来源:https://www.cnblogs.com/www-caiyin-com/p/6759381.html
一 Adaboost实例解析
下面,给定下列训练样本,请用AdaBoost算法学习一个强分类器。

求解过程:初始化训练数据的权值分布,令每个权值W1i = 1/N = 0.1,其中,N = 10,i = 1,2, ..., 10,然后分别对于m = 1,2,3, ...等值进行迭代。
拿到这10个数据的训练样本后,根据 X 和 Y 的对应关系,要把这10个数据分为两类,一类是“1”,一类是“-1”,根据数据的特点发现:“0 1 2”这3个数据对应的类是“1”,“3 4 5”这3个数据对应的类是“-1”,“6 7 8”这3个数据对应的类是“1”,9是比较孤独的,对应类“-1”。抛开孤独的9不讲,“0 1 2”、“3 4 5”、“6 7 8”这是3类不同的数据,分别对应的类是1、-1、1,直观上推测可知,可以找到对应的数据分界点,比如2.5、5.5、8.5 将那几类数据分成两类。当然,这只是主观臆测,下面实际计算下这个过程。
迭代过程1
对于m=1,在权值分布为D1(10个数据,每个数据的权值皆初始化为0.1)的训练数据上,经过计算可得:
- 阈值v取2.5时误差率为0.3(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.3),
- 阈值v取5.5时误差率最低为0.4(x < 5.5时取1,x > 5.5时取-1,则3 4 5 6 7 8皆分错,误差率0.6大于0.5,不可取。故令x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.4),
- 阈值v取8.5时误差率为0.3(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.3)。
所以无论阈值v取2.5,还是8.5,总得分错3个样本,故可任取其中任意一个如2.5,弄成第一个基本分类器为:
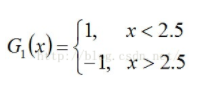
上面说阈值v取2.5时则6 7 8分错,所以误差率为0.3,更加详细的解释是:因为样本集中
- 0 1 2对应的类(Y)是1,因它们本身都小于2.5,所以被G1(x)分在了相应的类“1”中,分对了。
- 3 4 5本身对应的类(Y)是-1,因它们本身都大于2.5,所以被G1(x)分在了相应的类“-1”中,分对了。
- 但6 7 8本身对应类(Y)是1,却因它们本身大于2.5而被G1(x)分在了类"-1"中,所以这3个样本被分错了。
- 9本身对应的类(Y)是-1,因它本身大于2.5,所以被G1(x)分在了相应的类“-1”中,分对了。
从而得到G1(x)在训练数据集上的误差率(被G1(x)误分类样本“6 7 8”的权值之和)e1=P(G1(xi)≠yi) = 3*0.1 = 0.3。
然后根据误差率e1计算G1的系数:
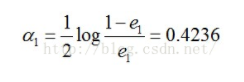
这个a1代表G1(x)在最终的分类函数中所占的权重,为0.4236。
接着更新训练数据的权值分布,用于下一轮迭代:
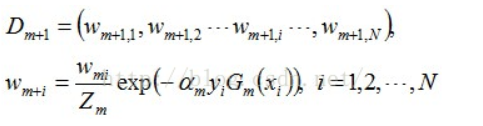
值得一提的是,由权值更新的公式可知,每个样本的新权值是变大还是变小,取决于它是被分错还是被分正确。
即如果某个样本被分错了,则yi * Gm(xi)为负,负负等正,结果使得整个式子变大(样本权值变大),否则变小。
第一轮迭代后,最后得到各个数据新的权值分布D2 = (0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)。由此可以看出,因为样本中是数据“6 7 8”被G1(x)分错了,所以它们的权值由之前的0.1增大到0.1666,反之,其它数据皆被分正确,所以它们的权值皆由之前的0.1减小到0.0715。
分类函数f1(x)= a1*G1(x) = 0.4236G1(x)。
此时,得到的第一个基本分类器sign(f1(x))在训练数据集上有3个误分类点(即6 7 8)。
从上述第一轮的整个迭代过程可以看出:被误分类样本的权值之和影响误差率,误差率影响基本分类器在最终分类器中所占的权重。
迭代过程2
对于m=2,在权值分布为D2 = (0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)的训练数据上,经过计算可得:
- 阈值v取2.5时误差率为0.1666*3(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.1666*3),
- 阈值v取5.5时误差率最低为0.0715*4(x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.0715*3 + 0.0715),
- 阈值v取8.5时误差率为0.0715*3(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.0715*3)。
所以,阈值v取8.5时误差率最低,故第二个基本分类器为:

面对的还是下述样本:
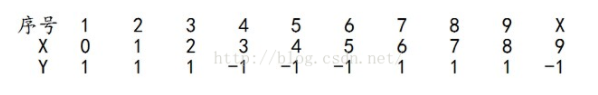
很明显,G2(x)把样本“3 4 5”分错了,根据D2可知它们的权值为0.0715, 0.0715, 0.0715,所以G2(x)在训练数据集上的误差率e2=P(G2(xi)≠yi) = 0.0715 * 3 = 0.2143。
计算G2的系数:
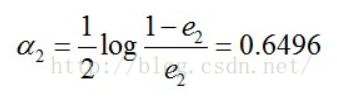
更新训练数据的权值分布:
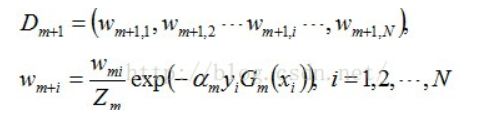
D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455)。被分错的样本“3 4 5”的权值变大,其它被分对的样本的权值变小。
f2(x)=0.4236G1(x) + 0.6496G2(x)
此时,得到的第二个基本分类器sign(f2(x))在训练数据集上有3个误分类点(即3 4 5)。
迭代过程3
对于m=3,在权值分布为D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455)的训练数据上,经过计算可得:
- 阈值v取2.5时误差率为0.1060*3(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.1060*3),
- 阈值v取5.5时误差率最低为0.0455*4(x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.0455*3 + 0.0715),
- 阈值v取8.5时误差率为0.1667*3(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.1667*3)。
所以阈值v取5.5时误差率最低,故第三个基本分类器为(下图画反了,待后续修正):
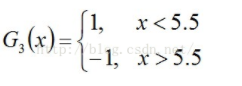
依然还是原样本:
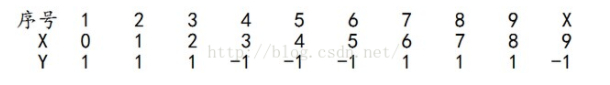
此时,被误分类的样本是:0 1 2 9,这4个样本所对应的权值皆为0.0455,所以G3(x)在训练数据集上的误差率e3= P(G3(xi)≠yi) = 0.0455*4 = 0.1820。
计算G3的系数:
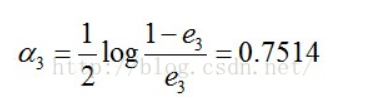
更新训练数据的权值分布:
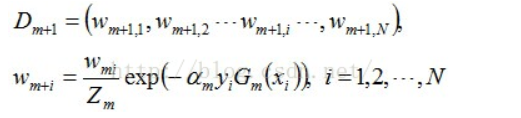
D4 = (0.125, 0.125, 0.125, 0.102, 0.102, 0.102, 0.065, 0.065, 0.065, 0.125)。被分错的样本“0 1 2 9”的权值变大,其它被分对的样本的权值变小。
f3(x)=0.4236G1(x) + 0.6496G2(x)+0.7514G3(x)
此时,得到的第三个基本分类器sign(f3(x))在训练数据集上有0个误分类点。至此,整个训练过程结束。
G(x) = sign[f3(x)] = sign[ a1 * G1(x) + a2 * G2(x) + a3 * G3(x) ],将上面计算得到的a1、a2、a3各值代入G(x)中,得到最终的分类器为:G(x) = sign[f3(x)] = sign[ 0.4236G1(x) + 0.6496G2(x)+0.7514G3(x) ]。
样本权值如何对弱分类器产生影响
每一轮训练数据并没有发生变化,一直是表8.1的数据。
只是样本的权重变化了,而根据公式8.1,每一轮分类误差率的计算会考虑权重(对于二分类来说,分类误差率=被误分样本点的权重之和),
而构造分类的切分点又是根据分类误差率最小。
切分点(例8.1中的阈值v)一次次在同一组训练数据上移动,移动到哪里,其实就是权重大的误分点起了更大影响作用的。
要不然训练模型所用的训练数据都没变,这个阈值v怎么每一轮都会变呢!不同的阈值v产生了不同的弱分类器,训练误差也以指数级下降,这就是样本权值影响弱分类器生成的一个例子。