来源:https://www.yuque.com/pinshu/alink_guide/czg4cx
1 Alink Schema String简介【Alink使用技巧】
Alink在进行表数据读取和转换时,有时需要显示声明数据表的列名和列类型信息,即Schema信息。Schema String就是将此信息使用字符串的方式描述,这样便于作为Java函数或者Python函数的参数输入。
Schema String的定义格式与SQL Create Table语句所输入的格式相同,列名与对应列类型间使用空格分隔,各列定义间使用逗号分隔。具体格式如下:
colname coltype[, colname2 coltype2[, ...]]
例如,"f0 string, f1 bigint, f2 double",即表明数据表共有3列,名称分别为f0, f1和f2;对应类型分别为字符串类型,长整型和双精度浮点型。
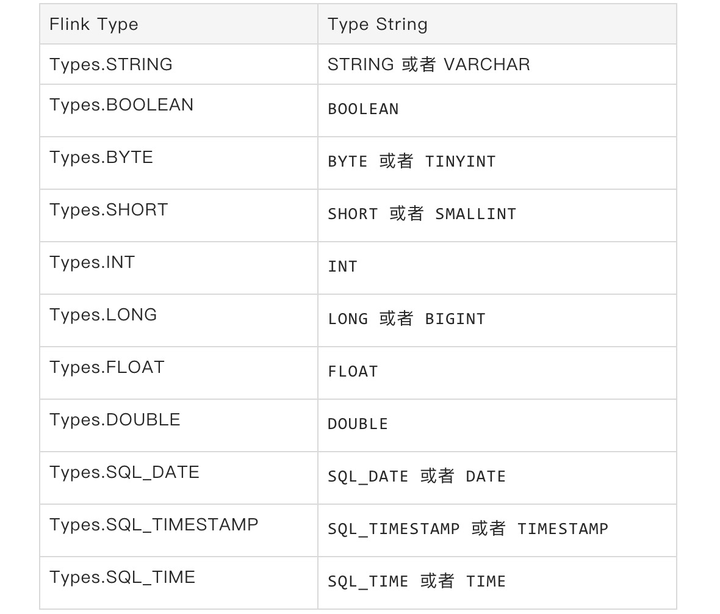
关于各种列类型的写法,可以参照下面Flink Type与Type String的对应表。注意:为了适应不同用户的习惯,同一个Flink Type可能对应着多种Type String的写法。另外,Type String对于大小写不敏感,可以写STRING,也可以写String, string等形式。
2 DataFrame和Alink批式数据的互相转化【Alink使用技巧】
Alink提供了collectToDataframe()和fromDataframe()方法,实现了DataFrame和Alink批式数据的互相转化。
Alink批式数据 -> DataFrame
Alink的批式数据源或者计算结果,如果能转成Python的DataFrame形式,则可以利用Python丰富的函数库及可视化功能,进行后续的分析和显示。
Alink中每个批式数据源或批式算子都支持collectToDataframe()方法,不需要输入参数,返回的结果就是DataFrame。注意,该方法中带有collect字样,表明其执行过程中会使用Flink的collect方法,触发Flink任务执行。
示例如下,我们使用CsvSourceBatchOp读取UCI网站的iris.data数据
source = CsvSourceBatchOp() .setFilePath("http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data") .setSchemaStr("sepal_length double, sepal_width double, petal_length double, petal_width double, category string")
然后调用变量source的collectToDataframe()方法,得到相应的DataFrame,付给变量df_iris
df_iris = source.collectToDataframe()
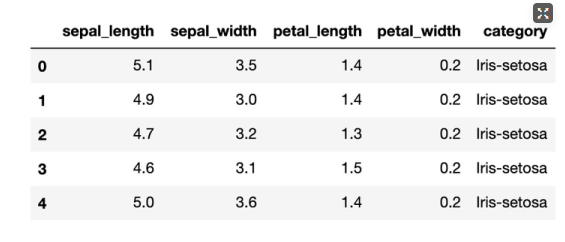
到这里,我们就已经实现了Alink数据到Python DataFrame的转化,下面我们就可以使用Python的函数,进一步处理df_iris,譬如:使用head()方法,显示前5条数据。
df_iris.head()
运行结果为:
DataFrame -> Alink批式数据
对于DataFrame形式的数据,Alink提供了fromDataframe()方法,将数据转换为Alink批式数据。具体使用示例如下:
iris = BatchOperator.fromDataframe(df_iris, "sepal_length double, sepal_width double, petal_length double, petal_width double, category string")
使用Alink批式算子BatchOperator的静态方法fromDataframe(),第一个参数为DataFrame数据,第二个参数为数据Schema的描述,由于DataFrame的数据类型与Alink有点差异,通过设置schema参数,可以严格保证转化后的数据与我们期望的一致。关于Schema String更多的介绍可以参见关于 Alink Schema String的简介。
最后,我们看一下转换后的Alink批式数据iris,取前5条数据进行打印输出,代码如下:
iris.firstN(5).print()

3 Python数组如何转化为批式数据源?【Alink使用技巧】
Python数组如何转化为批式数据源,是将DataFrame作为桥梁,分两步实现的:
- 首先,Python Pandas提供了几种途径,可以在代码中直接输入数据,并构建DataFrame
- PyAlink提供了DataFrame到SourceBatchOp的转换
示例如下,首先import pandas,然后定义一个包含String及整数类型的二维数组,并将其转化为DataFrame
import pandas as pd arr_2D =[ ['Alice',1], ['Bob',2], ['Cindy',3] ] df = pd.DataFrame(arr_2D)
然后使用BatchOperator的fromDataFrame方法,将前面定义好的DataFrame类型变量df作为第一个参数,后面的参数用来定义数据的列名与类型,使用SchemaStr格式,即列名与其类型间用空格分隔,各列定义之间使用逗号进行分隔。对应脚本如下:
BatchOperator.fromDataframe(df, 'name string, value int').print()
在上面脚本的最后部分,是对转换得到的Alink BatchOperator数据源执行print方法,显示数据的内容如下:
