1)集群规划:
|
服务器hadoop102 |
服务器hadoop103 |
服务器hadoop104 |
|
|
HDFS |
NameNode DataNode |
DataNode |
DataNode SecondaryNameNode |
|
Yarn |
NodeManager |
Resourcemanager NodeManager |
NodeManager |
注意:尽量使用离线方式安装
1 项目经验之HDFS存储多目录
若HDFS存储空间紧张,需要对DataNode进行磁盘扩展。
1)在DataNode节点增加磁盘并进行挂载。
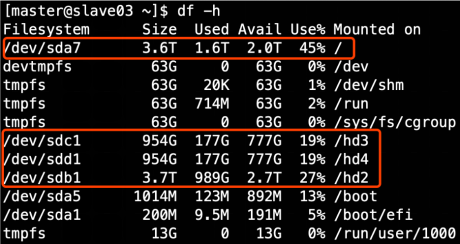
2)在hdfs-site.xml文件中配置多目录,注意新挂载磁盘的访问权限问题。
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/data1,file:///hd2/dfs/data2,file:///hd3/dfs/data3,file:///hd4/dfs/data4</value>
</property>
1.2 项目经验之支持LZO压缩配置
1)hadoop本身并不支持lzo压缩,故需要使用twitter提供的hadoop-lzo开源组件。hadoop-lzo需依赖hadoop和lzo进行编译,编译步骤如下。
Hadoop支持LZO 0. 环境准备 maven(下载安装,配置环境变量,修改sitting.xml加阿里云镜像) gcc-c++ (sudo apt-get install build-essential) zlib-devel (sudo apt-get install zlib1g sudo apt-get install zlib1g.dev) autoconf automake libtool
(sudo apt-get install openssl)
(sudo apt-get install libssl-dev)
通过yum安装即可,yum -y install gcc-c++ lzo-devel zlib-devel autoconf automake libtool 1. 下载、安装并编译LZO wget http://www.oberhumer.com/opensource/lzo/download/lzo-2.10.tar.gz tar -zxvf lzo-2.10.tar.gz cd lzo-2.10 ./configure -prefix=/usr/local/hadoop/lzo/ make sudo make install 2. 编译hadoop-lzo源码 2.1 下载hadoop-lzo的源码,下载地址:https://github.com/twitter/hadoop-lzo/archive/master.zip 2.2 解压之后,修改pom.xml <hadoop.current.version>2.7.2</hadoop.current.version> 2.3 声明两个临时环境变量 export C_INCLUDE_PATH=/usr/local/hadoop/lzo/include export LIBRARY_PATH=/usr/local/hadoop/lzo/lib 2.4 编译 进入hadoop-lzo-master,执行maven编译命令 mvn package -Dmaven.test.skip=true 2.5 进入target,hadoop-lzo-0.4.21-SNAPSHOT.jar 即编译成功的hadoop-lzo组件
2)将编译好后的hadoop-lzo-0.4.20.jar 放入hadoop-2.7.2/share/hadoop/common/
[atguigu@hadoop102 common]$ pwd /opt/module/hadoop-2.7.2/share/hadoop/common [atguigu@hadoop102 common]$ ls hadoop-lzo-0.4.20.jar
3)同步hadoop-lzo-0.4.20.jar到hadoop103、hadoop104
[atguigu@hadoop102 common]$ xsync hadoop-lzo-0.4.20.jar
4)core-site.xml增加配置支持LZO压缩
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>io.compression.codecs</name> <value> org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.SnappyCodec, com.hadoop.compression.lzo.LzoCodec, com.hadoop.compression.lzo.LzopCodec </value> </property> <property> <name>io.compression.codec.lzo.class</name> <value>com.hadoop.compression.lzo.LzoCodec</value> </property> </configuration>
5)同步core-site.xml到hadoop103、hadoop104
[atguigu@hadoop102 hadoop]$ xsync core-site.xml
6)启动及查看集群
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh [atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
7)测试
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec /input /output
8)为lzo文件创建索引
hadoop jar ./share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /output
1.3 项目经验之基准测试
1) 测试HDFS写性能
测试内容:向HDFS集群写10个128M的文件
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB 19/05/02 11:44:26 INFO fs.TestDFSIO: TestDFSIO.1.8 19/05/02 11:44:26 INFO fs.TestDFSIO: nrFiles = 10 19/05/02 11:44:26 INFO fs.TestDFSIO: nrBytes (MB) = 128.0 19/05/02 11:44:26 INFO fs.TestDFSIO: bufferSize = 1000000 19/05/02 11:44:26 INFO fs.TestDFSIO: baseDir = /benchmarks/TestDFSIO 19/05/02 11:44:28 INFO fs.TestDFSIO: creating control file: 134217728 bytes, 10 files 19/05/02 11:44:30 INFO fs.TestDFSIO: created control files for: 