当数据预处理完成后,我们就要开始进行特征工程了。


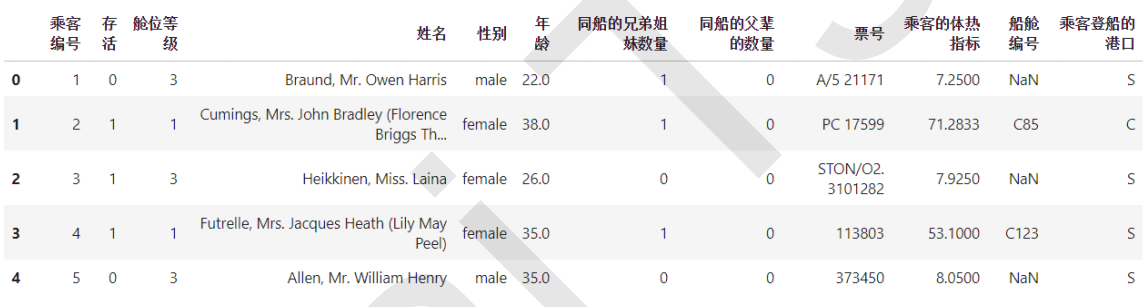

#导入数据,让我们使用digit recognizor数据来一展身手 import pandas as pd data = pd.read_csv(r"C:worklearnbettermicro-classweek 3 Preprocessingdigit recognizor.csv")
X = data.iloc[:,1:] y = data.iloc[:,0]
X.shape """ 这个数据量相对夸张,如果使用支持向量机和神经网络,很可能会直接跑不出来。使用KNN跑一次大概需要半个小时。 用这个数据举例,能更够体现特征工程的重要性。 """
1 Filter过滤法
过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法。它是根据各种统计检验中的分数以及相关性的各项指标来选择特征。

1.1 方差过滤
1.1.1 VarianceThreshold

from sklearn.feature_selection import VarianceThreshold selector = VarianceThreshold() #实例化,不填参数默认方差为0 X_var0 = selector.fit_transform(X) #获取删除不合格特征之后的新特征矩阵 #也可以直接写成 X = VairanceThreshold().fit_transform(X) X_var0.shape

import numpy as np X_fsvar = VarianceThreshold(np.median(X.var().values)).fit_transform(X)
X.var().values np.median(X.var().values) X_fsvar.shape

#若特征是伯努利随机变量,假设p=0.8,即二分类特征中某种分类占到80%以上的时候删除特征 X_bvar = VarianceThreshold(.8 * (1 - .8)).fit_transform(X) X_bvar.shape
1.1.2 方差过滤对模型的影响

1. 导入模块并准备数据
#KNN vs 随机森林在不同方差过滤效果下的对比 from sklearn.ensemble import RandomForestClassifier as RFC from sklearn.neighbors import KNeighborsClassifier as KNN from sklearn.model_selection import cross_val_score import numpy as np X = data.iloc[:,1:] y = data.iloc[:,0] X_fsvar = VarianceThreshold(np.median(X.var().values)).fit_transform(X)

2. KNN方差过滤前
#======【TIME WARNING:35mins +】======# cross_val_score(KNN(),X,y,cv=5).mean() #python中的魔法命令,可以直接使用%%timeit来计算运行这个cell中的代码所需的时间 #为了计算所需的时间,需要将这个cell中的代码运行很多次(通常是7次)后求平均值,因此运行%%timeit的时间会 远远超过cell中的代码单独运行的时间 #======【TIME WARNING:4 hours】======# %%timeit cross_val_score(KNN(),X,y,cv=5).mean()

3. KNN方差过滤后
#======【TIME WARNING:20 mins+】======# cross_val_score(KNN(),X_fsvar,y,cv=5).mean() #======【TIME WARNING:2 hours】======# %%timeit cross_val_score(KNN(),X,y,cv=5).mean() cross_val_score(RFC(n_estimators=10,random_state=0),X,y,cv=5).mean()
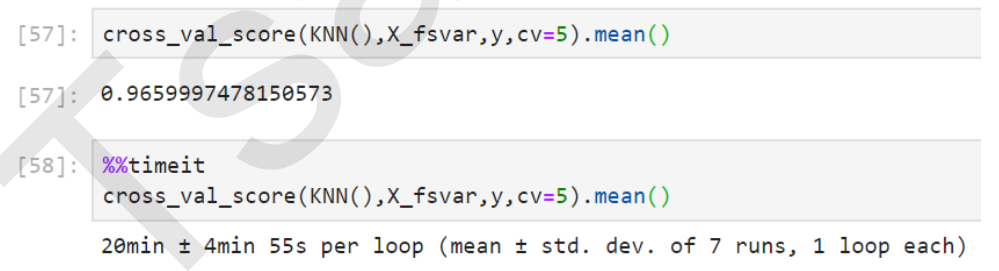

4. 随机森林方差过滤前
cross_val_score(RFC(n_estimators=10,random_state=0),X,y,cv=5).mean()
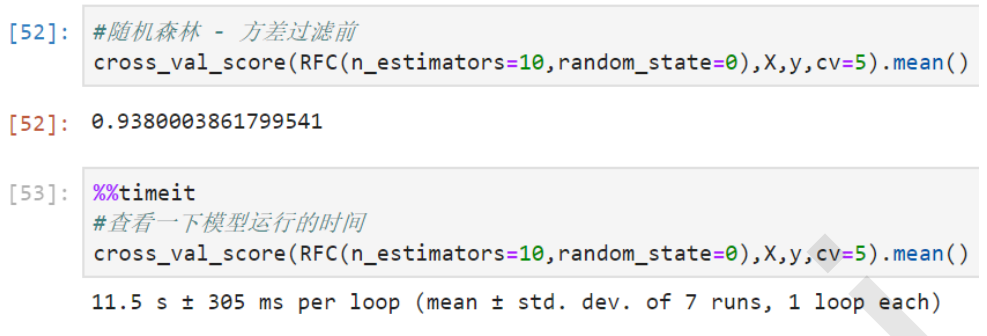
5. 随机森林方差过滤后
cross_val_score(RFC(n_estimators=10,random_state=0),X_fsvar,y,cv=5).mean()
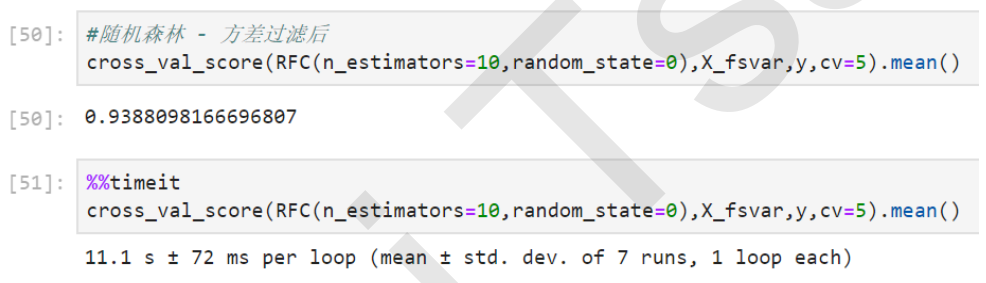


