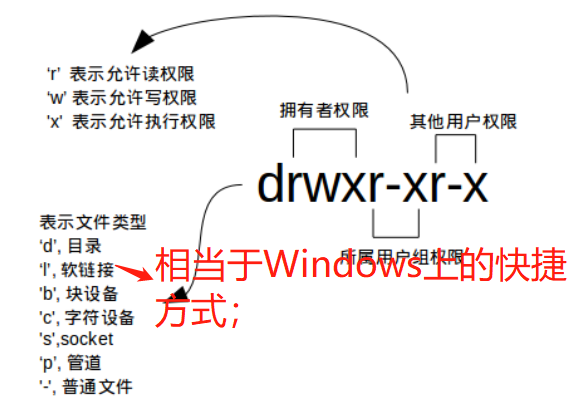
修改文件权限
方法一:二进制数字表示
每个文件有三组固定的权限,分别对应拥有者,所属用户组,其他用户,记住这个顺序是固定的。文件的读写执行对应字母 rwx,以二进制表示就是 111,用十进制表示就是 7
chmod 600 文件名
方法二:加减赋值操作
chmod go-rw 文件名
g、o 还有 u 分别表示 group(用户组)、others(其他用户) 和 user(用户),+ 和 - 分别表示增加和去掉相应的权限。
adduser 和 useradd 的区别是什么
答:useradd 只创建用户,不会创建用户密码和工作目录,创建完了需要使用 passwd <username> 去设置新用户的密码。adduser 在创建用户的同时,会创建工作目录和密码(提示你设置),做这一系列的操作。其实 useradd、userdel 这类操作更像是一种命令,执行完了就返回。而 adduser 更像是一种程序,需要你输入、确定等一系列操作。
(三)Linux 目录结构及文件基本操作
一、Linux目录结构
1)FHS标准
FHS 定义了两层规范:
第一层是, / 下面的各个目录应该要放什么文件数据,例如 /etc 应该放置设置文件,/bin 与 /sbin 则应该放置可执行文件等等。
第二层则是针对 /usr 及 /var 这两个目录的子目录来定义。例如 /var/log 放置系统日志文件,/usr/share 放置共享数据等等。
2)目录路径
1. 进入上级目录:cd ../
2. 进入home目录:cd ~
3. 获取当前目录:pwd
4. 相对路径:也就是相对于你当前的目录的路径,相对路径是以当前目录 . 为起点,以你所要到的目录为终点。
5. 绝对路径:以根" / "目录为起点的完整路径,以你所要到的目录为终点。
二、Linux 文件的基本操作
1)新建
1. 新建空白文件:touch test
2. 新建目录:mkdir mydir
注:若当前目录已经创建了一个 test 文件,再使用 mkdir test 新建同名的文件夹,系统会报错文件已存在。这符合 Linux 一切皆文件的理念。若当前目录存在一个 test 文件夹,则 touch 命令,则会更改该文件夹的时间戳而不是新建文件。
2)复制
1. 复制文件:cp 文件 指定目录
2. 复制目录:加上-r或-R表示递归复制
3)删除
1. 删除文件:rm 文件名(-f 表示强制删除)
2. 删除目录:rm -r 目录(也可加 -f 强制删除)
4)移动文件与文件重命名
1. 移动文件:mv 源目录文件 目标文件
2. 重命名:mv 旧的文件名 新的文件名
3. 批量重命名:rename 's/.txt/.c/' *.txt //将.txt后缀改为.c后缀
5)查看文件
1. 使用 cat,tac 和 nl 命令查看文件
前两个命令都是用来打印文件内容到标准输出(终端),其中 cat 为正序显示,tac 为倒序显示。-nl添加行数并打印。
2. more,less分页查看文件
more功能类似 cat ,cat命令是整个文件的内容从上到下显示在屏幕上。 more会以一页一页的显示方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示,按 b 键就会往回(back)一页显示,而且还有搜寻字串的功能 。more命令从前向后读取文件,因此在启动时就加载整个文件。
less 工具也是对文件或其它输出进行分页显示的工具,应该说是linux正统查看文件内容的工具,功能极其强大。less 的用法比起 more 更加的有弹性。 在 more 的时候,我们并没有办法向前面翻, 只能往后面看,但若使用了 less 时,就可以使用 [pageup] [pagedown] 等按 键的功能来往前往后翻看文件,更容易用来查看一个文件的内容!除此之外,在 less 里头可以拥有更多的搜索功能,不止可以向下搜,也可以向上搜。
3. 使用 head 和 tail 命令查看文件
只查看文件的头几行(默认为 10 行,不足 10 行则显示全部)和尾几行
6)查看文件类型
file
(四)环境变量与文件查找
一、环境变量
1. 用declare 命令创建一个变量,如:declare tmp
2. 读取变量的值,使用 echo 命令和 $ 符号,如:echo $tmp
(注:变量名只能是英文字母、数字或者下划线,且不能以数字作为开头。)
环境变量的作用域比自定义变量的要大,如 Shell 的环境变量作用于自身和它的子进程。在所有的 UNIX 和类 UNIX 系统中,每个进程都有其各自的环境变量设置,且默认情况下,当一个进程被创建时,除了创建过程中明确指定的话,它将继承其父进程的绝大部分环境设置。
通常我们会涉及到的环境变量类型有三种:
- 当前 Shell 进程私有用户自定义变量,如上面我们创建的 tmp 变量,只在当前 Shell 中有效。
- Shell 本身内建的变量。
- 从自定义变量导出的环境变量。
也有三个与上述三种环境变量相关的命令:set,env,export。这三个命令很相似,都是用于打印环境变量信息,区别在于涉及的变量范围不同。详见下表:
| 命 令 | 说 明 |
|---|---|
set |
显示当前 Shell 所有变量,包括其内建环境变量(与 Shell 外观等相关),用户自定义变量及导出的环境变量。 |
env |
显示与当前用户相关的环境变量,还可以让命令在指定环境中运行。 |
export |
显示从 Shell 中导出成环境变量的变量,也能通过它将自定义变量导出为环境变量。 |
二、添加自定义路径到“PATH”环境变量
1)添加自定义路径
PATH=$PATH:/home/shiyanlou/mybin
注意这里一定要使用绝对路径。
现在在任意目录下都能执行mybin下的可执行文件(去掉./)。
因为我给 PATH 环境变量追加了一个路径,它也只是在当前 Shell 有效,我一旦退出终端,再打开就会发现又失效了。有没有方法让添加的环境变量全局有效?或者每次启动 Shell 时自动执行上面添加自定义路径到 PATH 的命令?
2)查找shell环境的配置文件
cat /etc/shells
3)以使用的配置文件为 .zshrc 为例,将以下命令直接添加到 .zshrc
echo "PATH=$PATH:/home/shiyanlou/mybin">>.zshrc
上述命令中 >> 表示将标准输出以追加的方式重定向到一个文件中,注意前面用到的 > 是以覆盖的方式重定向到一个文件中,使用的时候一定要注意分辨。在指定文件不存在的情况下都会创建新的文件。
4)变量删除
unset mypath
5)如何让环境变量立即生效
source .zshrc
也可以用 . 代替source命令
. ./.zshrc
注意:第一个点后面有一个空格,而且后面的文件必须指定完整的绝对或相对路径名,source 则不需要。
三、搜索文件
1)whereis 简单快速
whereis who
whereis find
whereis 直接在数据库中查找,只能搜索二进制文件(-b),man 帮助文件(-m)和源代码文件(-s)。如果想要获得更全面的搜索结果可以使用 locate 命令。
2)locate 快而全
locate /usr/share/*.jpg
注:* 号前面的反斜杠转义,否则会无法找到。
3)which 小而精
which 本身是 Shell 内建的一个命令,我们通常使用 which 来确定是否安装了某个指定的程序。
4)find 精而细
命令格式为 find [path][option] [action]
sudo find /etc/ -name interfaces
(五)文件打包与解压缩
一、用zip压缩打包程序
打包:zip something.zip something(目录加-r参数)
解包:unzip something.zip
指定路径:-d参数
二、用tar压缩打包程序
打包:tar -cf something.tar something
解包:tar -xf something.tar
指定路径:-C参数
(六)文件系统操作与磁盘管理
一、基本操作
查看磁盘和目录的容量
df //查看磁盘的容量
du //查看目录的容量
-h 以一种易懂的方式展示
-d 指定查看目录的深度
du -h -d 0~ //只查看一级目录的信息
二、创建虚拟磁盘
1)给虚拟磁盘分区
1. 输入命令fdisk [磁盘设备名] 给磁盘分区
2. 输入n 新建分区,其中(p是主分区,e是扩展分区)
3. 输入p 查看刚刚新建的所有分区
4. 输入w 保存所有的磁盘分区信息
2)虚拟磁盘各分区格式化:
mkfs.ext4 [磁盘分区名] //以ext4文件系统给分区格式化
3) 挂载虚拟磁盘各分区:
mount [options] [source] [directory]
mount [-o [操作选项]] [-t 文件系统类型] [-w|--rw|--ro] [文件系统源] [挂载点]
(七)Linux下的帮助目录
1. help命令
2. man命令
3. info命令
(八)Linux任务计划crontab
一、crontab简介
crontab 命令常见于 Unix 和类 Unix 的操作系统之中(Linux 就属于类 Unix 操作系统),用于设置周期性被执行的指令。
crontab 命令从输入设备读取指令,并将其存放于 crontab 文件中,以供之后读取和执行。通常,crontab 储存的指令被守护进程激活,crond 为其守护进程,crond 常常在后台运行,每一分钟会检查一次是否有预定的作业需要执行。
通过 crontab 命令,我们可以在固定的间隔时间执行指定的系统指令或 shell 脚本。时间间隔的单位可以是分钟、小时、日、月、周的任意组合。
crontab 的格式:
# Example of job definition: # .---------------- minute (0 - 59) # | .------------- hour (0 - 23) # | | .---------- day of month (1 - 31) # | | | .------- month (1 - 12) OR jan,feb,mar,apr ... # | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat # | | | | | # * * * * * user-name command to be executed
二、crontab使用
1)启动crontab
sudo cron -f &
2)添加一个计划任务
crontab -e
3)进入配置文件中,完成任务
任务一:每分钟我们会在/home/shiyanlou 目录下创建一个以当前的年月日时分秒为名字的空白文件
*/1 * * * * touch /home/shiyanlou/$(date +\%Y\%m\%d\%H\%M\%S)
任务二:每天凌晨 3 点的时候定时备份 alternatives.log 到 /home/shiyanlou/tmp/ 目录;
命名格式为 年-月-日,比如今天是 2017 年 4 月 1 日,那么文件名为 2017-04-01
0 3 * * * sudo rm /home/shiyanlou/tmp/* 0 3 * * * sudo cp /var/log/alternatives.log /home/shiyanlou/tmp/$(date +\%Y-\%m-\%d)
4)查看任务
crontab -l
5)查看cron是否成功在后台启动
ps aux | grep cron
# or
pgrep cron
(九)命令执行顺序控制与管道
一、命令执行顺序控制
1)顺序执行命令
2)有选择的执行命令
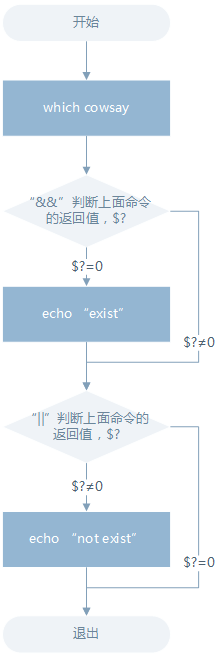
1. &&:如果前面的shell命令执行结果返回0则执行后面的,否则不执行
2. ||:上一条命令的执行结果≠0($?≠0) 时则执行它后面的命令
例:which cowsay>/dev/null && echo "exist" || echo "not exist"
流程图解释如下:
二、管道
管道是一种通信机制,通常用于进程间的通信(也可通过 socket 进行网络通信),它表现出来的形式就是将前面每一个进程的输出(stdout)直接作为下一个进程的输入(stdin)。
管道又分为匿名管道和具名管道。我们在使用一些过滤程序时经常会用到的就是匿名管道,在命令行中由 | 分隔符表示;具名管道简单的说就是有名字的管道,通常只会在源程序中用到具名管道。
1)cut命令,打印每一行的某一字段
打印 /etc/passwd 文件中以 : 为分隔符的第 1 个字段和第 6 个字段分别表示用户名和其家目录:
cut /etc/passwd -d ':' -f 1,6
打印 /etc/passwd 文件中每一行的前 N 个字符:
#前五个(包括第五个)
cut /etc/passwd -c -5
#前五个之后的(包括第五个)
cut /etc/passwd -c 5-
#第五个
cut /etc/passwd -c 5
#2 到 5 之间的(包含第五个)
cut /etc/passwd -c 2-5
2)grep命令
export | grep ".*yanlou$"
#其中$就表示一行的末尾。
# 将匹配以'z'开头以'o'结尾的所有字符串
echo 'zero
zo
zoo' | grep 'z.*o'
# 将匹配以'z'开头以'o'结尾,中间包含一个任意字符的字符串
echo 'zero
zo
zoo' | grep 'z.o'
3)sort排序命令
#默认为字典排序: cat /etc/passwd | sort #反转排序: cat /etc/passwd | sort -r #按特定字段排序: cat /etc/passwd | sort -t':' -k 3
上面的-t参数用于指定字段的分隔符,这里是以":"作为分隔符;-k 字段号用于指定对哪一个字段进行排序。
这里/etc/passwd文件的第三个字段为数字,默认情况下是以字典序排序的,如果要按照数字排序就要加上-n参数:
cat /etc/passwd | sort -t':' -k 3 -n
4)uniq去重命令
uniq 命令可以用于过滤或者输出重复行。
1. 过滤重复行
uniq 命令只能去连续重复的行,不是全文去重,所以要达到预期效果,我们先排序:
history | cut -c 8- | cut -d ' ' -f 1 | sort | uniq
2. 输出重复行
# 输出重复过的行(重复的只输出一个)及重复次数
history | cut -c 8- | cut -d ' ' -f 1 | sort | uniq -dc
# 输出所有重复的行
history | cut -c 8- | cut -d ' ' -f 1 | sort | uniq -D
(十)简单的文本处理
一、tr命令
tr [option]...SET1 [SET2]
-d: 删除和 set1 匹配的字符,注意不是全词匹配也不是按字符顺序匹配
-s: 去除 set1 指定的在输入文本中连续并重复的字符
二、col命令
col [option]
-x: 将Tab转换为空格
-h: 将空格转换为Tab(默认选项)
三、jion命令
用于将两个文件中包含相同内容的那一行合并在一起。
join [option]... file1 file2
四、paste命令
paste这个命令与join 命令类似,它是在不对比数据的情况下,简单地将多个文件合并一起,以Tab隔开。
(十一)正则表达式
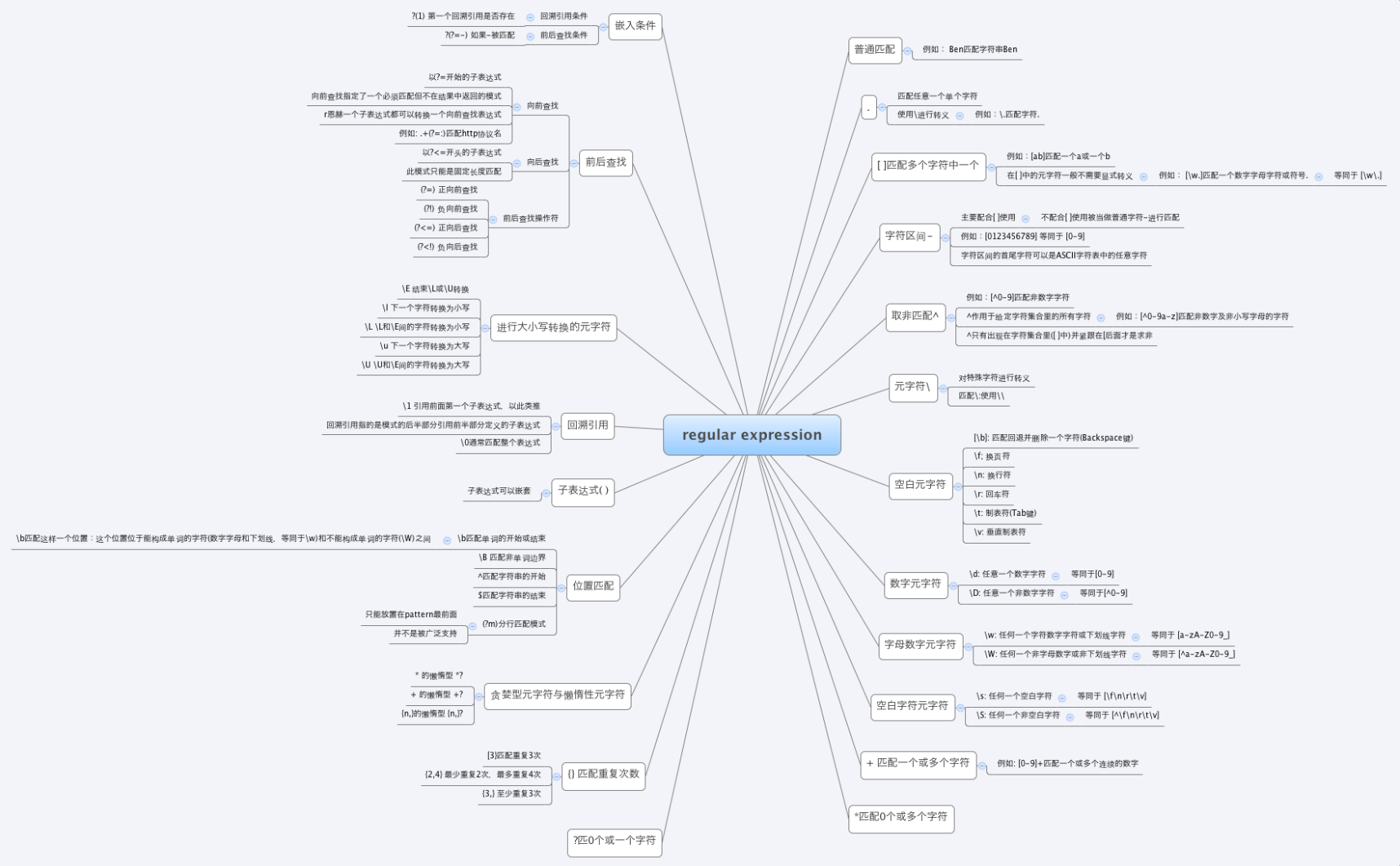
一个正则表达式通常被称为一个模式(pattern),为用来描述或者匹配一系列符合某个句法规则的字符串。
1)选择
| 竖直分隔符表示选择,例如 boy|girl 可以匹配 boy 或者 girl。
2)数量限定
+表示前面的字符必须出现至少一次(1 次或多次),例如goo+gle可以匹配gooogle,goooogle等;?表示前面的字符最多出现一次(0 次或 1 次),例如,colou?r,可以匹配color或者colour;*星号代表前面的字符可以出现0次、1次或者多次,例如,0*42可以匹配 42、042、0042、00042 等。
3)更多可见regex的思维导图
(十二)Linux进程
一、进程的特性
- 动态性:进程的实质是一次程序执行的过程,有创建、撤销等状态的变化。而程序是一个静态的实体。
- 并发性:进程可以做到在一个时间段内,有多个程序在运行中。程序只是静态的实体,所以不存在并发性。
- 独立性:进程可以独立分配资源,独立接受调度,独立地运行。
- 异步性:进程以不可预知的速度向前推进。
- 结构性:进程拥有代码段、数据段、PCB(进程控制块,进程存在的唯一标志)。也正是因为有结构性,进程才可以做到独立地运行。
并发:在一个时间段内,宏观来看有多个程序都在活动,有条不紊的执行(每一瞬间只有一个在执行,只是在一段时间有多个程序都执行过)
并行:在每一个瞬间,都有多个程序都在同时执行,这个必须有多个 CPU 才行
二、进程的分类
1)以进程的功能与服务的对象来分,分为用户进程与系统进程:
- 用户进程:通过执行用户程序、应用程序或称之为内核之外的系统程序而产生的进程,此类进程可以在用户的控制下运行或关闭。
- 系统进程:通过执行系统内核程序而产生的进程,比如可以执行内存资源分配和进程切换等相对底层的工作;而且该进程的运行不受用户的干预,即使是 root 用户也不能干预系统进程的运行。
2)以应用程序的服务类型来分,可以将进程分为交互进程、批处理进程、守护进程:
- 交互进程:由一个 shell 终端启动的进程,在执行过程中,需要与用户进行交互操作,可以运行于前台,也可以运行在后台。
- 批处理进程:该进程是一个进程集合,负责按顺序启动其他的进程。
- 守护进程:守护进程是一直运行的一种进程,在 Linux 系统启动时启动,在系统关闭时终止。它们独立于控制终端并且周期性的执行某种任务或等待处理某些发生的事件。例如 httpd 进程,一直处于运行状态,等待用户的访问。还有经常用的 cron(在 centOS 系列为 crond)进程,这个进程为 crontab 的守护进程,可以周期性的执行用户设定的某些任务。
三、进程的衍生(父进程和子进程)
