2.EDA/探索性数据分析
2.1 周一到周日每天购买情况
# 导入相关包 %matplotlib inline # 绘图包 import matplotlib import matplotlib.pyplot as plt import numpy as np import pandas as pd
#定义文件名 ACTION_201602_FILE = "data/Data_Action_201602.csv" ACTION_201603_FILE = "data/Data_Action_201603.csv" ACTION_201604_FILE = "data/Data_Action_201604.csv" COMMENT_FILE = "data/Data_Comment.csv" PRODUCT_FILE = "data/Data_Product.csv" USER_FILE = "data/Data_User.csv" USER_TABLE_FILE = "data/User_table.csv" ITEM_TABLE_FILE = "data/Item_table.csv"
# 提取购买(type=4)的下单行为数据 def get_from_action_data(fname, chunk_size=50000): reader = pd.read_csv(fname, header=0, iterator=True) chunks = [] loop = True while loop: try: chunk = reader.get_chunk(chunk_size)[ ["user_id", "sku_id", "type", "time"]] chunks.append(chunk) except StopIteration: loop = False print("Iteration is stopped") df_ac = pd.concat(chunks, ignore_index=True) # type=4,为购买/下单 df_ac = df_ac[df_ac['type'] == 4] return df_ac[["user_id", "sku_id", "time"]]
df_ac = [] df_ac.append(get_from_action_data(fname=ACTION_201602_FILE)) df_ac.append(get_from_action_data(fname=ACTION_201603_FILE)) df_ac.append(get_from_action_data(fname=ACTION_201604_FILE)) df_ac = pd.concat(df_ac, ignore_index=True)
Iteration is stopped Iteration is stopped Iteration is stopped
print(df_ac.dtypes) # 将time字段转换为datetime类型
user_id int64 sku_id int64 time object dtype: object
# 将time字段转换为datetime类型 df_ac['time'] = pd.to_datetime(df_ac['time']) # 使用lambda匿名函数将时间time转换为星期(周一为1, 周日为7) df_ac['time'] = df_ac['time'].apply(lambda x: x.weekday() + 1)
df_ac.head()

# 周一到周日每天购买用户个数 df_user = df_ac.groupby('time')['user_id'].nunique() df_user = df_user.to_frame().reset_index() # DataFrame可以通过set_index方法,可以设置索引 df_user.columns = ['weekday', 'user_num']
# 周一到周日每天购买商品个数 df_item = df_ac.groupby('time')['sku_id'].nunique() df_item = df_item.to_frame().reset_index() df_item.columns = ['weekday', 'item_num']
# 周一到周日每天购买记录个数 df_ui = df_ac.groupby('time', as_index=False).size() df_ui = df_ui.to_frame().reset_index() df_ui.columns = ['weekday', 'user_item_num']
# 条形宽度 bar_width = 0.2 # 透明度 opacity = 0.4 plt.bar(df_user['weekday'], df_user['user_num'], bar_width, alpha=opacity, color='c', label='user') plt.bar(df_item['weekday']+bar_width, df_item['item_num'], bar_width, alpha=opacity, color='g', label='item') plt.bar(df_ui['weekday']+bar_width*2, df_ui['user_item_num'], bar_width, alpha=opacity, color='m', label='user_item') plt.xlabel('weekday') plt.ylabel('number') plt.title('A Week Purchase Table') plt.xticks(df_user['weekday'] + bar_width * 3 / 2., (1,2,3,4,5,6,7)) plt.tight_layout() plt.legend(prop={'size':10}) # 分析:周六,周日购买量较少,配送问题
<matplotlib.legend.Legend at 0x12fc35b90>

2.2 2016年2月中各天购买量
df_ac = get_from_action_data(fname=ACTION_201602_FILE) # 将time字段转换为datetime类型并使用lambda匿名函数将时间time转换为天 df_ac['time'] = pd.to_datetime(df_ac['time']).apply(lambda x: x.day)
Iteration is stopped
df_ac.head()

df_ac.tail()

df_user = df_ac.groupby('time')['user_id'].nunique() df_user = df_user.to_frame().reset_index() df_user.columns = ['day', 'user_num'] df_item = df_ac.groupby('time')['sku_id'].nunique() df_item = df_item.to_frame().reset_index() df_item.columns = ['day', 'item_num'] df_ui = df_ac.groupby('time', as_index=False).size() df_ui = df_ui.to_frame().reset_index() df_ui.columns = ['day', 'user_item_num']
# 条形宽度 bar_width = 0.2 # 透明度 opacity = 0.4 # 天数 day_range = range(1,len(df_user['day']) + 1, 1) # 设置图片大小 plt.figure(figsize=(14,10)) plt.bar(df_user['day'], df_user['user_num'], bar_width, alpha=opacity, color='c', label='user') plt.bar(df_item['day']+bar_width, df_item['item_num'], bar_width, alpha=opacity, color='g', label='item') plt.bar(df_ui['day']+bar_width*2, df_ui['user_item_num'], bar_width, alpha=opacity, color='m', label='user_item') plt.xlabel('day') plt.ylabel('number') plt.title('February Purchase Table') plt.xticks(df_user['day'] + bar_width * 3 / 2., day_range) # plt.ylim(0, 80) plt.tight_layout() plt.legend(prop={'size':9})
<matplotlib.legend.Legend at 0x15a590550>
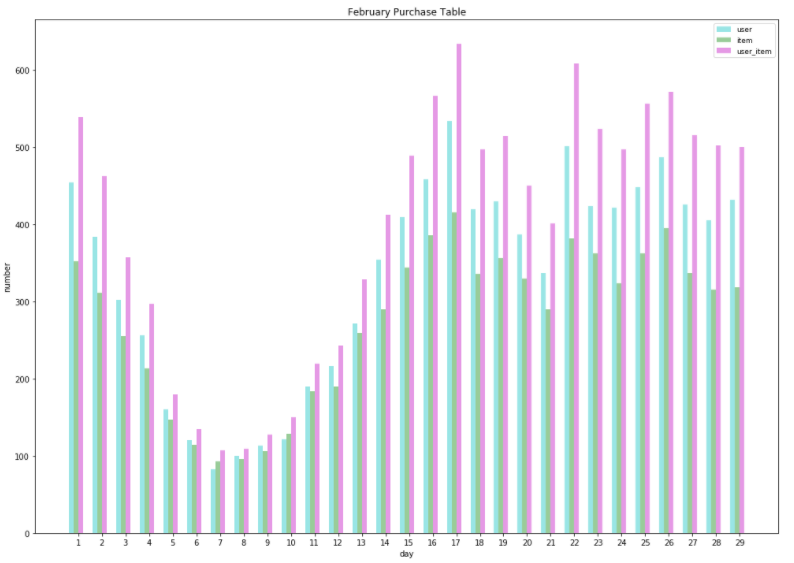
- 分析: 2月份5,6,7,8,9,10 这几天购买量非常少,原因可能是中国农历春节,快递不营业
2.3 2016年3月中各天购买量
df_ac = get_from_action_data(fname=ACTION_201603_FILE) # 将time字段转换为datetime类型并使用lambda匿名函数将时间time转换为天 df_ac['time'] = pd.to_datetime(df_ac['time']).apply(lambda x: x.day)
Iteration is stopped
