Redis整体面貌
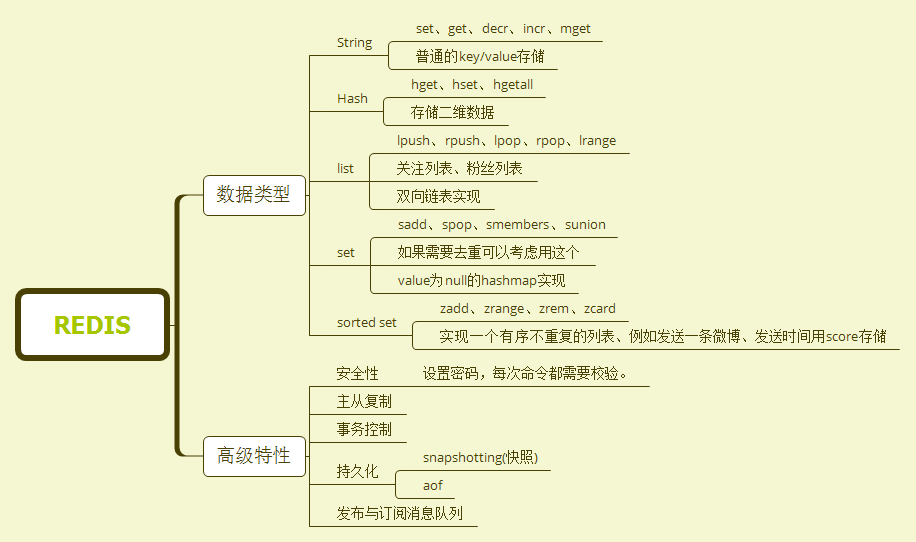
Redis基本数据结构
1、String
1.1 数据结构
long len byte数组长度
long free 可用数组长度
char buff[] 数据内容
1.2 命令
键值:设置值通过字符串名
set:设置键值
setnx(set not exist):设置键值|若键不存在则可以存,否则返回0.
setex(set expire):设置键值(含过期时间),set key seconeds value
setrange:设置指定位置key的键值 例如setrange name diaodiao 2 haha-->dihahaao 从第二个位置开始替换
mset:设置多个键值
msetnx:设置多个不存在的键值
get:通过键获得值
getset:先通过键获得值,再设置值。
getrange(0~-1):获取指定范围的字符。范围|从左往右数从0开始 从右往左数-1开始。例如hello(0~4|-5~-1)
mget:获得多个键的值。
数字类型相关操作
set age </span>10<span style="color: #000000;">(以下操作都是针对10操作)
incr 递增1 incr age</span>-->11<span style="color: #000000;">
incrby 递增指定数字</span>-->incr age 5->16<span style="color: #000000;">
decr 递减1
decrby 递减指定值
字符属性操作
set name </span>"hello"<span style="color: #000000;">
append:在尾部追加字符串 append name </span>"Diaodiao"-><span style="color: #000000;">helloDiaodiao
strlen: 获得字符串长度 strlen name </span>->5
2、hashes(存储键值对,类似于hashmap)
2.1 配置(redis.conf配置文件中)
默认:hash-max-zipmap-entries 配置字段最多64个(key的个数)
hash-max-zipmap-value 配置value最大为512字节
2.2 命令(参考String)
hset key field value
hset:若key不存在就创建,否则覆盖。
hsetnx:设置 hash field 为指定值,如果 key 不存在,则先创建。如果 field 已经存在,返回 0,nx 是not exist 的意思。
hmset:同时设置hash多个field
hget:获取指定的hash field
hmget:获取全部指定的hash field
hexists:测试指定field是否存在
hlen:返回指定的field的个数
hdel:删除指定field。
hkeys:查询指定key的所有field
hvals:获取指定key的所有value
hgetall:获得指定key的所有field以及值
3、lists
3.1 简介
list是基于双向链表的数据结构,操作就是入栈(push)、出栈(pop),包括左(头)入出栈、右(尾)入出栈,也含有超时阻塞的功能。
3.2 命令
lpush:在key对应的list的头部添加元素。
lrange:获得list范围的值。 lrange mylist start(0) stop(2)(获取0 1 2索引的值)
rpush:在key对应的list的尾部添加元素
linsert:在key对应的特定位置之前或者之后添加字符串元素 linsert mylist before “world” “hello”
lset:设置list指定下表的元素(从0开始)
lrem:从key对应的list里,删除count个value相同的元素。
ltrim:保留指定key的值范围内的数据。
lpop:从list的头部删除元素,并且返回删除元素
rpop:从list的尾部删除元素,并且返回删除元素
rpoplpush:第一个list的尾部移除元素并且添加到第二个list的头部
lindex:返回名称为key的list中index位置的元素
llen:返回key对应list的长度
4、sets
4.1 简介
sets是无序集合,是通过hashtable实现的。额外功能有并集、交集、差集。
4.2 命令
sadd:向名称为key的set当中添加元素
srem:删除名称为key的元素
spop:随机返回并且删除set中某key元素
sdiff:两个set的差集
sdiffstore:假设有set3、set1、set2-->set1与set2差集返回的元素,添加到set3中
sinter:两个set的交集
sinterstore:假设有set3、set1、set2-->set1与set2交集返回的元素,添加到set3中
sunion:两个set的并集
sunionstore:假设有set3、set1、set2-->set1与set2交集返回的元素,添加到set3中
smove:假设有set1、set2-->删除set1的某个key值,并且添加到set2
scard:返回set的元素个数
sismember:测试set中是否存在某member(元素)。
srandmember:随机返回一个元素,但是不删除
5、sorted set
5.1 简介
sorted set(skip list|双向链表和hashtable的结合体)是set的一个升级版本,升级版本的sets,有两个纬度,一个纬度用来存顺序,一个纬度用于存value。
5.2 命令
zadd:向名称为key的zset中添加元素member、score用于排序。如果该元素存在,则根据score更新该元素的顺序
zrem:删除名为key的zset的元素member
zincrby:如果在名称为 key 的 zset 中已经存在元素 member,则该元素的 score 增加 increment;否则向集合中添加该元素,其 score 的值为 increment
zrank:返回名称为 key 的 zset 中 member 元素的排名(按 score 从小到大排序)即下标
zrevrank:返回名称为 key 的 zset 中 member 元素的排名(按 score 从大到小排序)即下标
zrange:返回名称为 key 的 zset(按 score 从小到大排序)中的 index 从 start 到 end 的所有元素
zrevrange:返回名称为 key 的 zset(按 score 从大到小排序)中的 index 从 start 到 end 的所有元素
zrangebyscore:返回集合中 score 在给定区间的元素
zcount:返回集合中 score 在给定区间的数量
zcard:返回集合中元素个数
zscore:返回给定元素对应的 score
zremrangebyrank:删除集合中排名在给定区间的元素
zremrangebytscore:删除集合中 score 在给定区间的元素
Redis常用命令
1、键值相关命令
keys *|key*|key???