fork() 是一个系统调用(system call),它的主要作用就是为当前的进程创建一个子进程,这个子进程除了父进程的返回值和 PID 以外其他的都一模一样,如进程的执行代码段,内存信息,文件描述,寄存器状态等等。
exec() 也是系统调用,作用是切换子进程中的执行程序,也就是替换其从父进程复制过来的代码段与数据段。
当一个子进程要正常的终止运行时,或者该进程结束时它的主函数 main() 会执行 exit(n); 或者 return n,这里的返回值 n 是一个信号,系统会把这个 SIGCHLD 信号传给其父进程,当然若是异常终止也往往是因为这个信号。
在将要结束时的子进程代码执行部分已经结束执行了,系统的资源也基本归还给系统了,但若是其进程的进程控制块(PCB)仍驻留在内存中,而它的 PCB 还在,代表这个进程还存在(因为 PCB 就是进程存在的唯一标志,里面有 PID 等消息),并没有消亡,这样的进程称之为僵尸进程(Zombie)。
正常情况下,父进程会收到两个返回值:exit code(SIGCHLD 信号)与 reason for termination 。之后,父进程会使用 wait(&status) 系统调用以获取子进程的退出状态,然后内核就可以从内存中释放已结束的子进程的 PCB;而如若父进程没有这么做的话,子进程的 PCB 就会一直驻留在内存中,一直留在系统中成为僵尸进程(Zombie)。
虽然僵尸进程是已经放弃了几乎所有内存空间,没有任何可执行代码,也不能被调度,在进程列表中保留一个位置,记载该进程的退出状态等信息供其父进程收集,从而释放它。但是 Linux 系统中能使用的 PID 是有限的,如果系统中存在有大量的僵尸进程,系统将会因为没有可用的 PID 从而导致不能产生新的进程。
另外如果父进程结束(非正常的结束),未能及时收回子进程,子进程仍在运行,这样的子进程称之为孤儿进程。在 Linux 系统中,孤儿进程一般会被 init 进程所“收养”,成为 init 的子进程。由 init 来做善后处理,所以它并不至于像僵尸进程那样无人问津,不管不顾,大量存在会有危害。
四、进程组和Session
每一个进程都会是一个进程组的成员,而且这个进程组是唯一存在的,他们是依靠 PGID(process group ID)来区别的,而每当一个进程被创建的时候,它便会成为其父进程所在组中的一员。
一般情况,进程组的 PGID 等同于进程组的第一个成员的 PID,并且这样的进程称为该进程组的领导者,也就是领导进程,进程一般通过使用 getpgrp() 系统调用来寻找其所在组的 PGID,领导进程可以先终结,此时进程组依然存在,并持有相同的 PGID,直到进程组中最后一个进程终结。
与进程组类似,每当一个进程被创建的时候,它便会成为其父进程所在 Session 中的一员,每一个进程组都会在一个 Session 中,并且这个 Session 是唯一存在的,
Session 主要是针对一个 tty 建立,Session 中的每个进程都称为一个工作(job)。每个会话可以连接一个终端(control terminal)。当控制终端有输入输出时,都传递给该会话的前台进程组。Session 意义在于将多个 jobs 囊括在一个终端,并取其中的一个 job 作为前台,来直接接收该终端的输入输出以及终端信号。 其他 jobs 在后台运行。
五、进程管理
1) Linux 为我们提供了一些工具来查看进程的状态信息。
- 通过
top实时的查看进程的状态,以及系统的一些信息(如 CPU、内存信息等); - 通过
ps来静态查看当前的进程信息,如ps aux; - 通过
pstree来查看当前活跃进程的树形结构。
2)杀死进程
kill -9 PID