数据库范式
忘掉远方是否可有出路
- 忘掉夜里月黑风高
- beyond《农民》
normalization of database,数据库的规范化,是一种数据库组织数据的技术,规范化是一种分解表的系统方法,用于消除冗余和不合理。
规范的目的:
- 消除reduntant数据
- 确保数据依赖性有意义,数据的逻辑合理性
当数据不规范的时候
观察下面的表:
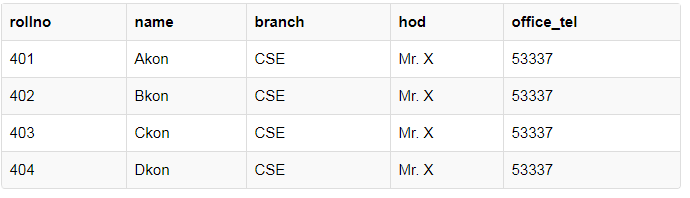
这里我们有四台计算科学数据,还有学生的数据,而对于br!anch hod(班主任)一级office_tel这些信息都是相同的,这就是数据的冗余。
插入异常
假设新的录取,除非学生选择分支,否则不能插入学生的数据,我们必须为学生的分支信息设置为null,此外,如果我们必须插入100个同一分支学生的数据,那么将为所有这100名学生重复分支信息 ,这些仅仅只是插入的异常。
更新异常
如果阿娇女士离开学院怎么办呢?或者转了一个学院不在是Dkon,这种情况下,所有学生的记录都必须要更新,如果我们错误的记录了任何记录,将会导致数据的不一致,这就是更新异常。
删除异常
在我们的学生表当中,两个不同的信息保存在了一起,也就是学生的个人信息和分支信息,当学年结束之后,如果学生的记录被删除,我们也会丢失分支的信息,这就是删除的异常。
既然问题如此之严重,那么就有必要研究一下数据库到底该如何设计了,所幸的是前辈们总结出了一些列的规范让我们有迹可循。
数据库的规范
数据库的规范化分为以下的一些形式:
- 第一范式
- 第二范式
- 第三范式
- BCNF
- 第四范式
第一范式1NF
遵循第一范式的表,应该遵守如下的规则:
- 它应该只有单个(原子的)值的属性/列
- 存储在列中的值应该属于同一个域
- 表中的所有列都应具有唯一的名称
- 数据的存储顺序无关紧要
规则1 单值属性
表的每一列都应该是单值的,这意味着它们不应包含多个值。 暂时没什么感觉,别着急,我们一会通过例子说明,先继续看看别的规则。
规则2 属性域不应更改
在列当中,存储的值必须是相同的类型,这个很好理解,比如我们这一列描述生日, 自然是用的日期时间类型描述,总不能使用true和false.同样你也不能再这列当中去存储某个人的姓名,这是疯狂的行为。
规则3 属性/列的名称唯一
这是为了避免在检索数据或对存储的数据执行任何其他操作时的混淆。 其实我们平常根本不会做出这样脑擦的行为。试想一下,如果多个列有同样的名字,DBMS不得神经错乱吗?事实上,大部分的数据库已经根本不允许这样的行为。
它会直接给出错误:
Duplicate column name 'xxxx'
规则4 顺序无关紧要
列顺序不影响信息的获取(速度上面可能有影响)
一个例子
我们将创建一个表来存储学生数据,这些数据将包含学生名单,他们的姓名以及他们选择的科目名称。 下面是表
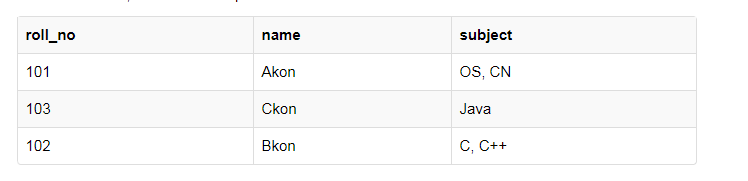
该表符合我们1NF的三个规则,所有的列名唯一,没有混合不同的类型的数据,列的顺序无关。
但是有一个问题,在subject这一列当中,存储多个科目的信息,没有保持数据的原子性,违背了rule1,单值属性。
如何解决
解决方式也很简单,分解为原子值即可,这是我们更新的表格,它将满足1NF
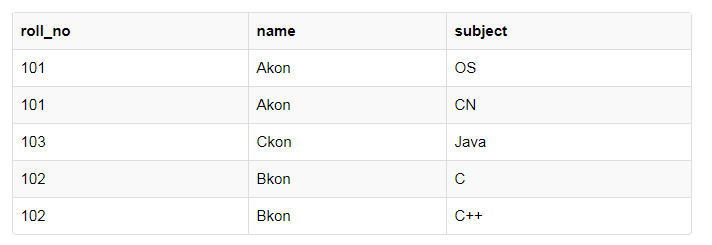
注意观察,OS,CN将是两行数据,不再混合在一起。虽然我们重复了一些数据,但是现在保证了每行记录都是原子的,使用1NF,数据冗余会增加,因为在多行当中会有许多的列具有相同的数据,但是每行作为一个整体将是唯一的。
第二范式2NF
遵守第二范式的表,应该遵守如下规则
- 它应该遵守1NF
- 它不应该具有部分依赖性
什么是依赖?
观察下面的学生表

