| 这个作业属于哪个课程 | 2020-2021-1 Linux内核原理与分析 |
| 这个作业要求在哪里 | 2020-2021-1Linux内核原理与分析第七周作业 |
| 这个作业的目标 | 进程的描述和进程的创建 |
| 作业正文 | 本博客链接 |
进程的描述
1、操作系统内核实现操作系统的三大管理功能
- 进程管理(进程,最核心,用进程控制块PCB描述进程)
- 内存管理(虚拟内存)
- 文件系统(文件)
2、Linux内核描述进程
在Linux内中用一个数据结构struct task_struct来描述进程,以下是其数据结构的一部分:
struct task_struct { volatile long state; //进程状态 void *stack; // 指定进程内核堆栈 pid_t pid; //进程标识符 unsigned int rt_priority; //实时优先级 unsigned int policy; //调度策略 struct files_struct *files; //系统打开文件 ... }
3、Linux内核管理的进程状态转换
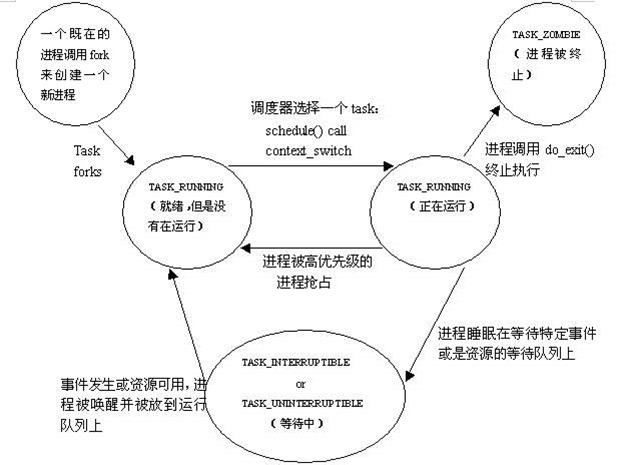
当使用fork()系统调用来创建一个新进程时,新进程的状态TASK_RUNNING(就绪态,但是没有运行)。当调度器选择这个新创建的进程运行时,新创建的进程就切换到运行态,它也是TASK_RUNNING。在Linux内核中,当进程是TASK_RUNNING状态时,它是可运行的,也就是就绪态,是否在运行取决于它有没有获得CPU的控制权,也就是说这个进程有没有在CPU中去实际执行,如果实际执行了,那进程状态就是运行态;如果被内核调度出去了,在等待队列里就是就绪态。对于一个正在运行的进程,调用用户态库函数exit()会陷入内核执行该内核函数do_exit(),也就是终止进程,那么会进入TASK_ZOMBIE状态,即进程的终止状态。TASK_ZOMBIE状态一般叫作僵尸进程,Linux内核会在适当的时候把僵尸进程给处理掉,处理掉之后进程描述符被释放了,该进程才从Linux中消失。一个正在运行的进程在等待特定的事件或资源时会进入阻塞态,阻塞态有两种:TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE,前者可以被信号和wake_up()唤醒的,后者只能被wake_up()唤醒。
4、进程的双向链表
struct list_head tasks 把所有的进程用双向链表链起来,这个数据结构十分重要。下图为进程的双向链表示意图:

进程的创建
1、0号进程的初始化
从上图的双向链表示意图中可见,init_task为双向链表的第一个节点。init_task为第一个进程(0号进程)的进程描述符结构体变量,它的初始化是通过硬编码方式固定下来的。除此之外,所有的其他进程的初始化都是通过do_fork复制父进程的方式初始化的。
2、进程之间的父子、兄弟关系
进程描述符通过struct list_head tasks双向链表来管理所有进程,但涉及将进程之间的父子、兄弟关系记录管理起来,需要用进程描述符struct task_struct数据结构表示。此数据结构记录了当前进程的父进程real_parent、parent,记录当前进程的子进程的是双向链表 struct list_head children;记录当前进程的兄弟进程的是双向链表 struct list_head sibling。
struct task_struct __rcu *real_parent;//当前进程的父进程 struct task_struct __rcu *parent; struct list_head children;//当前进程的子进程 struct list_head sibling;//当前进程的兄弟进程 #每一个进程是一些进程组的成员之一,进程组都有一个进程组长(group leader)。进程组的所有 IO 输入输出都会引导到进程组长进程那里去。
#当一个进程被创建时,父进程的进程组长也看作是子进程的进程组长。系统初始化的时候,init 进程既是它自己的进程组长,同时也是其他所有进程的进程组长。
struct task_struct *group_leader;
3、保存进程上下文中CPU相关的一些状态信息的数据结构
struct thread_struct thread ,此结构体主要保存进程上下文中CPU相关的状态。其中,最重要的是sp和ip。sp用来保存进程上下文中ESP寄存器的状态,ip用来保存进程上下文中EIP寄存器的状态。
4、进程的状态过程分析
-
fork,vfork,clone 都是通过do_fork()函数创建进程
-
fork函数执行完毕后,如果创建新进程成功,则出现两个进程,一个是子进程,一个是父进程
-
fork()函数最大的特点就是被调用一次,返回两次
利用fork()系统调用来创建新进程,把当前进程的描述符等相关进程资源复制一份,从而产生一个子进程,并根据子进程的需要对复制的进程描述符做一些修改,然后把创建好的子进程放入运行队列。在进程调度时,新创建的子进程处于就绪状态有机会被调度执行。
#include <stdio.h> #include <stdlib.h> #include <unistd.h> int main(int argc, char * argv[]) { int pid; /* fork another process */ pid = fork(); if (pid < 0) { /* error occurred */ fprintf(stderr,"Fork Failed!"); exit(-1); } else if (pid == 0) { /* child process */ printf("This is Child Process! "); } else { /* parent process */ printf("This is Parent Process! "); /* parent will wait for the child to complete*/ wait(NULL); printf("Child Complete! "); } }
上面的代码中,else if(pid == 0)和else两段代码都被执行了,原因是因为fork系统调用把当前进程复制了一个子进程,即一个进程变成两个进程,两个进程执行相同的一段代码,但由于父进程和子进程的返回值可能不同,所以输出的信息可能不同,父进程并没有打破if else的条件分支的结构,且父子进程的执行顺序并不确定。
5、进程创建过程中的重要函数或数据结构
- do_fork():主要完成调用copy_process()复制父进程信息、获得pid、调用wake_up_new_task将子进程加入调度器队列等待获得分配CPU资源运行、通过clone_flags标志做一些辅助工作。
- copy_process():主要完成调用dup_task_struct复制当前进程(父进程)描述符task_struct、信息检查、初始化、把进程状态设置为TASK_RUNNING(就绪态)、采用写时复制技术逐一复制所有其他进程资源、调用copy_thread初始化子进程内核栈、设置子进程pid等。
- dup_task_struct():复制当前进程(父进程)描述符task_struct和copy_thread初始化子进程内核栈。