exists key:确认一个 key 是否存在
del key:删除一个 key
expire key seconeds:设置一个 key 的过期时间(单位:秒)
move:将当前数据库中的 key 转移到其它数据库中。
persist:移除给定 key 的过期时间
ttl:查看过期还需要多长时间
randomkey:随机返回命名空间的一个key
renamekey:重命名key
type:返回值类型
</span>2<span style="color: #000000;">、元务器相关命令
ping:测试连接是否存活
echo:在命令行打印一些内容
select:选择数据库。Redis 数据库编号从 </span>0~15<span style="color: #000000;">,我们可以选择任意一个数据库来进行数据的存取。
quit:退出连接。
dbsize:返回当前数据库中 key 的数目。
info:获取服务器的信息和统计。
monitor:实时转储收到的请求。
config:获取服务器配置信息。
flushdb:删除当前选择数据库中的所有 key。
flushall:删除所有数据库中的所有 key。</span></span></pre>
Redis高级使用属性
1、安全性:设置每次命令之前都要确认密码|在redis.conf配置文件中修改 requirepass
2、主从复制
2.1 特点
(1)master可以拥有多个slave
(2)多个slave可以连接同一个master外,还可以连接其他slave
(3)主从复制不会阻塞master,同步数据,master可以继续处理client。
(4)提高系统的伸缩性
2.2、搭建过程
参考:http://www.cnblogs.com/qiuyong/p/6705689.html
3、事务控制
3.1 简单事务控制
multi-->事务begin
exec-->退出提交
3.2 事务回滚
muliti-->事务begin
discard-->事务回滚
4、持久化
4.1 snapshotting(默认)-快照方式
将数据以快照的方式写入到二进制文件中,也是dump.rpb。执行save、bgsave的时候会对dump.rpb
保存方式
save:手动存储、阻塞当前线程,把内存数据存到dump.rpb中。
bgsave:开启子线程、调用fork操作,后台将内存数据存到dump.rpb中。
redis.conf中默认设置为自动bgsave。
缺陷:
假设有client1、client2.
client1执行flushall、把内存数据全部清除。
client2执行的时候,因为之前数据在未知情况下被清除,这样就会造成很大的麻烦。
通常情况下,我们先把save之前,把相应dump.rpb转移到其他目录下进行保存,利于数据恢复。
4.2 aof(append-only file)-->如果应用要求不能丢失任何修改的话,可以采用 aof 持久化方式
机制:默认每隔一秒,redis会收到写命令,把内容追加到appendonnly.aof文件中。
配置redis.conf
appendonly yes //启用 aof 持久化方式
# appendfsync always //收到写命令就立即写入磁盘,最慢,但是保证完全的持久化
appendfsync everysec //每秒钟写入磁盘一次,在性能和持久化方面做了很好的折中
# appendfsync no //完全依赖 os,性能最好,持久化没保证
5、发布及订阅消息
5.1 订阅者 subscribe 通道(频道)例如tv1/tv2/tv3 psubscribe tv*例如tv开头的消息都能收到
5.2 发送者 publish tv1 message
5.3 退出订阅模式:unsubscribe、unpsubscribe
6、Pipeline 批量发送请求
1、普通方式
基于tcp的连接方式,每次都要等着回复才能执行
2、Pipeline方式
多个命令执行完以后,然后把执行结构返回给客户端。
7、虚拟内存相关配置
vm-enabled yes #开启 vm 功能
vm-swap-file /tmp/redis.swap #交换出来的 value 保存的文件路径
vm-max-memory 1000000 #redis 使用的最大内存上限
vm-page-size 32 #每个页面的大小 32 个字节
vm-pages 134217728 #最多使用多少页面
vm-max-threads 4 #用于执行 value 对象换入换出的工作线程数量
Redis 持久化磁盘 IO 方式及其带来的问题
1. 根据业务需要选择合适的数据类型,并为不同的应用场景设置相应的紧凑存储参数。
2. 当业务场景不需要数据持久化时,关闭所有的持久化方式可以获得最佳的性能以及最大的内存使用量。
3. 如果需要使用持久化,根据是否可以容忍重启丢失部分数据在快照方式与语句追加方式之间选择其一,不要使用虚拟内存以及 diskstore 方式。
4. 不要让你的 Redis 所在机器物理内存使用超过实际内存总量的3/5。