背景
在google发布GFS和Map Reduce的两篇论文之后,围绕着大数据各种实现如雨后春笋般的产生,而其中的佼佼者非hadoop家族莫属。有了类似hadoop的开源实现后,使得数据的采集变得更加廉价,机器学习的价值更加提高。因此熟悉hadoop,了解hadoop的运作机制,对于开发人员提出了更高的要求,能更好地理解并优化自己的MapReduce任务,同时对分布式的存储和计算系统也能有更好的了解。本文着重讲述如何在windows环境下,通过cygwin来搭建hadoop伪集群。
运行环境
- windows7
- cygwin x84 64位
cygwin
安装
- 下载自己系统的cygwin安装软件
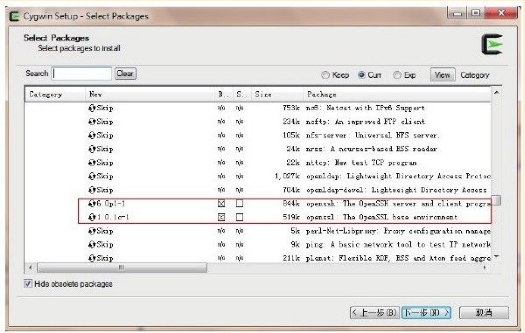
- 安装过程中选择安装openSSH和openSSL,主要让系统启动sshd服务,来进行节点间的bash脚本执行来启动相关的售后进程
- 点击下一步,直到cygwin安装完成
配置
安装完cygwin后,一定要进行ssh的配置才能算大工告成,配置的过程还是很容易碰到一些问题的。
安装启动ssh服务
cygwin命令行输入ssh-host-config
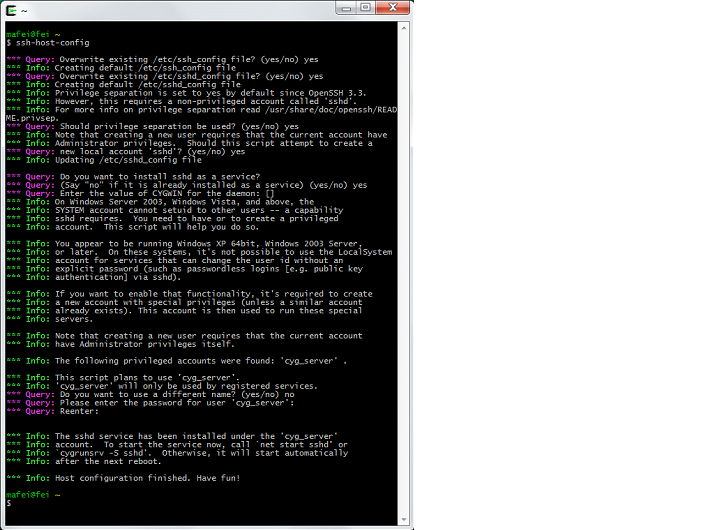
当屏幕显示关于“privilege seperation”,输入yes后回车;
当屏幕显示关于“create local user sshd”,输入yes后回车;
*** Query: Should privilege separation be used? (yes/no) yes #输入yes
*** Info: Updating /etc/sshd_config file
*** Warning: The following functions require administrator privileges!
*** Query: Do you want to install sshd as a service?
*** Query: (Say "no" if it is already installed as a service) (yes/no) yes #输入yes
*** Info: Note that the CYGWIN variable must contain at least "ntsec"
*** Info: for sshd to be able to change user context without password.
*** Query: Enter the value of CYGWIN for the daemon: []
*** Info: On Windows Server 2003, Windows Vista, and above, the
......
*** Info: This script plans to use 'cyg_server'.
*** Info: 'cyg_server' will only be used by registered services.
*** Query: Do you want to use a different name? (yes/no) no
*** Query: Create new privileged user account 'cyg_server'? (yes/no) yes
*** Info: Please enter a password for new user cyg_server. Please be sure
*** Info: that this password matches the password rules given on your system.
*** Info: Entering no password will exit the configuration.
*** Query: Please enter the password:
*** Query: Reenter:
注意事项
- cygwin帮忙创建的两个用户sshd和cyg_server,其中sshd服务在cyg_server用户下运行,cyg_server有相应的权限(在/usr/share/doc/Cygwin/openssh.README 中也有说明)。其中需要注意的是两个用户都必须创建。
- 如果初始配置错误,大部分网上都建议全部删除再重新安装,但cygwin一旦安装很难完全卸载,只需要把ssh服务停止再重新执行这个命令,再把之前的覆盖掉就可以。
步骤:
- 命令行输入sc delete sshd
- 系统重启,就再配置就ok了
安装完后命令行输入
net start sshd就可以启动ssh服务
net stop sshd关闭ssh服务
免密码登陆
- cygwin命令行输入
cygwin 输入ssh-keygen -t rsa,执行命令后,将会在~/.ssh/目录下生成公钥文件id_rsa.pub和私钥文件id_rsa。
然后将id_rsa.pub复制到同目录下的authorized_keys文件中,命令cat id_rsa.pub > authorized_keys。执行后,在sshd服务启动的前提下,可以ssh登陆 localhost。
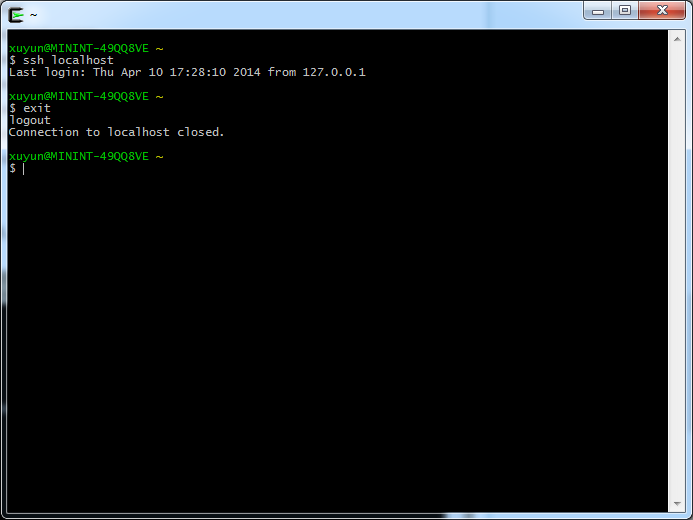
一定要确保sshd服务能够正常启动,同时能够ssh登录本机,否则会影响节点类的守候进行顺利启动。
hadoop安装
hadoop版本选择
hadoop版本变迁图如下图所示
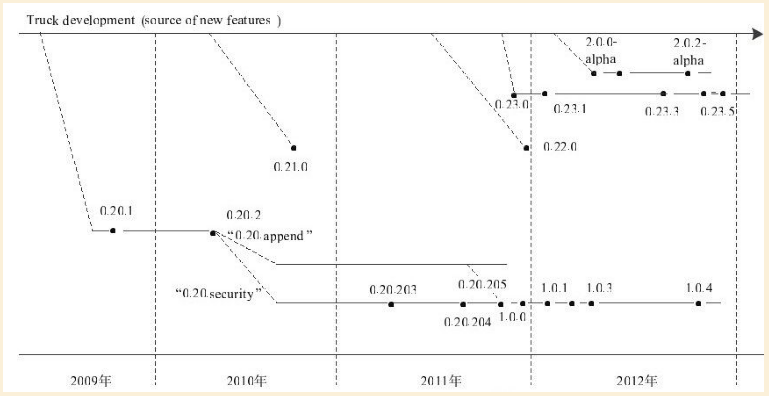
hadoop各个版本的发布的特性和稳定性总结如下图所示。
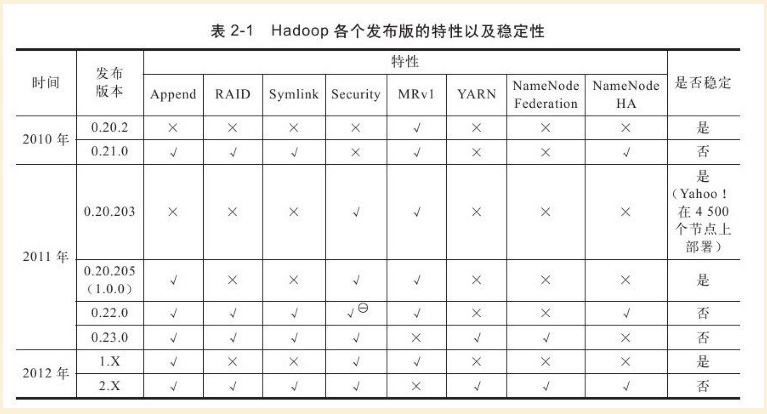
本文部署选择hadoop1.0.0,选择这个版本主要是因为这是一个稳定的版本,对于Apache来说,也希望发布这个版本来成为业界的规范。搜索来下载hadoop-1.0.0.tar.gz,解压后,copy到cygwin的home/${user}/下面 ,文件结构如下图所示
相关配置文件配置
-
mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration> -
core-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration> -
hdfs-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.premissions</name> <value>false</value> </property> </configuration> -
hadoop-env.xml
追加
export JAVA_HOME="/usr/local/jdk1.6.0_45"
格式化
在能够执行hadoop命令前,需要把hadoop/bin添加到windows的环境变量PATH中去。
然后,cygwin输入
hadoop namenode -foramt
成功后出现如下图像
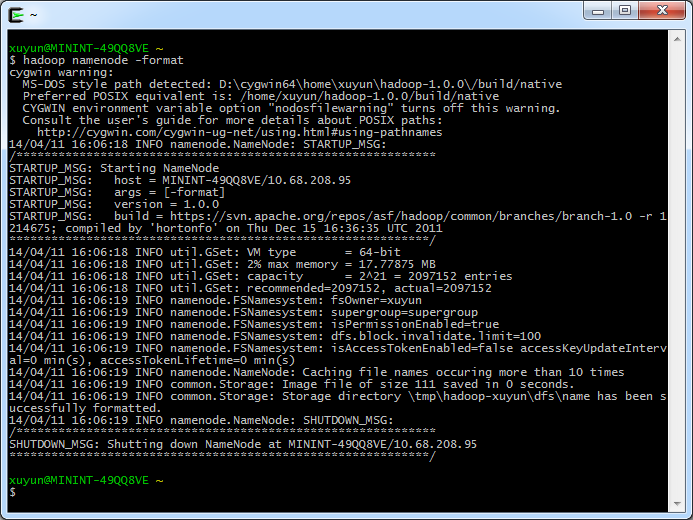
如果多次执行这个命令进行格式化,那么在后续的启动datanode节点的过程中,会出现节点启动失败的错误
ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: java.io.IOException: Incompatible namespaceIDs in /home/admin/joe.wangh/hadoop/data/dfs.data.dir: namenode namespaceID = 898136669; datanode namespaceID = 2127444065
at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:233)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:148)
at org.apache.hadoop.hdfs.server.datanode.DataNode.startDataNode(DataNode.java:288)
at org.apache.hadoop.hdfs.server.datanode.DataNode.<init>(DataNode.java:206)
at org.apache.hadoop.hdfs.server.datanode.DataNode.makeInstance(DataNode.java:1239)
at org.apache.hadoop.hdfs.server.datanode.DataNode.instantiateDataNode(DataNode.java:1194)
at org.apache.hadoop.hdfs.server.datanode.DataNode.createDataNode(DataNode.java:1202)
at org.apache.hadoop.hdfs.server.datanode.DataNode.main(DataNode.java:1324)
......
有两种解决方案

原因是:每次namenode format会重新创建一个namenodeId,而tmp/dfs/data下包含了上次format下的id,name
node format清空了namenode下的数据,但是没有清空datanode下的数据,导致启动时失败。第一种方案是format前直接把目录删除,这个比较暴力,比较适合没有数据的系统,如果已经存储了相关数据,则只能进行修改version中的nameSpaceId来进行匹配,再启动datanode节点
start-all.sh
全部启动节点实际上是调用几个子脚本,启动各个守候进程。
-
start-all.sh
# start dfs daemons "$bin"/start-dfs.sh --config $HADOOP_CONF_DIR # start mapred daemons "$bin"/start-mapred.sh --config $HADOOP_CONF_DIR -
start-dfs.sh
# start dfs daemons # start namenode after datanodes, to minimize time namenode is up w/o data # note: datanodes will log connection errors until namenode starts "$bin"/hadoop-daemon.sh --config $HADOOP_CONF_DIR start namenode $nameStartOpt "$bin"/hadoop-daemons.sh --config $HADOOP_CONF_DIR start datanode $dataStartOpt "$bin"/hadoop-daemons.sh --config $HADOOP_CONF_DIR --hosts masters start secondarynamenode -
start-mapred.sh
# start mapred daemons
# start jobtracker first to minimize connection errors at startup
"$bin"/hadoop-daemon.sh --config $HADOOP_CONF_DIR start jobtracker
"$bin"/hadoop-daemons.sh --config $HADOOP_CONF_DIR start tasktracker
在cygwin中输入start-all.sh,前提是$HADOOP_HOME/bin放到了windows的PATH环境变量中。命令执行完毕后,通过url查看
如果在linux环境下,我们碰到问题的几率将会非常小,但是在linux环境下,还是非常容易碰到一些错误的。下面给出一些在启动过程中可能报的错误。
Address already in use: bind
2014-04-12 10:15:07,371 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: java.net.BindException: Problem binding to /0.0.0.0:50020 : Address already in use: bind
at org.apache.hadoop.ipc.Server.bind(Server.java:227)
at org.apache.hadoop.ipc.Server$Listener.<init>(Server.java:301)
at org.apache.hadoop.ipc.Server.<init>(Server.java:1483)
at org.apache.hadoop.ipc.RPC$Server.<init>(RPC.java:545)
at org.apache.hadoop.ipc.RPC.getServer(RPC.java:506)
at org.apache.hadoop.hdfs.server.datanode.DataNode.startDataNode(DataNode.java:491)
at org.apache.hadoop.hdfs.server.datanode.DataNode.<init>(DataNode.java:290)
at org.apache.hadoop.hdfs.server.datanode.DataNode.makeInstance(DataNode.java:1553)
at org.apache.hadoop.hdfs.server.datanode.DataNode.instantiateDataNode(DataNode.java:1492)
at org.apache.hadoop.hdfs.server.datanode.DataNode.createDataNode(DataNode.java:1510)
at org.apache.hadoop.hdfs.server.datanode.DataNode.secureMain(DataNode.java:1636)
at org.apache.hadoop.hdfs.server.datanode.DataNode.main(DataNode.java:1653)
Caused by: java.net.BindException: Address already in use: bind
at sun.nio.ch.Net.bind(Native Method)
at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:124)
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:59)
at org.apache.hadoop.ipc.Server.bind(Server.java:225)
... 11 more
解决方案,修改hdfs-site.xml配置项dfs.datanode.ipc.address默认值
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:50021</value>
</property>
HADOOP-7682 BUG
2014-04-11 16:30:56,201 WARN org.apache.hadoop.util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2014-04-11 16:30:56,202 ERROR org.apache.hadoop.mapred.TaskTracker: Can not start task tracker because java.io.IOException: Failed to set permissions of path: mphadoop-cyg_servermapredlocal askTracker to 0755
at org.apache.hadoop.fs.FileUtil.checkReturnValue(FileUtil.java:682)
at org.apache.hadoop.fs.FileUtil.setPermission(FileUtil.java:663)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:509)
at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:344)
at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:189)
at org.apache.hadoop.mapred.TaskTracker.initialize(TaskTracker.java:714)
at org.apache.hadoop.mapred.TaskTracker.<init>(TaskTracker.java:1436)
at org.apache.hadoop.mapred.TaskTracker.main(TaskTracker.java:3694)
文件权限问题是hadoop cygwin环境下100%会碰到的一个问题,bug地址和解决方案的地址是:
https://issues.apache.org/jira/browse/HADOOP-7682,https://github.com/congainc/patch-hadoop_7682-1.0.x-win。把hadoop的path包放到$HADOOP_HOME/lib下启动即可。切记该解决方案只能用于开发环境,因为如果用于windows的生产环境可能会有一些未经测试的负面效果。
Word count example运行
前面已经在cygwin的环境下启动了单机的伪分布式环境。下面就需要运行一个例子来保证hadoop能够正常运转。输入hadoop命令前,可能还是需要一些准备工作,比如,hadoop源代码工程的导入,eclipse插件。这些都能为我们的hadoop探索之旅带来一些便利。
源代码工程的导入
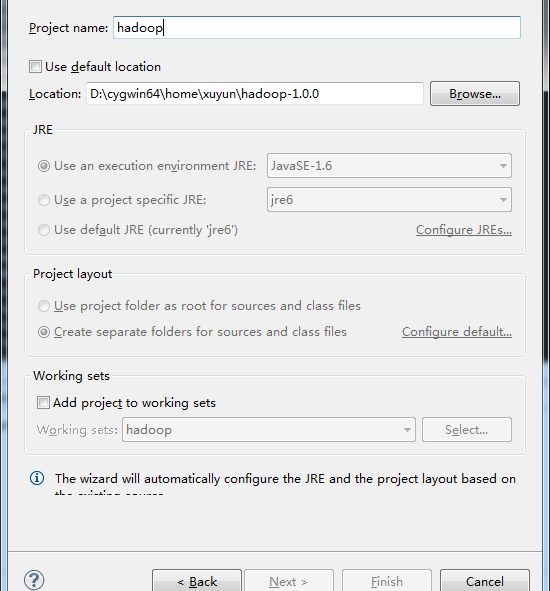
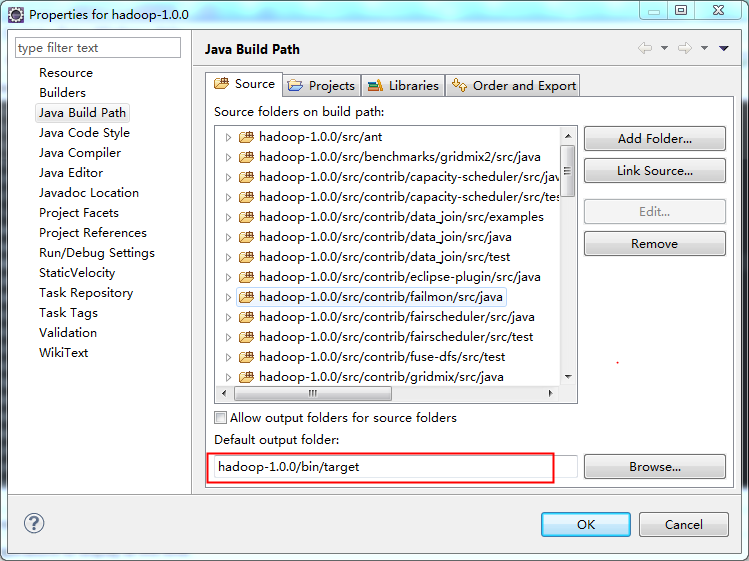
location为解压后的hadoop的目录,点击finish即可完成,工程文件会有一些报错的红叉叉信息,这些可以先不要关注。需要注意的是out folder,如下图所示
hadoop eclipse插件
eclipse插件一般都随着hadoop的发布版本发行,放在contrib文件夹下,可以使用ant自己来进行编译。插件给我们提供了非常便利的hadoop文件操作功能,还有mapReduce job的运行入口。另外也可以网上搜索,下载别人已经编译成功的插件,具体的使用方式可以参考http://www.cnblogs.com/ybc77107/p/3427863.html
word count例子运行
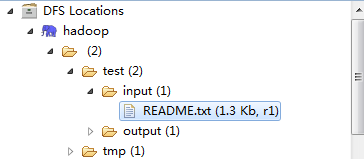
- 点击右键创建两个文件夹 /test/input 和/test/output,然后点击input文件夹的右键,上传准备进行word count的文件,比如Hadoop的README.txt文件。完成后如图所示
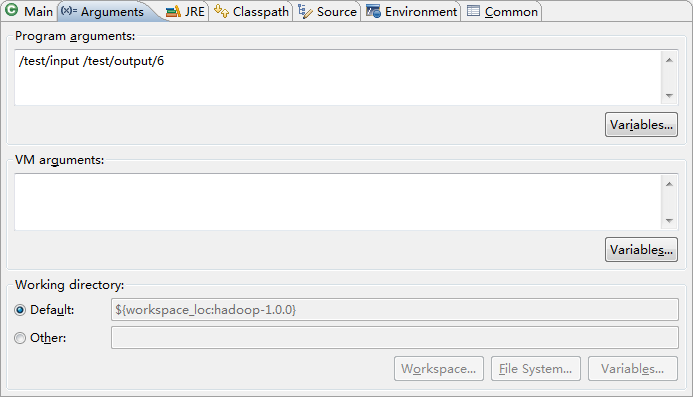
- 找到hadoop工程中的Wordcount.java文件,右键,run as 先进行run配置,配置两个参数为
-
run as -> run on hadoop ,即可。此时会报
2014-04-13 18:19:02,294 ERROR security.UserGroupInformation (UserGroupInformation.java:doAs(1086)) - PriviledgedActionException as:xuyun cause:java.io.IOException: Failed to set permissions of path: mphadoop-xuyunmapredstagingxuyun-1010675368.staging to 0700 Exception in thread "main" java.io.IOException: Failed to set permissions of path: mphadoop-xuyunmapredstagingxuyun-1010675368.staging to 0700 at org.apache.hadoop.fs.FileUtil.checkReturnValue(FileUtil.java:683) at org.apache.hadoop.fs.FileUtil.setPermission(FileUtil.java:655) at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:509) at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:344) at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:189) at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:116) at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:856) at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:1) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Unknown Source) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1083) at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:850) at org.apache.hadoop.mapreduce.Job.submit(Job.java:465) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:495) at org.apache.hadoop.examples.WordCount.main(WordCount.java:67)
此错误真实无处不在啊,由于我们是在工程环境下运行的,因此打开文件FileUtil.java,找到
private static void checkReturnValue(boolean rv, File p,
FsPermission permission
) throws IOException {
if (!rv) {
throw new IOException("Failed to set permissions of path: " + p +
" to " +
String.format("%04o", permission.toShort()));
}
}
将异常捕捉,修改成,这个和前面的HADOOP-7682 BUG一样,只不过是一种相对偷懒的解决方案。
private static void checkReturnValue(boolean rv, File p,
FsPermission permission
) throws IOException {
try {
if (!rv) {
throw new IOException("Failed to set permissions of path: " + p +
" to " +
String.format("%04o", permission.toShort()));
}
} catch (Exception e) {
// TODO: handle exception
}
}
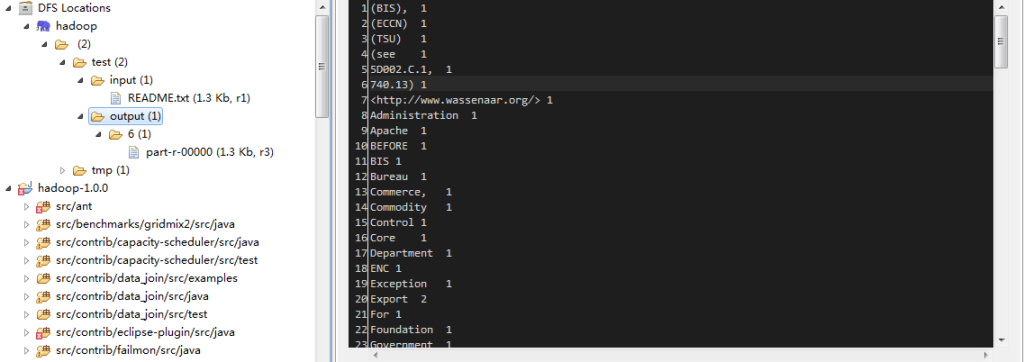
运行结束后,你可以看到output/6中的结果
总结
hadop 在windows cygwin的部署和例子运行就介绍到这里,接下里进行享受你的hadoop之旅吧。去发现数据的更大价值,期望更加便利我们的生活。