关系型数据库中,互联网相关行业使用最多的无疑是mysql,虽然我们C# Developer很多用的都是sql server ,但是学习一些mysql方面的知识也是必要的,他山之石么。
先上一个explain的实例,以下我会通过我自己的理解,逐个解释表中每列的含义。(上图仅供示例使用,实际项目不建议如此写sql)。
id
这个字段是用来确定查询语句执行的优先级的。
这个值会有三种情况:
id值相同:这种情况意味着查询语句按照explain结果中的id自上而下执行
id值不相同:这种情况下,id值会自递增,id值越大,explain结果中的相应sql语句被执行的优先级越高,越先被执行。这通常会在子查询中出现
id值存在相同的和不同的值:这种情况下,id值越大,优先级越高,越先被执行,那么,对于id值相同的结果,mysql会按照explain结果中的id自上而下执行。
select_type
表示查询的类型,先看表

PRIMARY:查询中若包含若干子查询或者嵌套查询,那么最外层的查询将被标记为PRIMARY.
SUBQUERY:在select或where语句中包含子查询
DERIVED:在from列表中包含的子查询将被标记为DERIVED(衍生),MySQL会递归执行这些子查询,将结果放在临时表中。
table
对应行正在访问哪一个表,表名或者别名,有可能是一下几种
1 实际的表名
2 表的别名
比如 select * from customer as c
3 derived 子查询
<derivedx>, x是个数字,我的理解是第几步执行的结果
4 null 直接结算的结果,不走表
关联优化器会为查询选择关联顺序,左侧深度优先
当from中有子查询的时候,表名是derivedN的形式,N指向子查询,也就是explain结果中的下一列
当有union result的时候,表名是union 1,2等的形式,1,2表示参与union的query id
注意:MySQL对待这些表和普通表一样,但是这些“临时表”是没有任何索引的。
type:
type显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL ,一般来说,得保证查询至少达到range级别,最好能达到ref。

ref 使用非唯一索引扫描或唯一索引前缀扫描(有时候需要索引很长的字符列,这会让索引变得大且慢。通常可以索引开始的部分字符,这样可以大大节约索引空间,从而提高索引效率),返回单条记录,常出现在关联查询中
eq_ref 类似ref,区别在于使用的是唯一索引,使用主键的关联查询
possible_keys
指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用
该列完全独立于EXPLAIN输出所示的表的次序。这意味着在possible_keys中的某些键实际上不能按生成的表次序使用。
如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查WHERE子句看是否它引用某些列或适合索引的列来提高你的查询性能。如果是这样,创造一个适当的索引并且再次用EXPLAIN检查查询
key
显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL。要想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用FORCE INDEX、USE INDEX或者IGNORE INDEX。
key_len
key_len列显示MySQL决定使用的键长度。如果键是NULL,则长度为NULL。使用的索引的长度。在不损失精确性的情况下,长度越短越好 。
表示查询优化器使用了索引的字节数. 这个字段可以评估组合索引是否完全被使用, 或只有最左部分字段被使用到.
key_len 的计算规则如下:
字符串
char(n): n 字节长度
varchar(n): 如果是 utf8 编码, 则是 3 n + 2字节; 如果是 utf8mb4 编码, 则是 4 n + 2 字节.
数值类型:
TINYINT: 1字节
SMALLINT: 2字节
MEDIUMINT: 3字节
INT: 4字节
BIGINT: 8字节
时间类型
DATE: 3字节
TIMESTAMP: 4字节
DATETIME: 8字节
字段属性: NULL 属性 占用一个字节. 如果一个字段是 NOT NULL 的, 则没有此属性.
我们来举两个简单的栗子:
mysql> EXPLAIN SELECT * FROM order_info WHERE user_id < 3 AND product_name = 'p1' AND productor = 'WHH' G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: order_info partitions: NULL type: range possible_keys: user_product_detail_index key: user_product_detail_index key_len: 9 ref: NULL rows: 5 filtered: 11.11 Extra: Using where; Using index 1 row in set, 1 warning (0.00 sec)
上面的例子是从表 order_info 中查询指定的内容, 而我们从此表的建表语句中可以知道, 表 order_info 有一个联合索引:
KEY `user_product_detail_index` (`user_id`, `product_name`, `productor`)
不过此查询语句 WHERE user_id < 3 AND product_name = 'p1' AND productor = 'WHH' 中, 因为先进行 user_id 的范围查询, 而根据 最左前缀匹配 原则, 当遇到范围查询时, 就停止索引的匹配, 因此实际上我们使用到的索引的字段只有 user_id, 因此在 EXPLAIN 中, 显示的 key_len 为 9. 因为 user_id 字段是 BIGINT, 占用 8 字节, 而 NULL 属性占用一个字节, 因此总共是 9 个字节. 若我们将user_id 字段改为 BIGINT(20) NOT NULL DEFAULT '0', 则 key_length 应该是8.
上面因为 最左前缀匹配 原则, 我们的查询仅仅使用到了联合索引的 user_id 字段, 因此效率不算高.
接下来我们来看一下下一个例子:
mysql> EXPLAIN SELECT * FROM order_info WHERE user_id = 1 AND product_name = 'p1' G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: order_info partitions: NULL type: ref possible_keys: user_product_detail_index key: user_product_detail_index key_len: 161 ref: const,const rows: 2 filtered: 100.00 Extra: Using index 1 row in set, 1 warning (0.00 sec)
这次的查询中, 我们没有使用到范围查询, key_len 的值为 161. 为什么呢? 因为我们的查询条件 WHERE user_id = 1 AND product_name = 'p1' 中, 仅仅使用到了联合索引中的前两个字段, 因此 keyLen(user_id) + keyLen(product_name) = 9 + 50 * 3 + 2 = 161
rows
rows 也是一个重要的字段. MySQL 查询优化器根据统计信息, 估算 SQL 要查找到结果集需要扫描读取的数据行数.
这个值非常直观显示 SQL 的效率好坏, 原则上 rows 越少越好.
Extra
EXplain 中的很多额外的信息会在 Extra 字段显示, 常见的有以下几种内容:
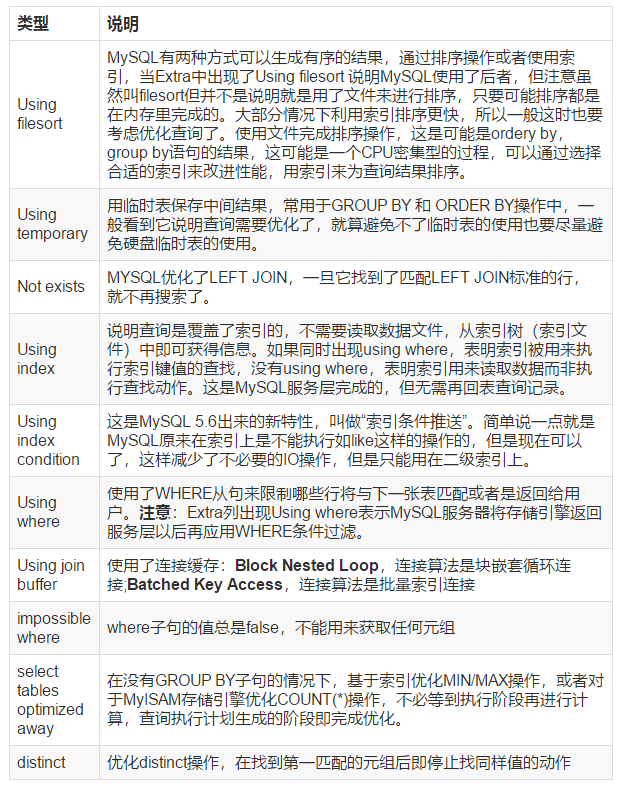
Using join buffer:改值强调了在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果。如果出现了这个值,那应该注意,根据查询的具体情况可能需要添加索引来改进能。
总结:
• EXPLAIN不会告诉你关于触发器、存储过程的信息或用户自定义函数对查询的影响情况
• EXPLAIN不考虑各种Cache
• EXPLAIN不能显示MySQL在执行查询时所作的优化工作
• 部分统计信息是估算的,并非精确值
• EXPALIN只能解释SELECT操作,其他操作要重写为SELECT后查看执行计划。
filtered:表示示此查询条件所过滤的数据的百分比