配置完spark之后,使用spark实现wordcount,这一部分完全参考《深入理解Spark:核心思想与源码分析》
依然使用hadoop wordcountTest的那几个txt文件
进入spark的bin目录,打开spark-shell
spark-shell
在打开的scala命令行中依次输入以下几个语句:
val lines = sc.textFile("/home/hadoop/scala-2.11.5/wordcountText/*.txt", 2)
val words = lines.flatMap(line => line.split(" "))
val ones = words.map(w => (w,1))
val counts = ones.reduceByKey(_+_)
counts.foreach(println)
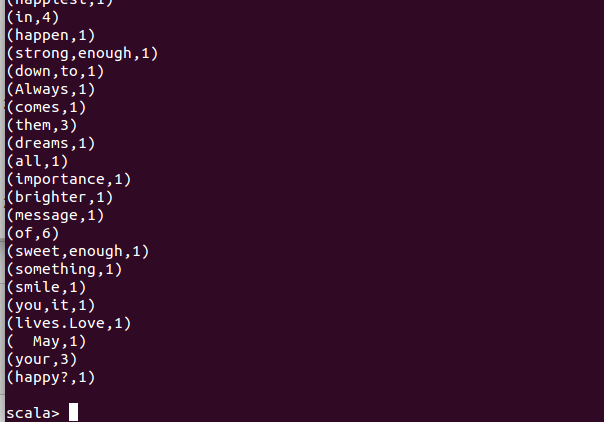
部分wordcount输出结果,可以发现,spark默认的单词计数是乱序的: