来源:https://mp.weixin.qq.com/s/gn43fUnsqTxtK1huMEZ89A
一、需求说明
简单的需求功能如下:
- 数据采集是一个 web 服务器,可以接收 http 请求传上来的事件,事件是 json 格式的;
- 收到之后,进行解码,校验字符串是否可以解码成 json 对象;
- 对消息进行抽取、清洗、转化;
- 最后发送到 kafka 中。
性能要求:
-
支持百万并发连接数;
-
对 CPU 资源和 IO 资源充分利用;

二、实现方案剖析
网页和手机端会产生一些埋点文件,通过 http 方式发送给采集服务器。涉及到网络连接,第一个想到的就是 Socket。
1、初始版本:使用 BIO 实现的客户端和服务端通信
我们很容易就可以用多线程快速实现一个 web 端服务器,模型图如下(为了节省篇幅,代码我就不写了,很简单,但不实用,百度有很多)。
简单描述一下:每次来一个请求,都创建一个线程来执行。如下图:
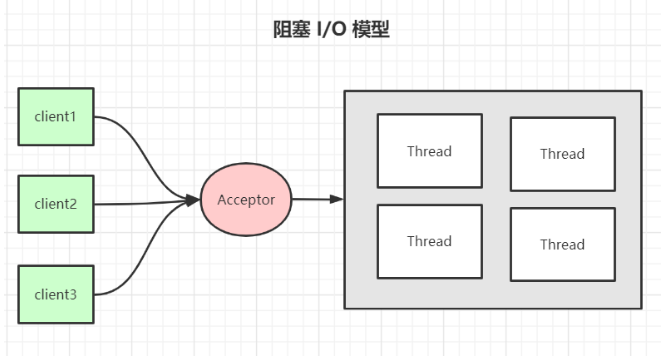
但是弊端也显而易见,随随便便就能列出三点:
1.1 创建和销毁线程动作代价昂贵
Java 中的线程模型是基于操作系统原生线程模型实现的,也就是说 Java 中的线程其实是基于内核线程实现的,线程的创建,析构与同步都需要进行系统调用,而系统调用需要在用户态与内核中来回切换,代价相对较高;
1.2 线程本身占用大量的内存
Java 中,默认一个线程,线程栈大小是 1 M。一旦线程数过千,恐怕整个 Jvm 内存都会被吃掉一半;
1.3 线程切换成本是很高
操作系统在切换线程的时候,需要保留线程的上下文,然后再执行系统调用。如果线程数过多,可能执行线程的时间都会大于线程执行的时间,使系统陷于几乎不可用的状态;
2、改造版本:异步 + NIO 实现的高性能网络通信
这是 Java 中的 NIO 模型,如下图:
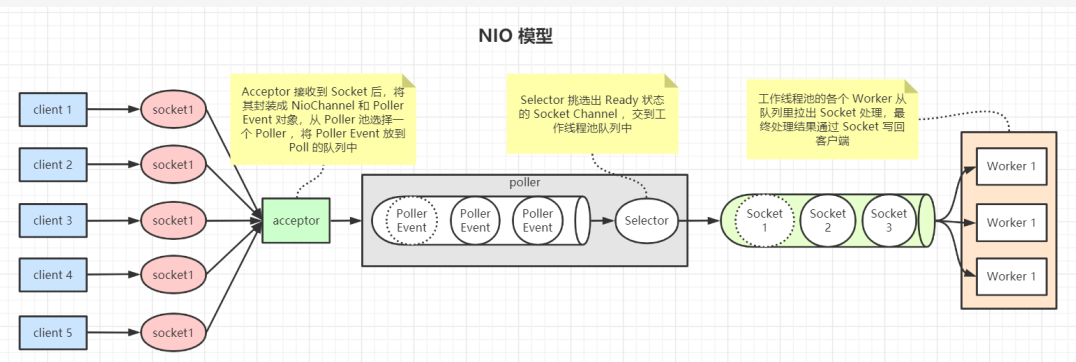
可能你一下无法接受同时出现这么多陌生的概念(Acceptor,Selector,Channel),没关系,NIO 再慢慢学,这里我们只要抓住它的核心:
- 使用了队列将请求接收器和工作线程隔开,让请求接收器和工作线程各自尽其所能的工作,更加充分的利用 IO 和 CPU 资源;
- 现在,NIO 连接器能够保持的并发连接数,不再受限于工作线程数量,无需分配大量线程,就能支持大量并发连接了。
3、进阶版本,如何充分利用 CPU 和 网络 IO 资源
在第二步,我们解决了高并发连接数的问题,但是还远远不够。
在一个采集系统中,我们需要做这三件事情,解码,清洗转化,发送。
其中,解码和清洗转化过程纯粹是 CPU 计算,占用 CPU 资源,而发送会大量占用 IO 资源。
如果让一个线程串行的执行这三件事,前面两件事,CPU 会很快做完,势必最后会等在 IO 操作上,这个线程就被操作系统挂起了,在那里空等,直到 IO 操作完成。
如何解决,只能增加工作线程数量,但是增加工作线程数量,会导致过多的线程调度和上下文切换,是另一种形式的 CPU 浪费。
如何解决,我们可以使用异步的方式。何谓异步,比如做饭过程就是异步,先把饭放电饭煲煮着,趁着这个时间去做菜,这就是“异步”。如果一直等到米饭煮熟,再去烧菜,这就是“同步”。
可能你就已经知道了,上次我们讲过 CompletableFuture,这是一个异步编程框架,可以将不同的线程编排起来。
并且可以指定线程池,让不同的事情,在不同的线程池里面完成。
看下面的代码:
// 解码线程池 Executor decoderExecutor = ExecutorHelper.createExecutor(2, "decoder"); // 转换线程池 Executor ectExecutor = ExecutorHelper.createExecutor(8, "ect"); // 发送线程池 Executor senderExecutor = ExecutorHelper.createExecutor(2, "sender"); @Override protected void channelRead0(ChannelHandlerContext ctx, HttpRequest req) throws Exception { CompletableFuture // 解码过程 .supplyAsync(() -> this.decode(ctx, req), this.decoderExecutor) // 转换过程 .thenApplyAsync(e -> this.doExtractCleanTransform(ctx, req, e), this.ectExecutor) // IO 过程 .thenApplyAsync(e -> this.send(ctx, req, e), this.senderExecutor); }
其中 channelRead0 是 Netty 框架的请求方法,每次请求都会到这个方法中。每次请求进来时,三个动作分别异步执行,但是 CompletableFuture 框架会保证每个请求三个动作执行的先后顺序。
这样,CPU 资源和 IO 资源,就可以得到充分的利用了。
三、进阶版本中存在的问题
1、问题描述
上述的异步模型可以用下面的图来表示
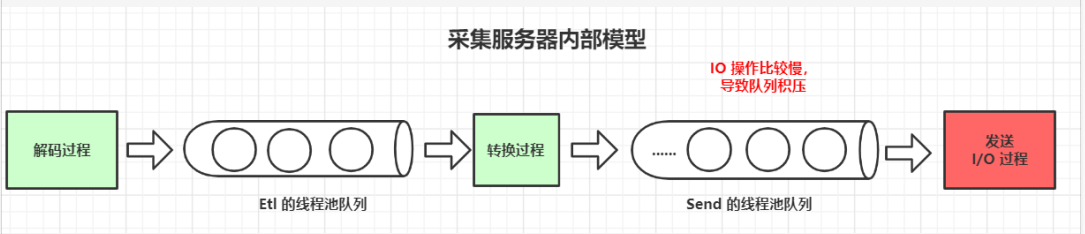
在上面的异步编程代码中,我们把不同类型的任务提交到不同的线程池中,而线程池是需要队列的,图上的队列就是线程池的队列。
其中,解码过程和转换过程,都是比较快速的过程,而发送的 I/O 过程则比较慢。
那么前面的消息会一直积压在发送过程的线程池队列中,等待执行。如果队列选择的是无界队列,那么越来越多的任务会积压,最终会用光所有的虚拟机所有的内存,导致 OOM。
2、如何控制事件的速度
我们可以直接想到,严格控制上游的发送速度,比如控制上游每秒钟只能发送 1000 条消息。这种方法虽然可行,但是非常不优雅。
如果下游遇到特殊原因,每秒只能处理 500 条,那仍然还是会 OOM,我们没法去估出一个合适的值的。
3、反向压力
有一种更加优雅的方案,叫做反向压力。
上面我们的方案出问题,主要原因还是在于队列是无界的,消息一直在积压,并且是非阻塞的。
要实现反向压力,只需要从两个方面来控制:
- 执行器的任务队列,它的容量必须是有限的;
- 当执行器的任务队列满了的时候,就阻止上游继续提交任务,直到任务队列中有新的空间为止。
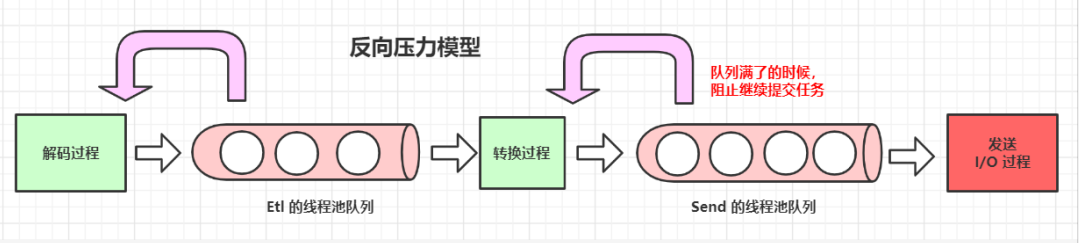
如上图,可以看到,如果发送的线程池队列满了之后,就阻止上游的转换任务继续提交任务。过了一会,转换过程的队列也会满,同样的它也会阻止解码过程提交任务。
对于我们这种数据处理场景的话,可以通过横向增加服务器来解决 TPS 低的问题;如果是流式处理场景,那么最上游应该是主动从 Kafka 拉取消息,这个时候,它就放缓自己拉取消息的速度,从而做到流量控制。
当一段时间后,发送线程池队列有空闲了,又会继续处理消息。
4、实现反压
如何来实现反压?其实很简单,当队列满了之后,会进入线程池的拒绝策略中,在拒绝策略中,我们使用 while 循环来重复提交任务,直到任务提交成功,看下面的代码:
private final List<ExecutorService> executors; private final Partitioner partitioner; private Long rejectSleepMills = 1L; public BackPressureExecutor(String name, int executorNumber, int coreSize, int maxSize, int capacity, long rejectSleepMills) { this.rejectSleepMills = rejectSleepMills; this.executors = new ArrayList<>(executorNumber); for (int i = 0; i < executorNumber; i++) { ArrayBlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(capacity); this.executors.add(new ThreadPoolExecutor( coreSize, maxSize, 0L, TimeUnit.MILLISECONDS, queue, new ThreadFactoryBuilder().setNameFormat(name + "-" + i + "-%d").build(), new ThreadPoolExecutor.AbortPolicy())); } this.partitioner = new RoundRobinPartitionSelector(executorNumber); } @Override public void execute(Runnable command) { boolean rejected; do { try { rejected = false; executors.get(partitioner.getPartition()).execute(command); } catch (RejectedExecutionException e) { rejected = true; try { TimeUnit.MILLISECONDS.sleep(rejectSleepMills); } catch (InterruptedException e1) { logger.warn("Reject sleep has been interrupted.", e1); } } } while (rejected); }
可以看到上面的代码,关键点有两个:
第一个是,在创建 ThreadPoolExecutor 对象时,采用 ArrayBlockingQueue。这是一个容量有限的阻塞队列。因此,当任务队列已经满了时,就会停止继续往队列里添加新的任务,从而避免内存无限大,造成 OOM 问题。
第二个是,将 ThreadPoolExecutor 拒绝任务时,采用的策略设置为 AbortPolicy。这就意味着,在任务队列已经满了的时候,如果再向任务队列提交任务,就会抛出 RejectedExecutionException 异常。之后,我们再通过一个 while 循环,在循环体内,捕获 RejectedExecutionException 异常,并不断尝试,重新提交任务,直到成功为止。
这样,经过上面的改造,当下游的步骤执行较慢时,它的任务队列就会占满。这个时候,如果上游继续往下游提交任务,它就会不停重试。这样,自然而然地降低了上游步骤的处理速度,从而起到了流量控制的作用。
四、这不就是一个实时流模型!
上面的那个图,是不是似曾相识?没错,它就是实时流模型啊。
并且反压,已经成为流计算领域的共识,并且已经形成了反向压力相关的标准。
Flink 中是通过 Netty 的网络模型的阻塞来把压力一层层往上游传递的,和我们实现的这个有异曲同工之妙。
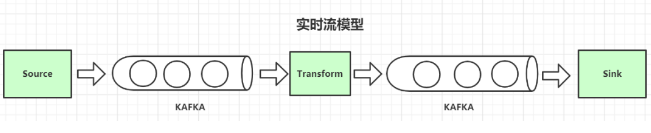
在如今的异步编程模型中,无处不存在着队列的影子,甚至在操作系统底层,也会使用队列来对性能做极致的优化,比如大名鼎鼎的 epoll。
而“队列”正是流计算系统最重要的组成结构。有“队列”的系统,它注定会是一个异步执行的过程,这也意味着“流”这种模式注定了是“异步”的。
五、总结
如今的分布式系统,都是几百甚至上千机器在一起协同工作,那不同的机器的不同进程一定会通信。
像 Spark,使用了 Netty 作为通信框架,Flink 也有在使用 Netty (还有Akka)作为通信框架。而要去了解一个分布式框架,第一步就是要了解它的通信框架,不然进程和进程的通信部分就没法看懂,整个框架核心逻辑也就无法透彻看懂。
而且在分布式系统中,异步编程的代码也是非常多,像 Flink 提交任务的过程,就使用了 CompletableFuture 异步编程框架来提交任务。