ORM简介
对象关系映射(Object Relational Mapping,简称 ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术。简单的说,ORM 是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系数据库中,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的工作量,不需要面对因数据库变更而导致的无效劳动。

sql中的表
CREATE TABLE employee(
id INT PRIMARY KEY auto_increment ,
name VARCHAR (20),
gender BIT default 1,
birthday DATA ,
department VARCHAR (20),
salary DECIMAL (8,2) unsigned,
);
添加一条表纪录:
INSERT employee(name, gender, birthday, salary, department)
VALUES("alex", 1, "1985-12-12", 8000, "保洁部");
查询一条表纪录:
SELECT * FROM employee WHERE age=24;
更新一条表纪录:
UPDATE employee SET birthday="1989-10-24" WHERE id=1;
删除一条表纪录:
DELETE FROM employee WHERE name="alex"
# python的类
class Employee(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
gender = models.BooleanField()
birthday = models.DateField()
department = models.CharField(max_length=32)
salary = models.DecimalField(max_digits=8,decimal_places=2)
# 添加一条表纪录:
emp=Employee(name="alex",gender=True,birthday="1985-12-12",epartment="保洁部")
emp.save()
# 查询一条表纪录:
Employee.objects.filter(age=24)
# 更新一条表纪录:
Employee.objects.filter(id=1).update(birthday="1989-10-24")
# 删除一条表纪录:
Employee.objects.filter(name="alex").delete()
类 —— 表
类属性 —— 表字段
类对象 —— 表记录
单表操作
创建表
创建模型
创建名为 app01 的 app,在 app01 下的 models.py 中创建模型
class Book(models.Model):
nid = models.AutoField(primary_key=True)
title = models.CharField(max_length=20)
price = models.DecimalField(max_digits=5, decimal_places=2)
pub_data = models.DateTimeField()
publish = models.CharField(max_length=32)
字段和参数
每个字段有一些特有的参数,例如,CharField 需要 max_length 参数来指定数据库字段的大小。还有一些适用于所有字段的通用参数。 这些参数在文档中有详细定义,这里只简单介绍一些最常用的:
AutoField
- int自增列,必须填入参数 primary_key=True
BooleanField
- 布尔值类型
CharField
- 字符类型,必须提供 max_length 参数,max_length表示字符长度
TextField
- 文本类型
EmailField
- Django Admin 以及 ModelForm 中提供验证机制
ImageField
- 字符串,路径保存在数据库,文件上传到指定目录
- 参数:
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage
width_field=None 上传图片的高度保存的数据库字段名(字符串)
height_field=None 上传图片的宽度保存的数据库字段名(字符串)
DateTimeField
- 日期+时间格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ]
DateField
- 日期格式 YYYY-MM-DD
TimeField
- 时间格式 HH:MM[:ss[.uuuuuu]]
FloatField
- 浮点型
DecimalField
- 10进制小数
- 参数:
max_digits 小数总长度
decimal_places 小数位长度
1、null
如果为True,Django 将用NULL 来在数据库中存储空值。 默认值是 False.
2、blank
如果为True,该字段允许不填。默认为False。
要注意,这与 null 不同。null纯粹是数据库范畴的,而 blank 是数据验证范畴的。
如果一个字段的blank=True,表单的验证将允许该字段是空值。如果字段的blank=False,该字段就是必填的。
3、default
字段的默认值。可以是一个值或者可调用对象。如果可调用 ,每有新对象被创建它都会被调用。
4、primary_key
如果为True,那么这个字段就是模型的主键。如果没有指定任何一个字段的 primary_key=True,
Django就会自动添加一个 IntegerField 字段做为主键,
所以除非想覆盖默认的主键行为,否则没必要设置任何一个字段的primary_key=True。
5、unique
如果该值设置为 True, 这个数据字段的值在整张表中必须是唯一的
6、choices
由二元组组成的一个可迭代对象(例如,列表或元组),用来给字段提供选择项。 如果设置了choices ,默认的表单将是一个选择框而不是标准的文本框,而且这个选择框的选项就是choices中的选项。
settings 配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'bms', # 要连接的数据库,连接前需要创建好
'USER': 'root', # 连接数据库的用户名
'PASSWORD': '000000', # 连接数据库的密码
'HOST': '127.0.0.1', # 连接主机,默认本级
'PORT': 3306, # 端口 默认3306
}
}
注意一:NAME 即数据库的名字,在 mysql 连接前该数据库必须已经创建,而上面的 sqlite 数据库下的 db.sqlite3 则是项目自动创建。 USER 和 PASSWORD 分别是数据库的用户名和密码。设置完后,在启动 Django 项目前,需要激活 mysql。然后启动项目,会报错:no module named MySQLdb 。这是因为 django 默认导入的驱动是 MySQLdb,可是 MySQLdb 对于 Python3 有很大问题,因此使用驱动 PyMySQL。所以,需要找到项目名文件下的 __init__.py ,在里面写入:
import pymysql
pymysql.install_as_MySQLdb()
注意二:确保配置文件中的 INSTALLED_APPS 中写入了创建的 app 名称
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01',
]
数据库迁移
django 会把 settings 中的 INSTALLED_APPS 的每一个应用中 models 对应的类创建成数据库中的表,在当前环境的项目目录下执行两个命令:
python manage.py makemigrations
python manage.py migrate
添加表记录
方式一
# create方法的返回值book_obj就是插入Book表中的这本书的记录对象
book_obj = Book.objects.create(title="图解HTTP", price=49, pub_date="2014-11-12", publish="人民邮电出版社")
方式二
book_obj = Book(title="图解HTTP", price=49, pub_date="2014-11-12", publish="人民邮电出版社")
book_obj.save()
查询表记录
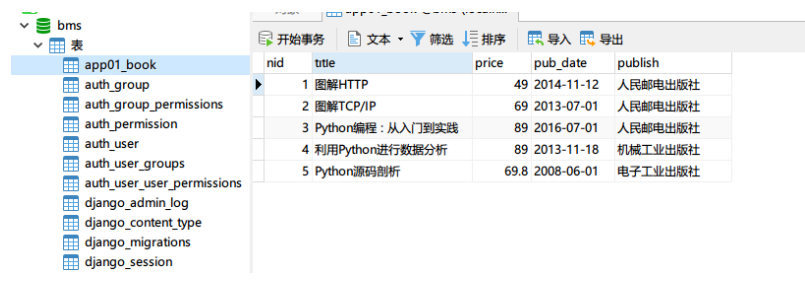
为了方便查询,在此之前已添加多条记录
查询API
all() 查询所有结果
filter(**kwargs) 它包含了与所给筛选条件相匹配的对象
get(**kwargs) 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。
exclude(**kwargs) 它包含了与所给筛选条件不匹配的对象
order_by(*field) 对查询结果排序
reverse() 对查询结果反向排序
count() 返回数据库中匹配查询(QuerySet)的对象数量。
first() 返回第一条记录
last() 返回最后一条记录
exists() 如果QuerySet包含数据,就返回True,否则返回False
values(*field) 返回一个ValueQuerySet,一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列
values_list(*field) 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
distinct() 从返回结果中剔除重复纪录
def addbook(request):
# 添加表记录
# book = Book.objects.create(title="图解HTTP", price=49, pub_date="2014-11-12", publish="人民邮电出版社")
# 查询表记录
# 1、all:返回一个QuerySet对象
# book_list = Book.objects.all()
# print(book_list[0].title) # 图解HTTP
# print(book_list) # <QuerySet [<Book: Book object>]>
# 查询所有书籍名
# for obj in book_list:
# print(obj.title)
# 2、first/last:调用者是QuerySet对象,返回值是对象
# book = Book.objects.all().first()
# book_2 = Book.objects.all().last()
# print(book)
# print(book2)
# 3、filter:返回值是QuerySet对象(相当于where语句),可以加多个过滤条件
# book = Book.objects.filter(title='图解TCP/IP').first()
# print(book)
# 4、get:有且只有一个查询结果才有意义,返回值是一个对象
# 没有这个查询结果会报错
# book = Book.objects.get(title='Python源码剖析')
# print(book)
# 5、exclude:除了查询之外的,返回值也是QuerySet
# ret = Book.objects.exclude(title='图解HTTP')
# print(ret)
# 6、order_by:默认升序,加个-就是降序。可以有多个过滤条件,调用者是QuerySet,返回值也是QuerySet
# book_list = Book.objects.all().order_by('nid')
# book_list_2 = Book.objects.all().order_by('-id', 'price')
# print(book_list)
# 7、count:调用者是QuerySet,返回值是int
# ret = Book.objects.all().count()
# print(ret)
# 8、exists:判断是是否有值,不能传参数
# ret = Book.objects.all().exists()
# print(ret)
# 9、values:调用是QuerySet,返回值也是QuerySet
# ret = Book.objects.values('price')
# print(ret)
# 10、value_list:调用是QuerySet,返回值也是QuerySet
# ret = Book.objects.all().values_list('price', 'title')
# print(ret)
# 11、distinct:调用是QuerySet,返回值也是QuerySet
# ret = Book.objects.all().values('title').distinct()
# print(ret)
return HttpResponse('OK')
双下划线模糊查询
# 查询价格大于50的书的名字
# ret = Book.objects.filter(price__gt=50).values('title')
# print(ret)
# 查询大于40小于50的书
# ret = Book.objects.filter(price__gt=40, price__lt=50)
# print(ret)
# 查询以“图解”开头的书的名字
# ret = Book.objects.filter(title__startswith='图解').values('title')
# print(ret)
# 查询包含‘Python’的书
# ret = Book.objects.filter(title__contains='Python').values('title')
# print(ret)
# icontains 不区分大小写
# 价格在69,89,100中的
# ret = Book.objects.filter(price__in=[69, 89, 100]).values('title')
# print(ret)
# 出版日期在2016年的
# ret = Book.objects.filter(pub_date__year=2016)
# print(ret)
删除表记录
删除方法就是 delete,它运行时立即删除对象而不返回任何值。例如:
model_obj.delete()
也可以一次性删除多个对象。每个 QuerySet 都有一个 delete() 方法,它一次性删除 QuerySet 中所有的对象。例如,下面的代码将删除 pub_date 是 2005 年的 Entry 对象:
Entry.objects.filter(pub_date__year=2005).delete()
在 Django 删除对象时,会模仿 SQL 约束 ON DELETE CASCADE 的行为,换句话说,删除一个对象时也会删除与它相关联的外键对象。例如:
b = Blog.objects.get(pk=1)
# This will delete the Blog and all of its Entry objects.
b.delete()
要注意的是: delete() 方法是 QuerySet 上的方法,但并不适用于 Manager 本身。这是一种保护机制,是为了避免意外地调用 Entry.objects.delete() 方法导致所有的记录被误删除。如果确认要删除所有的对象,那么必须显式地调用:
Entry.objects.all().delete()
如果不想级联删除,可以设置为:
pubHouse = models.ForeignKey(to='Publisher', on_delete=models.SET_NULL, blank=True, null=True)
修改表记录
Book.objects.filter(title__startswith="Py").update(price=120)
此外,update 方法对于任何结果集(QuerySet)均有效,这意味着可以同时更新多条记录 update 方法会返回一个整型数值,表示受影响的记录条数。
在Python脚本中调用Django环境
import os
if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "untitled15.settings")
import django
django.setup()
from app01 import models
books = models.Book.objects.all()
print(books)
Django终端打印SQL语句
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}