来源:https://www.freesion.com/article/24301262498/
本文介绍的是一种面对高基数类别特征的普适性方法:特征哈希(FeatureHasher)。目前这只是本人的一种想法,具体效果如何还需要在实际项目中验证。
如果说独热编码后新生成的特征数量会跟随类别数量而变化,那么FeatureHasher的方法所新生成的特征数量是可以人为给定的。这样在特征冗余或维度爆炸问题上就不必担心了。个人感觉FeatureHasher有点像word2vec,都是将新特征压缩到一个给定的维度。
那么接下来通过代码介绍一下如何使用FeatureHasher。首先要从scikit-learn中导入:
import numpy as np import pandas as pd import random from sklearn.feature_extraction import FeatureHasher
创建一个数据集,含有年龄与城市两个特征,可以看到城市这个特征的属性数量有10个。
city = ['北京', '上海', '成都', '深圳', '广州', '杭州', '天津', '苏州', '武汉', '西安'] data = pd.DataFrame({'age': np.random.randint(0, 70, size=500), 'city': random.choices(city, k=500)}) data.head()

data.city.value_counts()

如果用独热编码来处理的话会产生10个新特征。那么如果类别属性有上百种,并且分布比较平均那么直接用独热编码就会造成特征冗余或维度爆炸的问题。
dummy_data = pd.get_dummies(data, prefix='city') dummy_data.head()

尝试FeatureHasher的方法,指定新生成的维度为2:
fea_hs = FeatureHasher(n_features=2, input_type='string') hasherd = fea_hs.fit_transform(data.city) print(hasherd.toarray().shape)
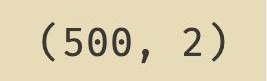
hash_data = pd.DataFrame(hasherd.toarray(), columns=[f'city_{i}' for i in range(2)]) hasher_data = pd.concat([data, hash_data], axis=1, ignore_index=False) hasher_data.head(10)
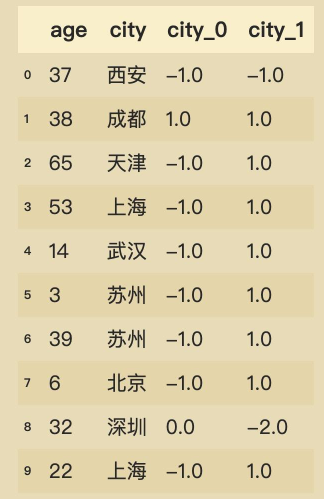
这样就将原本基数很大的特征映射到了较低的维度中。