有学生ID,学生姓名,注册号码,科目,家庭住址。
ID作为主键,并且对于每一行都是唯一的,所以我们可以依据student_id获取该表当中任何的数据行,即使对于姓名相同的学生,如果我们知道它的ID,也可以轻松获取正确记录。

有两位姓名为Akon,但上只要能确定ID,就能唯一确定信息。
所以,表的主键可以唯一标识表中的每一行记录,我可以依据它获取姓名,获取注册号,家庭住址等等,我们需要的是其它的每个列都依赖于这个ID,或者可以使用它获取,这就是依赖关系,也称之为,功能性依赖。
什么是部分依赖?
我们已经来理解了什么是依赖,部分依赖我们进一步解释,对于student这个表而言,单个student_id可以标识所有的记录,但是情况并不总是如此,现在我们多设计一个表subject

subject_id作为主键,现在我们有一个学生表,另外还有一个存储科目新的表,我们再创建一个得分表,存储学生在各个科目当中获取的分数,另外我们还会保留科目的主键,一级教师的姓名。
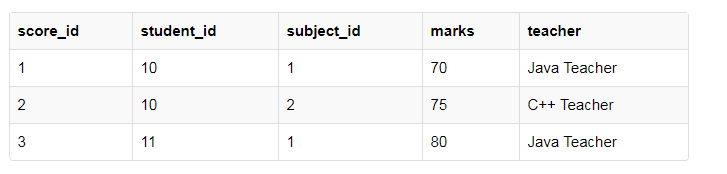
我们仅仅知道学生ID,知道分数是多少吗?不行,因为我们不知道是哪个科目,仅仅知道科目知道某个学生的信息吗?也做不到,因为一个学科有多个学生考试,因此有时候会采用联合主键来唯一标识一行数据。
部分依赖在哪?
我们观察这个score表,有一个列名为teacher的它仅仅依赖于subject,对于Java它是Java老师,对于C他是C老师,等等。
我们刚才讨论过,表的主键可以采用联合主键student_id于subject_id组合,但是老师的名字仅仅依赖于subject,和sduent_id没有关系,这就是部分依赖关系,其中的表中的某些属性只是依赖于主键的一部分,而不是整个键。
如何删除部分依赖?
世上美人很多,但我只爱一锅。
方案很多,目标一个,删除score表当中的教师名字,最简单的就是将老师的名字设计到subject表当中,score表删除老师名字这一列。