对受影响的算法来说,我们可以将方差过滤的影响总结如下:
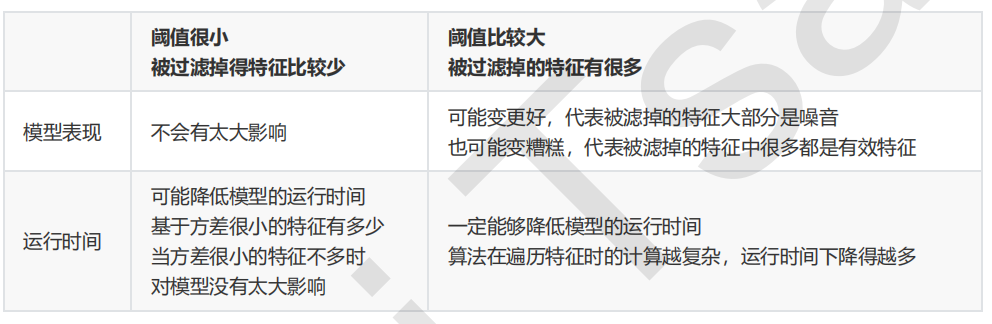

1.1.3 选取超参数threshold

1.2 相关性过滤

1.2.1 卡方过滤

from sklearn.ensemble import RandomForestClassifier as RFC from sklearn.model_selection import cross_val_score from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2 #假设在这里我一直我需要300个特征 X_fschi = SelectKBest(chi2, k=300).fit_transform(X_fsvar, y) X_fschi.shape
验证一下模型的效果如何:
cross_val_score(RFC(n_estimators=10,random_state=0),X_fschi,y,cv=5).mean()

1.2.2 选取超参数K

#======【TIME WARNING: 5 mins】======# %matplotlib inline import matplotlib.pyplot as plt score = [] for i in range(390,200,-10): X_fschi = SelectKBest(chi2, k=i).fit_transform(X_fsvar, y) once = cross_val_score(RFC(n_estimators=10,random_state=0),X_fschi,y,cv=5).mean() score.append(once) plt.plot(range(350,200,-10),score) plt.show()

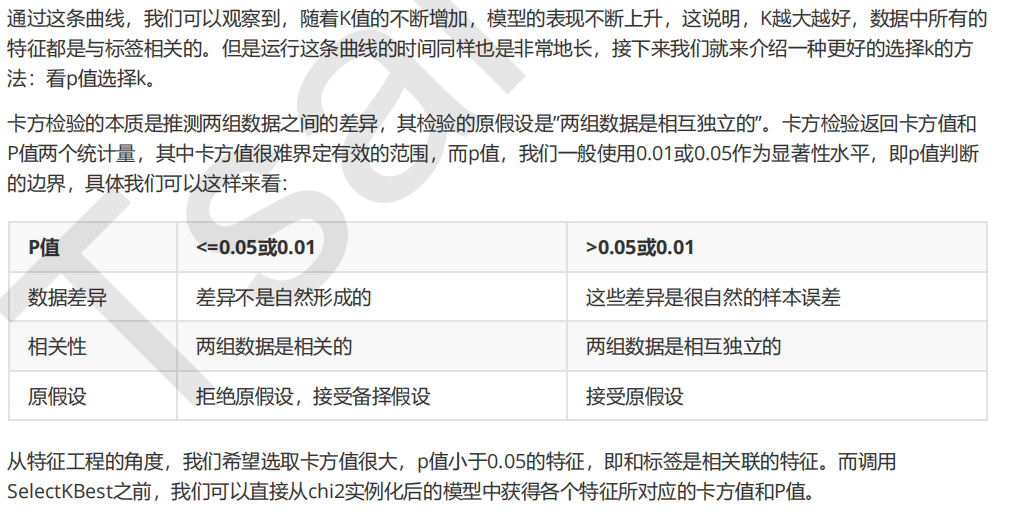
chivalue, pvalues_chi = chi2(X_fsvar,y) chivalue pvalues_chi #k取多少?我们想要消除所有p值大于设定值,比如0.05或0.01的特征: k = chivalue.shape[0] - (pvalues_chi > 0.05).sum() #X_fschi = SelectKBest(chi2, k=填写具体的k).fit_transform(X_fsvar, y) #cross_val_score(RFC(n_estimators=10,random_state=0),X_fschi,y,cv=5).mean()


from sklearn.feature_selection import f_classif F, pvalues_f = f_classif(X_fsvar,y)
F pvalues_f k = F.shape[0] - (pvalues_f > 0.05).sum() #X_fsF = SelectKBest(f_classif, k=填写具体的k).fit_transform(X_fsvar, y) #cross_val_score(RFC(n_estimators=10,random_state=0),X_fsF,y,cv=5).mean()

1.2.4 互信息法

from sklearn.feature_selection import mutual_info_classif as MIC result = MIC(X_fsvar,y) k = result.shape[0] - sum(result <= 0) #X_fsmic = SelectKBest(MIC, k=填写具体的k).fit_transform(X_fsvar, y) #cross_val_score(RFC(n_estimators=10,random_state=0),X_fsmic,y,cv=5).mean()