df_user = df_ac.groupby('time')['user_id'].nunique() df_user = df_user.to_frame().reset_index() df_user.columns = ['day', 'user_num'] df_item = df_ac.groupby('time')['sku_id'].nunique() df_item = df_item.to_frame().reset_index() df_item.columns = ['day', 'item_num'] df_ui = df_ac.groupby('time', as_index=False).size() df_ui = df_ui.to_frame().reset_index() df_ui.columns = ['day', 'user_item_num']
# 条形宽度 bar_width = 0.2 # 透明度 opacity = 0.4 # 天数 day_range = range(1,len(df_user['day']) + 1, 1) # 设置图片大小 plt.figure(figsize=(14,10)) plt.bar(df_user['day'], df_user['user_num'], bar_width, alpha=opacity, color='c', label='user') plt.bar(df_item['day']+bar_width, df_item['item_num'], bar_width, alpha=opacity, color='g', label='item') plt.bar(df_ui['day']+bar_width*2, df_ui['user_item_num'], bar_width, alpha=opacity, color='m', label='user_item') plt.xlabel('day') plt.ylabel('number') plt.title('March Purchase Table') plt.xticks(df_user['day'] + bar_width * 3 / 2., day_range) # plt.ylim(0, 80) plt.tight_layout() plt.legend(prop={'size':9})
<matplotlib.legend.Legend at 0x175b74f50>

2.4 2016年4月中各天购买量
df_ac = get_from_action_data(fname=ACTION_201604_FILE) # 将time字段转换为datetime类型并使用lambda匿名函数将时间time转换为天 df_ac['time'] = pd.to_datetime(df_ac['time']).apply(lambda x: x.day)
Iteration is stopped
df_user = df_ac.groupby('time')['user_id'].nunique() df_user = df_user.to_frame().reset_index() df_user.columns = ['day', 'user_num'] df_item = df_ac.groupby('time')['sku_id'].nunique() df_item = df_item.to_frame().reset_index() df_item.columns = ['day', 'item_num'] df_ui = df_ac.groupby('time', as_index=False).size() df_ui = df_ui.to_frame().reset_index() df_ui.columns = ['day', 'user_item_num']
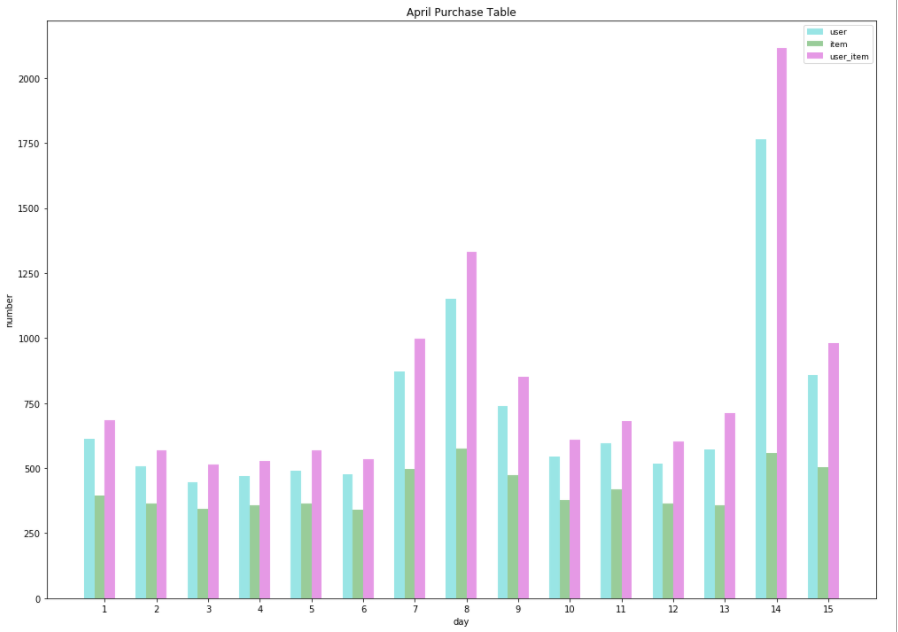
# 条形宽度 bar_width = 0.2 # 透明度 opacity = 0.4 # 天数 day_range = range(1,len(df_user['day']) + 1, 1) # 设置图片大小 plt.figure(figsize=(14,10)) plt.bar(df_user['day'], df_user['user_num'], bar_width, alpha=opacity, color='c', label='user') plt.bar(df_item['day']+bar_width, df_item['item_num'], bar_width, alpha=opacity, color='g', label='item') plt.bar(df_ui['day']+bar_width*2, df_ui['user_item_num'], bar_width, alpha=opacity, color='m', label='user_item') plt.xlabel('day') plt.ylabel('number') plt.title('April Purchase Table') plt.xticks(df_user['day'] + bar_width * 3 / 2., day_range) # plt.ylim(0, 80) plt.tight_layout() plt.legend(prop={'size':9})
<matplotlib.legend.Legend at 0x138b4db50>