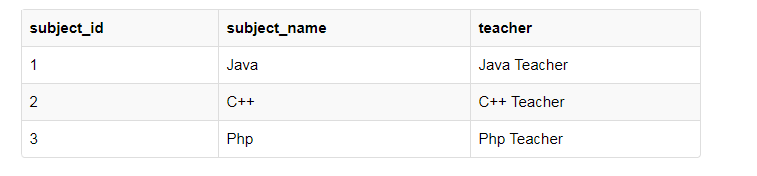
分数表改为:
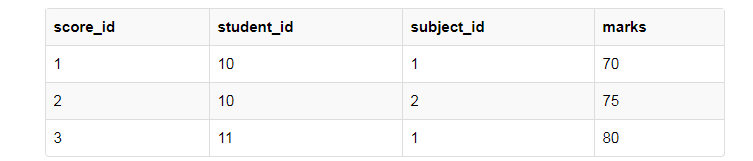
此时我们就符合2NF了,没有部分依赖。
第三范式3NF
遵守第三范式的表,应该遵守如下规则
-
遵守2NF
-
没有传递依赖性
前面我们score已经部分第二范式了,使用到了三个表,学生,科目,分数。
我们再次列举观察
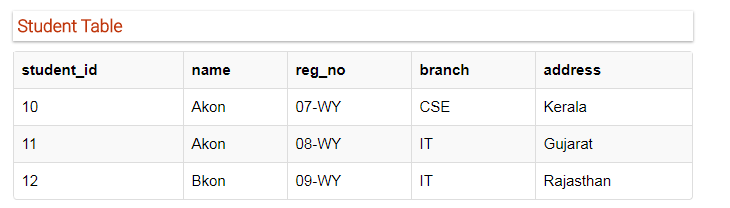
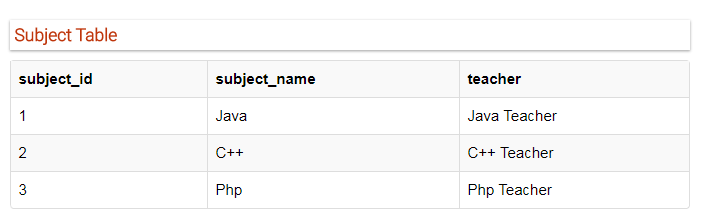
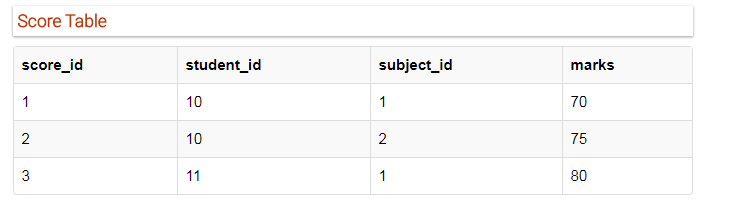
在Score表中,我们需要存储更多信息,即考试名称和总分数,所以让我们在Score表中再添加2个列。

先留个印象,我们开始探讨什么是传递依赖话题
什么是传递依赖?
使用exam_name和total_marks添加到我们的分数表中,它现在可以保存更多数据。
score表的主键是复合键,而考试名称,取决于学生和学科,比如机械专业参加打豆豆考试,但是计算机专业的学生就不会了,它们可能需要参加相亲考试(开玩笑的),所以我们可以说exam_name取决于student_id和subject_id.
第二个total_mark呢?它取决于我们的主键吗?总分它取决于某种考试类型的总分数的变化,同时exam_name只是得分表中的一列,它不是主键,也不是主键的一部分,但是total_mark却依赖于它。
这就是传递依赖,当非主属性依赖于其它非主属性的时候则称之为传递依赖。
如何删除传递依赖?
解决方案也很简单,还是姗姗来迟的删。
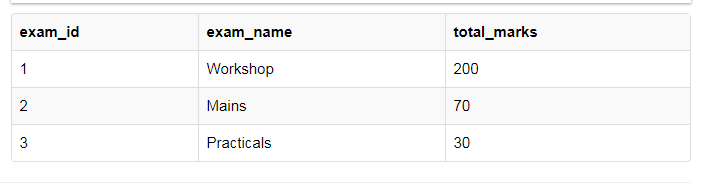
从score表中去除exam_name,total_marks,将其设计到exam表当中,并使用exam_id作为主键。新的设计:

消除传递依赖的好处
- 数据重复减少
- 实现数据的完整性
博伊斯 - 科德范式(BCNF了解)
它是第三范式的更高版本,它处理3NF没有处理的某些类型的异常,没有多个重叠候选键的3NF表被称为BCNF,对于遵守BCNF的表而言,必须遵守如下规则:
-
R必须是遵守3NF
-
对于每个功能依赖(x->y),X应该是超级键
看到第二点,有点头皮发麻,什么意思,如果B是主属性,则A不能是非主属性。
我们来看一个例子,高校选课表。
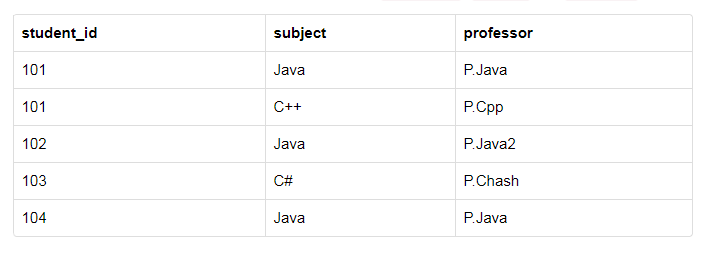
有学生ID,科目信息,教授信息。
对于这个表而言
- 一个学生可以参加多个科目,101同学,参加了Java和C++的学习。
- 对于每个科目而言,教授当然是教授所有选择他课的学生
- 多个教授可以教授同一门课,你看Java就有多个人教
so,你人为主键该是什么呢?
使用student_id和subject联合主键,我们可以找到所有的列。
在这里我们注意下(这里假定一位教授只教授一门课),一门科目可能有几位不同的教授,因此,在此之间存在依赖关系,subject,proffesor ,subject取决于教授的名字。
此表满足1st Normal表单,因为所有值都是原子值,列名称是唯一的,并且存储在特定列中的所有值都是相同的域。
该表也满足第二范式,因为它们没有部分依赖性。
并且,没有传递依赖性,因此该表也满足第3范式。
但是他不符合BCNF。
为什么不符合BCNF?
上表当中,student_id , subject作为主键,所以subject是主属性,但是还有一个依赖,professor --> subject
虽然subject是一个主属性,但是professor确是一个非主属性,因此不符合BCNF。
如何满足BCNF?
还是靠分解


第四范式4NF(了解)
遵守第四范式的表,应该遵守如下规则
- 遵守BCNF
- 没有多值依赖性
什么是多值依赖?
如果满足以下条件,则表示具有多值依赖性,
- 对于依赖性A→B,如果对于单个A值,存在B的多个值,则该表可以具有多值依赖性。
- 此外,一个表应该至少有3列,以便具有多值依赖性
- 对于关系R(A,B,C),如果A和B之间存在多值依赖关心,则B和C应该彼此独立。
如果对于任何关系(表)都满足这些条件,则称其具有多值依赖性。
看看下面的例子

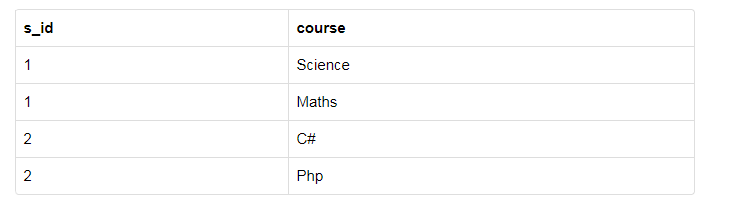
学生ID,课程名称,爱好
ID为1 的学生选择了两门课程,科学,数学,爱好有,斗蟋蟀,曲棍球。
你可能会想为什么呢?
课程与爱好是没有直接关系的,他们彼此独立,因此存在多值依赖性,这导致不必要的重复和其它异常。
如何解决
还是分解
范式反思
范式是一种研究出来的规范也是经验,但是无论如何都要考虑实际情况,比如我们为了提高查询的效率要做一些数据冗余就会违背范式,而这是没问题的,理论到实际总是有出入的。