10 files 19/05/02 11:44:30 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8032 19/05/02 11:44:31 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8032 19/05/02 11:44:32 INFO mapred.FileInputFormat: Total input paths to process : 10 19/05/02 11:44:32 INFO mapreduce.JobSubmitter: number of splits:10 19/05/02 11:44:33 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1556766549220_0003 19/05/02 11:44:34 INFO impl.YarnClientImpl: Submitted application application_1556766549220_0003 19/05/02 11:44:34 INFO mapreduce.Job: The url to track the job: http://hadoop103:8088/proxy/application_1556766549220_0003/ 19/05/02 11:44:34 INFO mapreduce.Job: Running job: job_1556766549220_0003 19/05/02 11:44:47 INFO mapreduce.Job: Job job_1556766549220_0003 running in uber mode : false 19/05/02 11:44:47 INFO mapreduce.Job: map 0% reduce 0% 19/05/02 11:45:05 INFO mapreduce.Job: map 13% reduce 0% 19/05/02 11:45:06 INFO mapreduce.Job: map 27% reduce 0% 19/05/02 11:45:08 INFO mapreduce.Job: map 43% reduce 0% 19/05/02 11:45:09 INFO mapreduce.Job: map 60% reduce 0% 19/05/02 11:45:10 INFO mapreduce.Job: map 73% reduce 0% 19/05/02 11:45:15 INFO mapreduce.Job: map 77% reduce 0% 19/05/02 11:45:18 INFO mapreduce.Job: map 87% reduce 0% 19/05/02 11:45:19 INFO mapreduce.Job: map 100% reduce 0% 19/05/02 11:45:21 INFO mapreduce.Job: map 100% reduce 100% 19/05/02 11:45:22 INFO mapreduce.Job: Job job_1556766549220_0003 completed successfully 19/05/02 11:45:22 INFO mapreduce.Job: Counters: 51 File System Counters FILE: Number of bytes read=856 FILE: Number of bytes written=1304826 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=2350 HDFS: Number of bytes written=1342177359 HDFS: Number of read operations=43 HDFS: Number of large read operations=0 HDFS: Number of write operations=12 Job Counters Killed map tasks=1 Launched map tasks=10 Launched reduce tasks=1 Data-local map tasks=8 Rack-local map tasks=2 Total time spent by all maps in occupied slots (ms)=263635 Total time spent by all reduces in occupied slots (ms)=9698 Total time spent by all map tasks (ms)=263635 Total time spent by all reduce tasks (ms)=9698 Total vcore-milliseconds taken by all map tasks=263635 Total vcore-milliseconds taken by all reduce tasks=9698 Total megabyte-milliseconds taken by all map tasks=269962240 Total megabyte-milliseconds taken by all reduce tasks=9930752 Map-Reduce Framework Map input records=10 Map output records=50 Map output bytes=750 Map output materialized bytes=910 Input split bytes=1230 Combine input records=0 Combine output records=0 Reduce input groups=5 Reduce shuffle bytes=910 Reduce input records=50 Reduce output records=5 Spilled Records=100 Shuffled Maps =10 Failed Shuffles=0 Merged Map outputs=10 GC time elapsed (ms)=17343 CPU time spent (ms)=96930 Physical memory (bytes) snapshot=2821341184 Virtual memory (bytes) snapshot=23273218048 Total committed heap usage (bytes)=2075656192 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=1120 File Output Format Counters Bytes Written=79 19/05/02 11:45:23 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write 19/05/02 11:45:23 INFO fs.TestDFSIO: Date & time: Thu May 02 11:45:23 CST 2019 19/05/02 11:45:23 INFO fs.TestDFSIO: Number of files: 10 19/05/02 11:45:23 INFO fs.TestDFSIO: Total MBytes processed: 1280.0 19/05/02 11:45:23 INFO fs.TestDFSIO: Throughput mb/sec: 10.69751115716984 19/05/02 11:45:23 INFO fs.TestDFSIO: Average IO rate mb/sec: 14.91699504852295 19/05/02 11:45:23 INFO fs.TestDFSIO: IO rate std deviation: 11.160882132355928 19/05/02 11:45:23 INFO fs.TestDFSIO: Test exec time sec: 52.315
2)测试HDFS读性能
测试内容:读取HDFS集群10个128M的文件
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB 19/05/02 11:55:42 INFO fs.TestDFSIO: TestDFSIO.1.8 19/05/02 11:55:42 INFO fs.TestDFSIO: nrFiles = 10 19/05/02 11:55:42 INFO fs.TestDFSIO: nrBytes (MB) = 128.0 19/05/02 11:55:42 INFO fs.TestDFSIO: bufferSize = 1000000 19/05/02 11:55:42 INFO fs.TestDFSIO: baseDir = /benchmarks/TestDFSIO 19/05/02 11:55:45 INFO fs.TestDFSIO: creating control file: 134217728 bytes, 10 files 19/05/02 11:55:47 INFO fs.TestDFSIO: created control files for: 10 files 19/05/02 11:55:47 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8032 19/05/02 11:55:48 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8032 19/05/02 11:55:49 INFO mapred.FileInputFormat: Total input paths to process : 10 19/05/02 11:55:49 INFO mapreduce.JobSubmitter: number of splits:10 19/05/02 11:55:49 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1556766549220_0004 19/05/02 11:55:50 INFO impl.YarnClientImpl: Submitted application application_1556766549220_0004 19/05/02 11:55:50 INFO mapreduce.Job: The url to track the job: http://hadoop103:8088/proxy/application_1556766549220_0004/ 19/05/02 11:55:50 INFO mapreduce.Job: Running job: job_1556766549220_0004 19/05/02 11:56:04 INFO mapreduce.Job: Job job_1556766549220_0004 running in uber mode : false 19/05/02 11:56:04 INFO mapreduce.Job: map 0% reduce 0% 19/05/02 11:56:24 INFO mapreduce.Job: map 7% reduce 0% 19/05/02 11:56:27 INFO mapreduce.Job: map 23% reduce 0% 19/05/02 11:56:28 INFO mapreduce.Job: map 63% reduce 0% 19/05/02 11:56:29 INFO mapreduce.Job: map 73% reduce 0% 19/05/02 11:56:30 INFO mapreduce.Job: map 77% reduce 0% 19/05/02 11:56:31 INFO mapreduce.Job: map 87% reduce 0% 19/05/02 11:56:32 INFO mapreduce.Job: map 100% reduce 0% 19/05/02 11:56:35 INFO mapreduce.Job: map 100% reduce 100% 19/05/02 11:56:36 INFO mapreduce.Job: Job job_1556766549220_0004 completed successfully 19/05/02 11:56:36 INFO mapreduce.Job: Counters: 51 File System Counters FILE: Number of bytes read=852 FILE: Number of bytes written=1304796 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=1342179630 HDFS: Number of bytes written=78 HDFS: Number of read operations=53 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Killed map tasks=1 Launched map tasks=10 Launched reduce tasks=1 Data-local map tasks=8 Rack-local map tasks=2 Total time spent by all maps in occupied slots (ms)=233690 Total time spent by all reduces in occupied slots (ms)=7215 Total time spent by all map tasks (ms)=233690 Total time spent by all reduce tasks (ms)=7215 Total vcore-milliseconds taken by all map tasks=233690 Total vcore-milliseconds taken by all reduce tasks=7215 Total megabyte-milliseconds taken by all map tasks=239298560 Total megabyte-milliseconds taken by all reduce tasks=7388160 Map-Reduce Framework Map input records=10 Map output records=50 Map output bytes=746 Map output materialized bytes=906 Input split bytes=1230 Combine input records=0 Combine output records=0 Reduce input groups=5 Reduce shuffle bytes=906 Reduce input records=50 Reduce output records=5 Spilled Records=100 Shuffled Maps =10 Failed Shuffles=0 Merged Map outputs=10 GC time elapsed (ms)=6473 CPU time spent (ms)=57610 Physical memory (bytes) snapshot=2841436160 Virtual memory (bytes) snapshot=23226683392 Total committed heap usage (bytes)=2070413312 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=1120 File Output Format Counters Bytes Written=78 19/05/02 11:56:36 INFO fs.TestDFSIO: ----- TestDFSIO ----- : read 19/05/02 11:56:36 INFO fs.TestDFSIO: Date & time: Thu May 02 11:56:36 CST 2019 19/05/02 11:56:36 INFO fs.TestDFSIO: Number of files: 10 19/05/02 11:56:36 INFO fs.TestDFSIO: Total MBytes processed: 1280.0 19/05/02 11:56:36 INFO fs.TestDFSIO: Throughput mb/sec: 16.001000062503905 19/05/02 11:56:36 INFO fs.TestDFSIO: Average IO rate mb/sec: 17.202795028686523 19/05/02 11:56:36 INFO fs.TestDFSIO: IO rate std deviation: 4.881590515873911 19/05/02 11:56:36 INFO fs.TestDFSIO: Test exec time sec: 49.116 19/05/02 11:56:36 INFO fs.TestDFSIO:
3)删除测试生成数据
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar TestDFSIO -clean
4)使用Sort程序评测MapReduce
(1)使用RandomWriter来产生随机数,每个节点运行10个Map任务,每个Map产生大约1G大小的二进制随机数
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar randomwriter random-data
(2)执行Sort程序
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar sort random-data sorted-data
(3)验证数据是否真正排好序了
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar testmapredsort -sortInput random-data -sortOutput sorted-data
1.4 项目经验之Hadoop参数调优
1)HDFS参数调优hdfs-site.xml
(1)dfs.namenode.handler.count=20 * log2(Cluster Size),比如集群规模为8台时,此参数设置为60
The number of Namenode RPC server threads that listen to requests from clients. If dfs.namenode.servicerpc-address is not configured then Namenode RPC server threads listen to requests from all nodes. NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。对于大集群或者有大量客户端的集群来说,通常需要增大参数dfs.namenode.handler.count的默认值10。设置该值的一般原则是将其设置为集群大小的自然对数乘以20,即20logN,N为集群大小。
(2)编辑日志存储路径dfs.namenode.edits.dir设置与镜像文件存储路径dfs.namenode.name.dir尽量分开,达到最低写入延迟
2)YARN参数调优yarn-site.xml
(1)情景描述:总共7台机器,每天几亿条数据,数据源->Flume->Kafka->HDFS->Hive
面临问题:数据统计主要用HiveSQL,没有数据倾斜,小文件已经做了合并处理,开启的JVM重用,而且IO没有阻塞,内存用了不到50%。但是还是跑的非常慢,而且数据量洪峰过来时,整个集群都会宕掉。基于这种情况有没有优化方案。
(2)解决办法:
内存利用率不够。这个一般是Yarn的2个配置造成的,单个任务可以申请的最大内存大小,和Hadoop单个节点可用内存大小。调节这两个参数能提高系统内存的利用率。
(a)yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。
(b)yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB)。
3)Hadoop宕机
(1)如果MR造成系统宕机。此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认是8192MB)
(2)如果写入文件过量造成NameNode宕机。那么调高Kafka的存储大小,控制从Kafka到HDFS的写入速度。高峰期的时候用Kafka进行缓存,高峰期过去数据同步会自动跟上。
1.5 hadoop 群起脚本
在hadoop103下
atguigu@hadoop103:~/bin$ vim hd.sh
#!/bin/bash #hadoop集群的一键启动脚本 if(($#!=1)) then echo '请输入start|stop参数!' exit; fi #只允许传入start和stop参数 if [ $1 = start ] || [ $1 = stop ] then $1-dfs.sh $1-yarn.sh ssh hadoop102 "source /etc/profile;mr-jobhistory-daemon.sh $1 historyserver" else echo '请输入start|stop参数!' fi
atguigu@hadoop103:~/bin$ chmod hd.sh