2.5 商品类别销售统计
- 周一到周日各商品类别销售情况
# 从行为记录中提取商品类别数据 def get_from_action_data(fname, chunk_size=50000): reader = pd.read_csv(fname, header=0, iterator=True) chunks = [] loop = True while loop: try: chunk = reader.get_chunk(chunk_size)[ ["cate", "brand", "type", "time"]] chunks.append(chunk) except StopIteration: loop = False print("Iteration is stopped") df_ac = pd.concat(chunks, ignore_index=True) # type=4,为购买 df_ac = df_ac[df_ac['type'] == 4] return df_ac[["cate", "brand", "type", "time"]]
df_ac = [] df_ac.append(get_from_action_data(fname=ACTION_201602_FILE)) df_ac.append(get_from_action_data(fname=ACTION_201603_FILE)) df_ac.append(get_from_action_data(fname=ACTION_201604_FILE)) df_ac = pd.concat(df_ac, ignore_index=True)
Iteration is stopped Iteration is stopped Iteration is stopped
# 将time字段转换为datetime类型 df_ac['time'] = pd.to_datetime(df_ac['time']) # 使用lambda匿名函数将时间time转换为星期(周一为1, 周日为7) df_ac['time'] = df_ac['time'].apply(lambda x: x.weekday() + 1)
df_ac.head()

# 观察有几个类别商品 df_ac.groupby(df_ac['cate']).count()

# 周一到周日每天购买商品类别数量统计 df_product = df_ac['brand'].groupby([df_ac['time'],df_ac['cate']]).count() df_product=df_product.unstack() df_product.plot(kind='bar',title='Cate Purchase Table in a Week',figsize=(14,10))
<matplotlib.axes._subplots.AxesSubplot at 0x187094350>
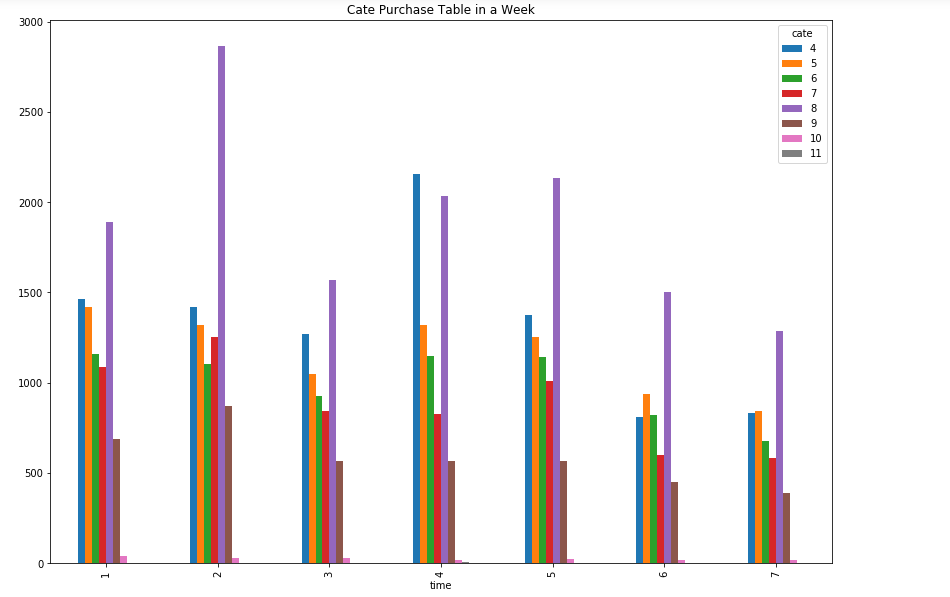
- 分析:星期二买类别8的最多,星期天最少。
2.6 每月各类商品销售情况
df_ac2 = get_from_action_data(fname=ACTION_201602_FILE) # 将time字段转换为datetime类型并使用lambda匿名函数将时间time转换为天 df_ac2['time'] = pd.to_datetime(df_ac2['time']).apply(lambda x: x.day) df_ac3 = get_from_action_data(fname=ACTION_201603_FILE) # 将time字段转换为datetime类型并使用lambda匿名函数将时间time转换为天 df_ac3['time'] = pd.to_datetime(df_ac3['time']).apply(lambda x: x.day) df_ac4 = get_from_action_data(fname=ACTION_201604_FILE) # 将time字段转换为datetime类型并使用lambda匿名函数将时间time转换为天 df_ac4['time'] = pd.to_datetime(df_ac4['time']).apply(lambda x: x.day)
Iteration is stopped Iteration is stopped Iteration is stopped