- thread_info:小型的进程描述符,占据连续的两个页框,通过task指针指向进程描述符。内核栈有高地址到低地址增长,thread_info结构有低地址到高地址增长。
- copy_thread():完成内核栈关键信息的初始化。如果创建的是内核线程,则子进程开始执行的起点是ret_from_kernel_thread;如果创建的是用户态进程,则子进程开始执行的起点是ret_from_fork。
通过实验跟踪分析进程创建的过程
实验方法与上次实验类似,首先删除并克隆一份新的menu,然后将test.c覆盖掉,因为之前用过test.c可能会有影响。进入menu执行make rootfs,命令如下:
cd LinuxKernel rm -rf menu git clone https://github.com/mengning/menu.git cd menu make rootfs
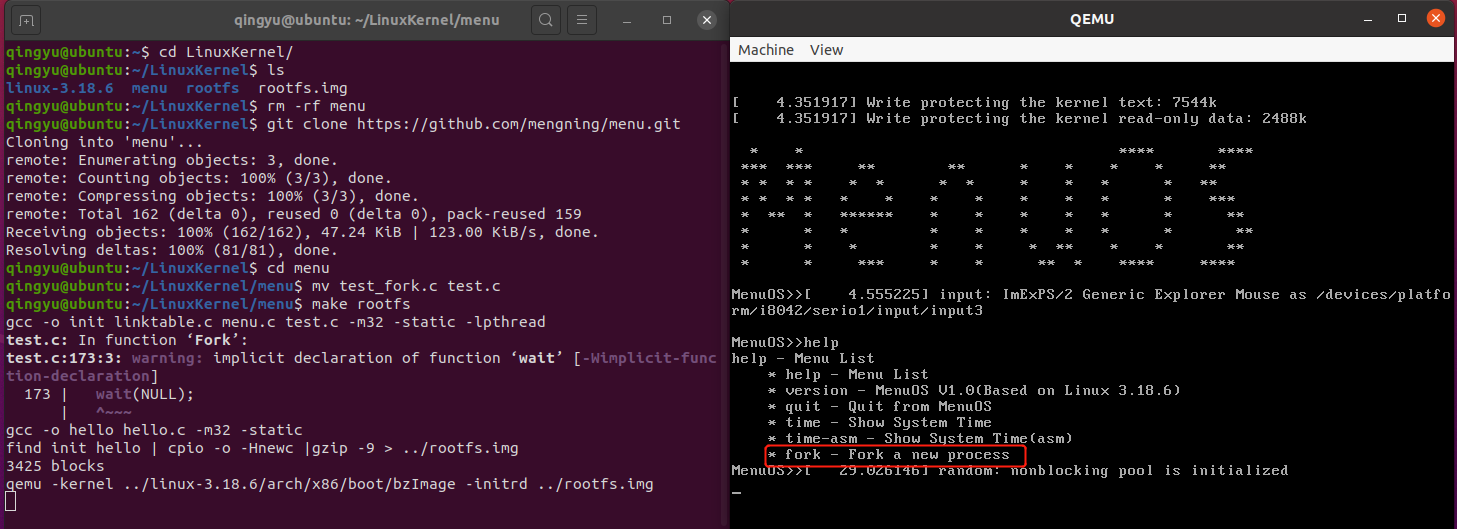
设置断点,随后用GDB调试
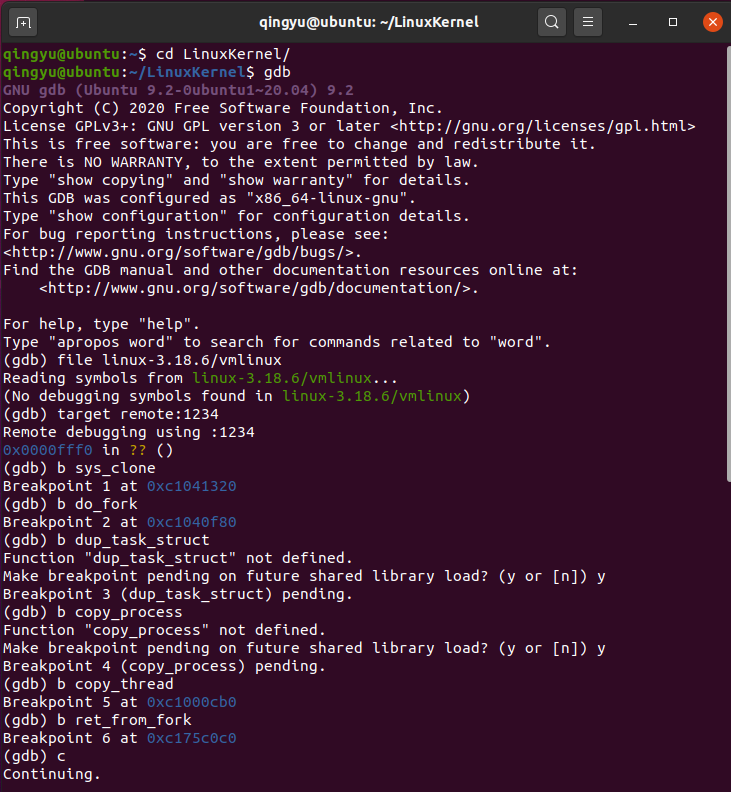
b sys_clone
b do_fork
b dup_task_struct
b copy_process
b copy_thread
b ret_from_fork
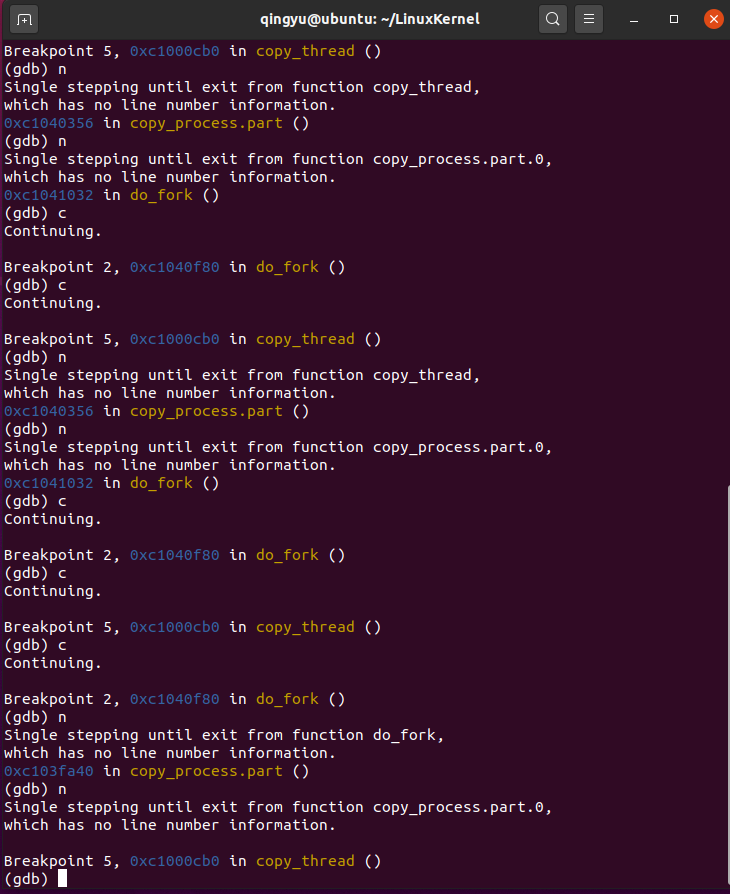
总结
创建一个进程是复制当前进程的信息,就是fork一个进程,这样就创建了一个新进程,因为父进程和子进程的绝大部分信息是完全一致的,但是有些信息是不能一样的,你如pid的值和内核堆栈。还有将新进程连接到各种链表中,要保存进程执行到哪个位置,有一个thread数据结构记录ip和sp等信息也不能一样,否则将会发生问题。父进程创建一个子进程,应该会有一个地方复制了父进程的进程描述符Task_struct结构体变量,并有很多地方来修改复制出来的进程描述符结构体变量。因为父子进程各自都有很多自己独立的个性,子进程应该有很多地方修改内核堆栈里的信息,因为内核兑换赞里的很多数据是从父进程复制来的,而fork系统调用在父子进程中分别返回到用户态,父子进程的内核堆栈中可能某些信息也不完全一样。还有thread,根据子进程复制的父进程的内核堆栈的状况,肯定要设定好EIP和ESP寄存器,即设定好子进程开始执行的位置,复制父进程的资源不需要修改进程资源,父子进程是共享内存存储空间的。