dc_cate2 = df_ac2[df_ac2['cate']==8] dc_cate2 = dc_cate2['brand'].groupby(dc_cate2['time']).count() dc_cate2 = dc_cate2.to_frame().reset_index() dc_cate2.columns = ['day', 'product_num'] dc_cate3 = df_ac3[df_ac3['cate']==8] dc_cate3 = dc_cate3['brand'].groupby(dc_cate3['time']).count() dc_cate3 = dc_cate3.to_frame().reset_index() dc_cate3.columns = ['day', 'product_num'] dc_cate4 = df_ac4[df_ac4['cate']==8] dc_cate4 = dc_cate4['brand'].groupby(dc_cate4['time']).count() dc_cate4 = dc_cate4.to_frame().reset_index() dc_cate4.columns = ['day', 'product_num']
# 条形宽度 bar_width = 0.2 # 透明度 opacity = 0.4 # 天数 day_range = range(1,len(dc_cate3['day']) + 1, 1) # 设置图片大小 plt.figure(figsize=(14,10)) plt.bar(dc_cate2['day'], dc_cate2['product_num'], bar_width, alpha=opacity, color='c', label='February') plt.bar(dc_cate3['day']+bar_width, dc_cate3['product_num'], bar_width, alpha=opacity, color='g', label='March') plt.bar(dc_cate4['day']+bar_width*2, dc_cate4['product_num'], bar_width, alpha=opacity, color='m', label='April') plt.xlabel('day') plt.ylabel('number') plt.title('Cate-8 Purchase Table') plt.xticks(dc_cate3['day'] + bar_width * 3 / 2., day_range) # plt.ylim(0, 80) plt.tight_layout() plt.legend(prop={'size':9})
<matplotlib.legend.Legend at 0x1725cf790>
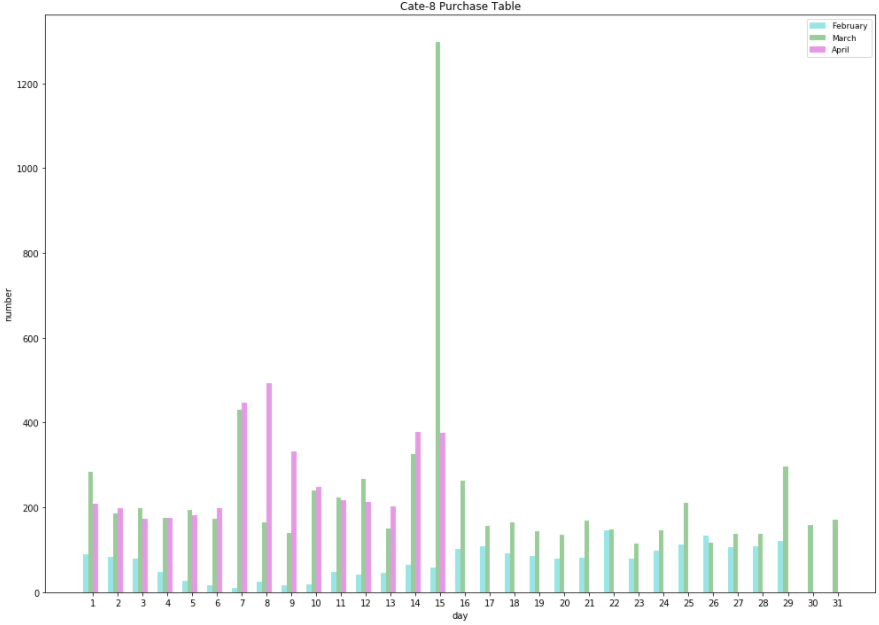
- 分析:2月份对类别8商品的购买普遍偏低,3,4月份普遍偏高,3月15日购买极其多!可以对比3月份的销售记录,发现类别8将近占了3月15日总销售的一半!同时发现,3,4月份类别8销售记录在前半个月特别相似,除了4月8号,9号和3月15号。
2.7 查看特定用户对特定商品的的轨迹
def spec_ui_action_data(fname, user_id, item_id, chunk_size=100000): reader = pd.read_csv(fname, header=0, iterator=True) chunks = [] loop = True while loop: try: chunk = reader.get_chunk(chunk_size)[ ["user_id", "sku_id", "type", "time"]] chunks.append(chunk) except StopIteration: loop = False print("Iteration is stopped") df_ac = pd.concat(chunks, ignore_index=True) df_ac = df_ac[(df_ac['user_id'] == user_id) & (df_ac['sku_id'] == item_id)] return df_ac
def explore_user_item_via_time(): user_id = 266079 item_id = 138778 df_ac = [] df_ac.append(spec_ui_action_data(ACTION_201602_FILE, user_id, item_id)) df_ac.append(spec_ui_action_data(ACTION_201603_FILE, user_id, item_id)) df_ac.append(spec_ui_action_data(ACTION_201604_FILE, user_id, item_id)) df_ac = pd.concat(df_ac, ignore_index=False) print(df_ac.sort_values(by='time'))
explore_user_item_via_time()
Iteration is stopped
Iteration is stopped
Iteration is stopped
user_id sku_id type time
0 266079 138778 1 2016-01-31 23:59:02
1 266079 138778 6 2016-01-31 23:59:03
15 266079 138778 6 2016-01-31 23:59:40